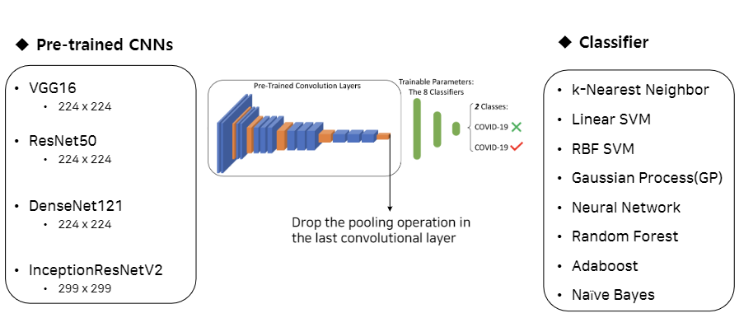
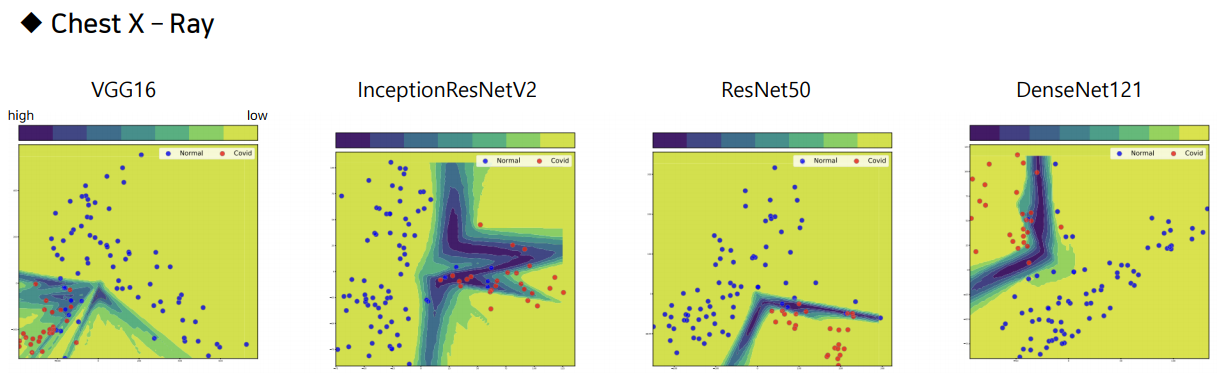
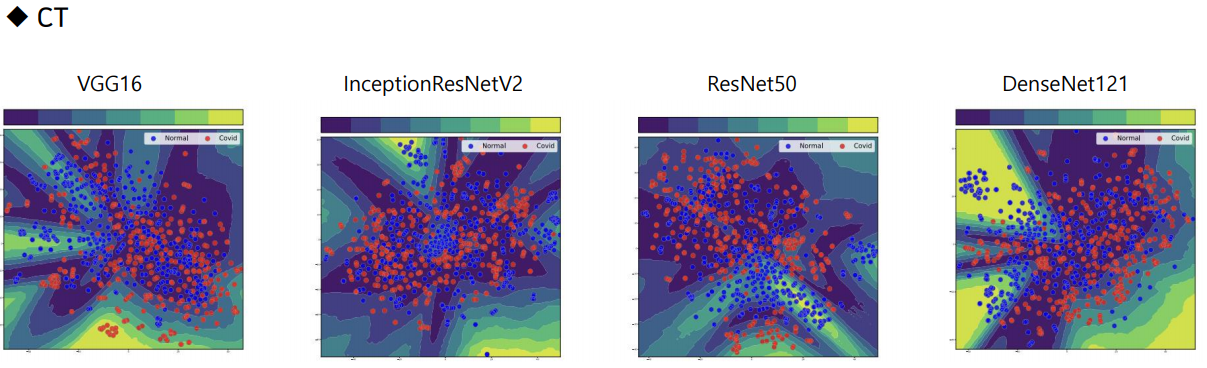
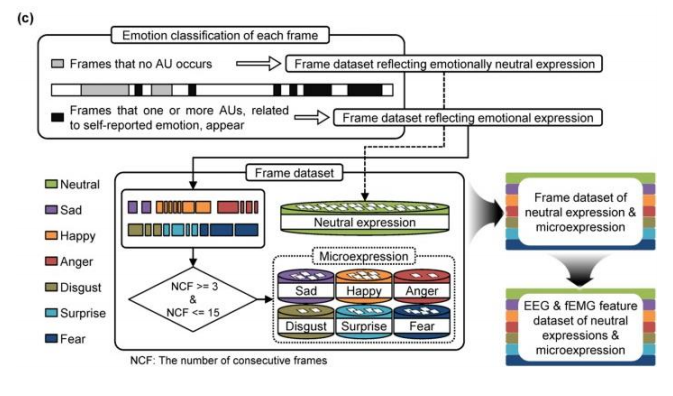
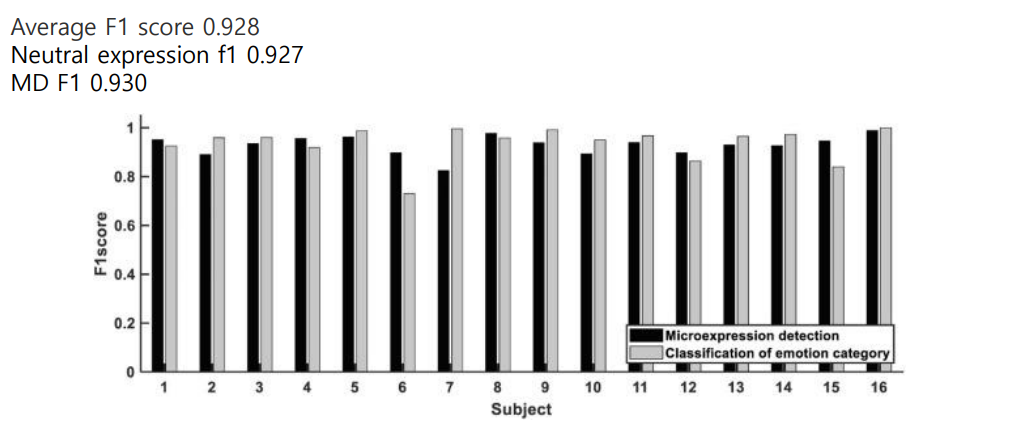
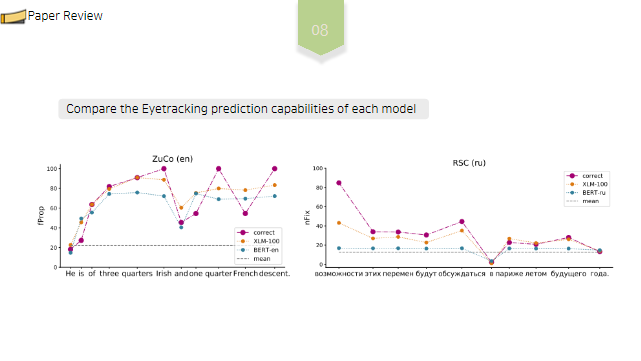
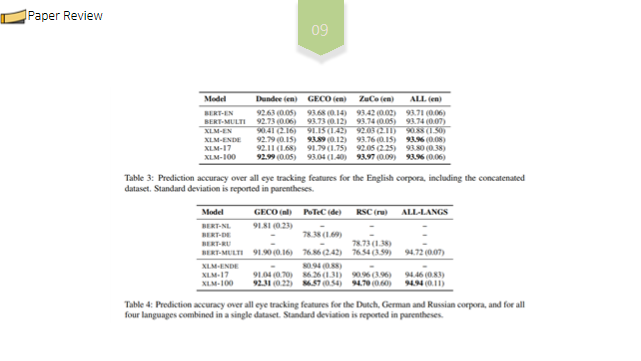
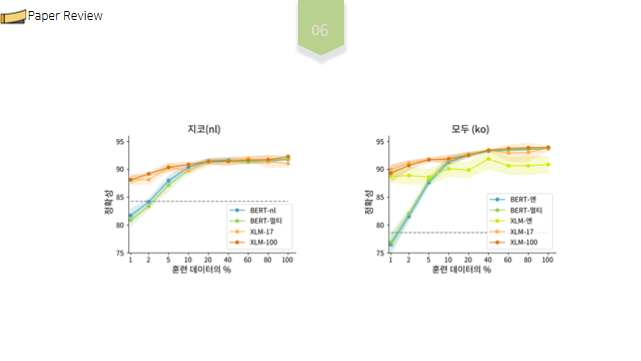
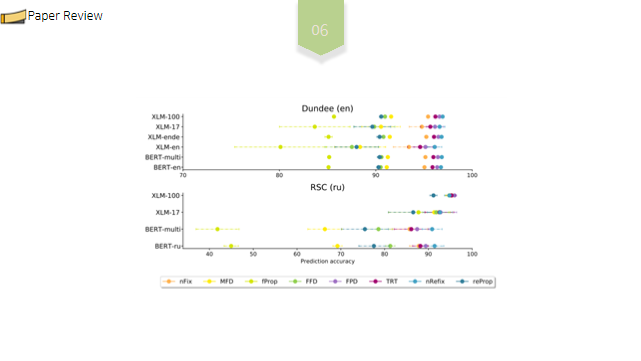
저번학기 미국 연구인턴 갔을때 1저자로 작성했던 논문!! IEEE International Conference 에 냈었는데 Accept 됐다.!

우리 논문은 Proceedings 에 publish 될 예정이고 나는 7월 중순에 그리스 아테네로 Oral Presentation 을 하러 갈 예정이다. (짝짝짝)
