
과제 개요
인간의 내면을 음악으로 듣기 위한 시도는 오래전부터 이루어져 왔다. 1930년대 초기에는 뇌파 알파파의 진폭이나 뇌파 신호의 단순하고 직접적인 특징을 통해 ‘소리’를 만들어 왔고, 1990년대에 이 르러서는 디지털 필터링 및 뇌파 데이터의 분석을 통해 다양하고 새로운 ‘음악’ 생성 규칙을 만들어 왔다.
본 연구에서는 기존의 ‘뇌파를 통해 음악을 생성한다’는 목적에서 더 나아가, 뇌파를 통해 사용자 친화적인 음악을 생성하는 것, 즉 ‘사용자의 감정을 잘 표현해주는 음악’을 만드는 것을 목표로 한다. 사용자는 이로써 나를 잘 표현해주는, 진정한 ‘나만의 음악’을 갖게 될 수 있다. 또, 긍정적인 감정을 보여주는 뇌파를 알고리즘에 넣어 만들어진 음악과, 부정적인 감정을 보여주는 뇌파를 이용해 만들어 진 음악의 비교를 통해 우리는 인간의 내면을 한층 더 알아볼 수 있을 것이다.
개발 목표
- EEG 데이터를 통해 감정에 맞는 음악을 작곡하는 알고리즘 모델 개발
- 1에서 구현된 알고리즘을 통해 사용자가 원하는 악기를 사용하여 음악 작곡
개발 과정
0. 뇌파란?
- 뇌의 전기적인 활동을 머리 표면에 부착한 전극에서 측정한 전기 신호
- 주파수 범위에 따라서 델타(0.2Hz ~ 4Hz), 세타(4Hz ~ 8Hz), 알파(8Hz ~ 13Hz), 베타(13Hz ~ 30Hz), 감마(30Hz ~ 45Hz)파로 구분

EEG Data Sample
1. EEG DEAP Dataset
- 32명의 참가자 → 총 40개의 1분 길이의 영상을 3초 정도의 준비시간을 가지고 시청
- Sampling rate를 128Hz로 하여 32개 Channel에서 나오는 뇌파 측정
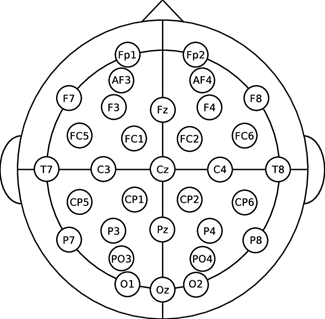
32 Channel
- 영상 시청 후, 자신이 느낀 감정에 대해 각각의 Label 별로 수치를 결정
- Label: 1~9 사이의 실수값으로 정해짐
- Arousal: 감정의 격함의 정도 → 높을 수록 감정이 격해짐
- Valence: 감정의 긍/부정 정도 → 높을 수록 감정의 긍정의 정도가 커짐

Arousal and Valence Label
2. Preprocessing (전처리)
- 첫 3초는 감정 분석에 중요하지 않을 것이라 판단하여 제거
- 비교적 감정이 뚜렷한 데이터만을 사용하여 정확도를 높이고자 3과 7을 기준으로 Arousal Low /High, Valence Low/High의 네가지 카테고리로 Grouping.

4가지 Category로 Grouping
- 기존 선행 연구 결과를 참고해 감정 분석에 주로 사용되는 12개의 채널 선정.
- 긍정적인 감정은 주로 좌측 전두엽, 부정적인 감정은 주로 우측 전두엽과 연관되어 있다는 연구 결과에 따라 pair로 선택
- F3-F4 / F7-F8 / FC1-FC2 / FC5-FC6 / FP1-FP2 / AF3-AF4
3. Feature Extraction
뇌파 데이터를 각각 Time doamin, Frequency domain, Time-Frequency domain의 영역에서 14개의 Feature 추출.
- Time domain
- Statistical feature: Mean, Standard deviation, Kurtosis, Skewness
- Hjorth parameters (Mobility, Complexity)
- Fractal Dimension (Higuchi, Petrosian)
- Detrended Fluctuation Analysis
- Hurst Exponent
- Frequency domain
- Power Spectral Density
- Maximum Power Spectral Frequency
- Root Mean Square
- Time-Frequency Domain
- STFT (Short-Time Fourier Transform)
Time domain과 Frequency domain에서 추출한 총 13개의 Feature는 모델 학습 시에 사용하였고,
Time-Frequency domain 영역에서의 Feature는 음악 작곡 알고리즘의 주요 데이터로 사용.

