2022.02.05, 17:33 최종 수정
많은 시행착오, 오류수정 끝에 알파폴드2 실행에 성공했다!

https://github.com/deepmind/alphafold
실행하기 위한 코드 및 설명은 여기에서 확인할 수 있다.
GitHub - deepmind/alphafold: Open source code for AlphaFold.
Open source code for AlphaFold. Contribute to deepmind/alphafold development by creating an account on GitHub.
github.com
설치에 대한 얘기를 하기 전에, 미리 알아두면 좋을 AlphaFold2 에 대한 내용을 소개하려 한다.
ppt 열심히 만들었다.

결론적으로, ranked_0.pdb 를 확인하면 된다.



이제 설치에 대한 얘기를 해보자.
내 서버 환경은 다음과 같다.
- Ubuntu 18.04.01
- Conda 3.9.2
- Nvidia-driver-465
- CUDA 11.3
- cuDNN 8.2.1
- Pytorch 1.9.0
내가 겪은 오류는..
unable to create StreamExecutor for CUDA:0: failed initializing StreamExecutor for CUDA device ordinal 0: INTERNAL: faild call to ceDevicePrimaryCtxRetainL CUDA_ERROR_OUT_OF_MEMORY: out of memory; total memory reported: 2544170048Attemping to fetch value instead of handling error INVALID_ARGUMENT: device CUDA:0 not supported by XLA service
Fatal Python error: AbortedRuntimeError: jaxlib/cusolver_kernels.cc:44: operation cusolverDnCreate(&handle) failed: cuSolver internal error
PermissionError: [Errno 13] Permission denied: '/mnt/output/T1050/msas/uniref90_hits.sto'
이건 내가 기록해둔것만 나열한거고, 이것 말고도 오류가 정말 많았는데.. (+ jaxlib 버전 문제 등)
구글 서칭을 통해 누군가 해결했다는 방법을 내 dockerfile에 적용해도, 계속 오류가 수정되질 않았었다.
dockerfile을 다른 버전으로 바꿔도 보고 수정도 해보고 했는데 계속 오류오류오류...ㅜㅜ
내가 CUDA 11.3 version을 쓰는 문제도 있던것같고, Alphafold2 소스코드 자체에서 발생한 문제도 있던 것 같다.
그러다 1주? 쯤 전에 AlphaFold가 새롭게 release 되어서(v2.1.2 ), 다시 git clone 하여 약간의 오류를 수정해주니 정상 작동했다! 아마 앞으로 알파폴드를 실행해보려는 분들은 오류 걱정 없이 편하게 실행할 수 있을거라 생각된다. 난 2주를 고생했다! 니가이기나 내가이기나 해보자는 집념으로 2주동안 계속 오류 수정했다..
참고) 기본적으로 docker에 대한 지식, 리눅스 명령어에 대한 지식이 있는 사람만 시도하라.
약간의 팁을 주자면..
1. 만약 build시 오류가 났거나, dockerfile을 바꿔서 build 를 다시 해야할때 등등의 상황에서는, 미리 세팅된 image 및 container 를 지워주고 다시 build 하도록 하자.
docker image ls
docker rmi -f <image name>
docker image prune
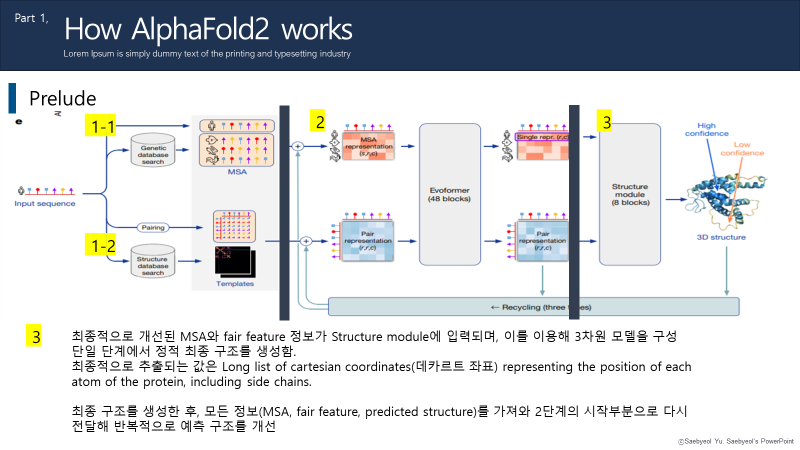
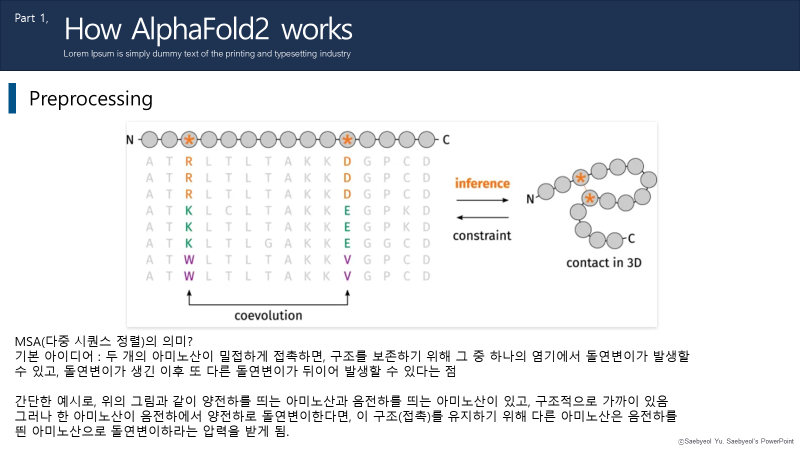
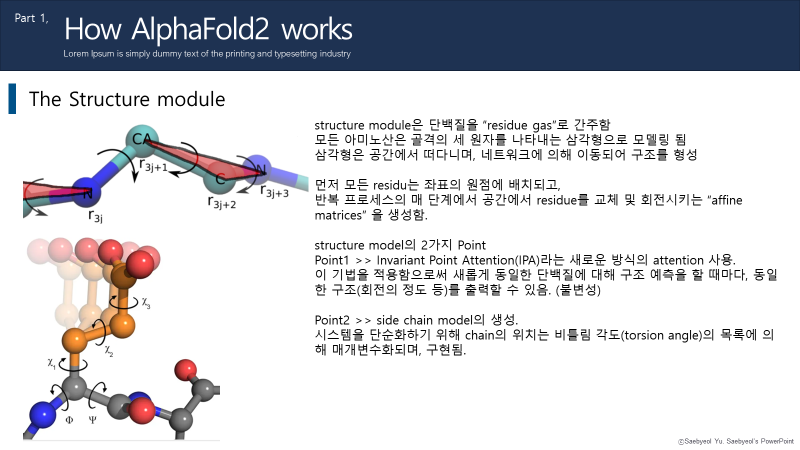
docker container prune
2. 데이터셋 다운로드 받는데는 약 2~3일정도 걸린다. 걱정하지말고 냅두면 잘 다운로드 될 것이다.
3. 전체 프로세스를 간략히 하면, 다음의 명령어가 필요하다. (참고만 하라)
git clone http://github.com/deepmind/alphafold.git