다행히 학회 등록비, 숙박비는 미국 대학 측에서, 항공료는 경희대 측에서 지원해준다고 해서 나는 식비랑 여가비만 들고 간다. 학회 구경, 그리고 그리스 구경 재미있게 하고 와야지!
암튼 그래서 이것저것 준비할 것들이 많다.. Review Revision 도 해야되고..
졸논2개준비하면서 학회갈준비하면서 학점챙기면서 어학공부할라니까 진짜 너무피곤하다. 시간이 너무 없다.
이건 좀 아닌 것 같다...
오늘도 오랜만에 친구들 만나기로했는데 못간다하고 도서관왔다. 해야할일을 쳐낼려면 어쩔 수 없다...
최근에는 좀 정신을 차리고 열심히 사는 중이다. 미국에서 돌아오자마자 이렇게 살았어야 했는데.
돌아오고 나서 겨울방학동안은 진짜 아무것도 안하고 빈둥대며 살았고,, 학기 초에도 최소한의 것들만 하면서 대충 살았는데.. 너무 후회가 된다!!!!
도서관에 있으니 마음이 편해져서 좋다.
최근에 푹 빠진 노래는 세븐틴의 손오공 이다. 노래 가사랑 안무가 너무 맘에들고 멋있고 중독적이다..
한마디로 내취향저격
세븐틴이 누군지는 모르지만.. 매일 듣고있다. 아마 앞으로도 쭉 내 최애 노래일듯??