데이터 전처리 및 Feature Extraction 과정
4. Modeling
앞서 추출한 Time domain과 Frequency domain의 Feature를 이용해, Arousal/Valence 마다 High/Low를 분류하는 이진 분류 모델 생성
- 전체 데이터를 shuffling 한 뒤 train과 test를 8:2로 분리
- Data가 biased되어 있어 oversampling을 통해 train data의 레이블 값(High: 1, Low: 0)의 비율을 맞춰줌

모델링 과정
- 13개의 기계학습 모델에 대해 Train data를 이용하여 10-fold 교차 검증 시행해 정확도 비교
- 가장 높은 성능을 보인 3개의 모델(ExtraTreeClassifier, RandomForestClassifier, LGBMClassifier)을 ensemble
- 최종 결과 Test data에 대해 각 모델 모두 80%의 정확도를 보임.

5. Music Composition Algorithm
1. 훈련된 모델을 통해 예측한 Valence를 통해 Major/Minor 결정
- 12개의 Channel에서 예측된 Label 중 많이 선택된 Label을 선택
- High: Positive → Major
- Low: Negative → Minor

Major/Minor 결정
2. 훈련된 모델을 통해 예측한 Arousal를 통해 Tempo 결정.
- 12개의 Channel에서 예측된 Label의 비율을 통해 Tempo 결정
- High: Excited → Fast Tempo
- Low: Relax → Slow Tempo

Temop 결정
3. frequency domain의 Maximum Power Spectral Frequency (MPSF)로 Key Chord 결정
- 감정을 더 잘 나타낼 수 있도록 beta-gamma 대역대에서 MPSF 추출
- 기본 오른손 주파수 대역대로 Scaling
- 가장 가까운 Chord를 통해 Key chord와 scale 결정

Valence model로 예측한 결과가 High, MPSF Scaling 결과 C chord에 가장 가깝다면, "C Major Scale"을 이용해 작곡
4. Time-frequency domain의 STFT로 Melody 결정
- 1초 단위로 분할
- 각 구간 별 최댓값을 가지는 주파수를 3번의 방법으로 Scaling하여 Key Chord의 Scale에 가장 가까운 음을 결정
- Melody 간격이 너무 넓은 경우, 기존의 박자보다 더 작은 박자로 Interpolation하여 자연스러운 Melody 구성
- 좀 더 풍부한 음악을 위해, 왼손은 오른손에서 Octave를 2단계 내린 1도 화음을 치게 해 반주 구성
GUI (Graphic User Interface)
- 박스 안에 EEG Signal Drag and drop
- "1. Extract Feature" 버튼을 눌러 12개의 Channel에 대해 총 14개의 Feature를 추출
- "2. Emotion Analysis" 버튼을 눌러 Arousal과 Valence 예측
- 사용자가 원하는 악기를 선택하고, "3. Convert Signal to Music"버튼을 눌러 2와 3에서 추출한 feature와 예측된 결과를 이용해 음악 작곡
- 작곡된 음악은 어플리케이션이 저장된 경로의 music 폴더에 저장됨
- "4. Reset" 버튼을 눌러 초기화 한 뒤, 다른 EEG Signal에 대해 1~5번 순서를 반복하여 또 다른 음악을 작곡할 수 있음.

기대 효과 및 활용 방안
뇌파 데이터를 통해 ‘나만의 음악’을 만드는 접근 방식은 마음의 세계를 음악으로 표현하려는 시도이다. 본 연구는 특히 사용자의 ‘감정 상태와 유사한’ 음악을 만드는 것이 목적이기에 기존의 연구보다도 내면을 음악으로 표현하는데 더 큰 의의를 가질 것으로 보인다. 사용자는 자신의 내면과 감정이 담긴 음악을 통해 자신의 상태를 피드백 할 수 있게 되며, 나아가 본인이 선호하는 악기 뿐만 아니라 음악의 장르를 선택하여 내면의 감정을 해당 장르의 음악으로 표현함으로써 사용자 내면의 익숙하지 않은 감정에 더 쉽게 다가갈 수 있다.
발표 및 데모 프로그램 시연
'프로젝트·연구 > 프로젝트·연구' 카테고리의 다른 글
| 🏆2021-2학기 CAPSTONE-DESIGN 경진대회 최우수상 수상 <교내>🏆 (0) | 2022.01.27 |
|---|---|
| 🏆소프트웨어페스티벌 데이터분석부문 상 휩쓸었다! 대상, 우수상 모두 수상 <교내>🏆 (0) | 2021.12.08 |
| 🏆A.I.D.D, 최우수상 수상! 2021, AI 당뇨병 발병 예측 데이터톤 참여, 시상식 후기 <전국구 132팀중 최종 2등>🏆 (0) | 2021.11.29 |
| 🏆댓글분석 프로젝트, 최종 은상 수상!!! , 2021 한이음 ICT공모전 3차평가 발표 및 시상식 후기 <전국구 400 팀중 공동4위>🏆 (0) | 2021.11.12 |
| [데캡디-수정후] 뇌파 기반 사용자 친화 음악 작곡 알고리즘 구현(1. 수행계획) (0) | 2021.10.27 |