암튼,, 앞으로도 파이팅,,, 하루하루 잘 준비해서 목표를 이뤄야겠다.
아래는 기록용으로 막 적음
김하일
case1)
24살 - 4학년
25-26살 카이스트석사(바뇌)
27살~31살 카이or미국 공학박사
32살 학업끝.. 이제포닥???
case2)
24살 - 4학년
25-26살 카이스트석사(바뇌)
27살~34살 의사+공학박사 =의사과학자/의사공학자
35살 학업끝.. 이제포닥???
의과학자/의공학자 가 될수도 있겠고 의사과학자/의사공학자가 될 수도 있겠다
미국으로간다면 아마 전자 카이스트에 남는다면 후자.
의석박통) 31살 의과학박사
공석미박) 27살 석사 32 의과학박사
공석의박) 35살 의사+공학박사
의사과학자/의과학자 (의사공학자/의공학자)
- 계산 뇌과학/신경과학, 생물정보학
좀 더 내가 하고싶은 분야를 일찍 알았다면.. 더 이른 시기에 관련해서 이것저것 도전해보고 좋은 기회들을 잡을 수 있었을텐데.. 하는 아쉬운 마음은 있지만,
지금도 충분히 어린 나이이고, 세상에 뭔갈 이루기 늦은 나이는 전혀 없으니까.
조급해하지않고 열심히 살아야겠다.
생각해보면 세상에서 뭔갈 이루고자 할 때 방해받을 수 있는 유일한 요소는 자신의 건강 상태이다.
또 하나를 더하자면 주위 인간관계 및 가족의 건강상태..? -> 정신 건강에 크게 영향을 끼칠 수 있는 요소이기 때문
그렇다면 신체적/정신적 건강이라고 할 수 있겠다.
건강 관리를 지금부터 잘 해두어야 겠다. 지금은 밤 새고 운동 안하고 그래도 어려서 쌩쌩하지만
나이가 좀 더 들면 확실히 몸이 힘들다고 하니까... 운동을 좀 해서 체력, 근력을 키워야겠다.
(헬스장 등록되어있는데 너무 바빠서 못가는중... 하... 일찍부터 좀 많이 해둘걸)
그리고 사실 티스토리 블로그 테크닉이나 상세한 프로젝트/논문 설명 등등 공부 목적으로 개설한건데
그렇게 되지가 않네..
일단 그런거 쓸 시간에 뭐라도 하나 더 진전시키는게 나은 상황이라 더 그렇다. 너무 바빠!!
앞으로도 그런 내용은 안쓸거같은 느낌이..ㅋㅋ
당분간은 내 생각, 일상, 계획들을 조용히 써내려가고 다시 마음을 다잡는 용도로 써야겠다.
+ 아 그리고 마침 충북인재양성재단 장학생으로 선발되었당.. 200만원 받았당. 직전 학기 학점이 좋았어서 다행이다.
이런게 있는 줄 알았으면 1학년때부터 신청해보는건데.. 4-2학기에 이런게 있는줄 알았다. 내가 나고 자란 충청북도... 고맙다...!!
이 장학금은 그리스 학회 가는 여비로 유용히 사용할 예정이다. 시기가 딱 적절했던 것 같다.
(22:27 추가)
오늘따라 왜 이렇게 서글픈지 모르겠다.
속상하고 울고싶은데 뭐때문인지 모르겠고 그냥 이래저래..
많은게 불안하고 스스로에게 실망스럽고 두렵고 외롭고 쓸쓸하고..
비가와서 싱숭생숭한가보다.
이런 이야기를 할 사람이, 할 공간이 여기 내 블로그밖에 없다는 것도 슬프다. 나를 알아줄 사람이 한 명만 있었으면 좋을텐데
심란한 마음을 털어놓았더니 토닥여줄 사람이 한명만 있으면 힘이 날텐데
속마음 터놓을 사람없이 혼자 세상을 살아가는건 너무 쓸쓸하다
예전엔 자취해서 좋았는데. 이제는 혼자있기가 싫다
혼자있고싶지않은데 같이있고싶은사람이없다
언젠가 친구로든 연인이든.. 마음을 공유할 수 있는 좋은 인연을 만날 수 있었으면 좋겠다
그나마 블로그에 혼자 속마음을 나누면서 쓸쓸함을 버티는거같다.
이상하게 속상하고 무섭고 두려운 오늘이다.
'프로젝트·연구 > 프로젝트·연구' 카테고리의 다른 글
| 2022-1학기. 4학년 1학기를 마치며 + 🏆2022-1학기 SW 활동우수 금상 장학생 선정/ 1등상 수상🏆 (0) | 2022.07.12 |
|---|---|
| 🏆2021-2학기 CAPSTONE-DESIGN 경진대회 최우수상 수상 <교내>🏆 (0) | 2022.01.27 |
| 🏆소프트웨어페스티벌 데이터분석부문 상 휩쓸었다! 대상, 우수상 모두 수상 <교내>🏆 (0) | 2021.12.08 |
| [데캡디] 뇌파 기반 사용자 친화 음악 작곡 알고리즘 구현(2. 중간보고 및 발표영상) (0) | 2021.12.08 |
| 🏆A.I.D.D, 최우수상 수상! 2021, AI 당뇨병 발병 예측 데이터톤 참여, 시상식 후기 <전국구 132팀중 최종 2등>🏆 (0) | 2021.11.29 |