GitHub - deepmind/alphafold: Open source code for AlphaFold.
Open source code for AlphaFold. Contribute to deepmind/alphafold development by creating an account on GitHub.
github.com
cd alphafold
docker build -f docker/Dockerfile -t alphafold .
pip3 install -r docker/requirements.txt
python3 docker/run_docker.py --fasta_paths=/data/AlphaFold2/input/T1050.fasta --max_template_date=2020-05-14 --data_dir=/data/AlphaFold2 --output_dir=/data/AlphaFold2/output
path, dir 같은 경로는 본인의 input파일, output파일, data를 저장한 파일의 경로를 설정하면 된다.
상세한 설명은 Alphafold github에 가면 확인할 수 있으니 생략하겠다.
내가 사용한 dockerfile을 첨부해두겠다.
예시로 사용한 T1050.fasta 파일을 포함한 .fasta 파일은 아래의 링크에서 얻을 수 있다.
https://www.predictioncenter.org/casp14/targetlist.cgi
Targets - CASP14
Target List csv Targets expire on the specified date at noon (12:00) local time in California (GMT - 7 hours). Green color - active target; Yellow color - target expires within 48 hours; Orange color - target expires within 24 hours; Red color - target
www.predictioncenter.org
fasta 파일은 특정 분자(아미노산)의 서열을 나타내는데 사용되는 파일형식이다. 형태는 아래와 같다.
>T1050 A7LXT1, Bacteroides Ovatus, 779 residues|
MASQSYLFKHLEVSDGLSNNSVNTIYKDRDGFMWFGTTTGLNRYDGYTFKIYQHAENEPGSLPDNYITDIVEMPDGRFWINTARGYVLFDKERDYFITDVTGFMKNLESWGVPEQVFVDREGNTWLSVAGEGCYRYKEGGKRLFFSYTEHSLPEYGVTQMAECSDGILLIYNTGLLVCLDRATLAIKWQSDEIKKYIPGGKTIELSLFVDRDNCIWAYSLMGIWAYDCGTKSWRTDLTGIWSSRPDVIIHAVAQDIEGRIWVGKDYDGIDVLEKETGKVTSLVAHDDNGRSLPHNTIYDLYADRDGVMWVGTYKKGVSYYSESIFKFNMYEWGDITCIEQADEDRLWLGTNDHGILLWNRSTGKAEPFWRDAEGQLPNPVVSMLKSKDGKLWVGTFNGGLYCMNGSQVRSYKEGTGNALASNNVWALVEDDKGRIWIASLGGGLQCLEPLSGTFETYTSNNSALLENNVTSLCWVDDNTLFFGTASQGVGTMDMRTREIKKIQGQSDSMKLSNDAVNHVYKDSRGLVWIATREGLNVYDTRRHMFLDLFPVVEAKGNFIAAITEDQERNMWVSTSRKVIRVTVASDGKGSYLFDSRAYNSEDGLQNCDFNQRSIKTLHNGIIAIGGLYGVNIFAPDHIRYNKMLPNVMFTGLSLFDEAVKVGQSYGGRVLIEKELNDVENVEFDYKQNIFSVSFASDNYNLPEKTQYMYKLEGFNNDWLTLPVGVHNVTFTNLAPGKYVLRVKAINSDGYVGIKEATLGIVVNPPFKLAAALQHHHHHH이걸 input 디렉토리에 넣어놓으면 된다. (나는 리눅스 cat 명령어를 이용해서 저장했다.)
예측이 종료되면 다음과 같은 output 파일이 생성된다. (구조)
<target_name>/
features.pkl
ranked_{0,1,2,3,4}.pdb
ranking_debug.json
relaxed_model_{1,2,3,4,5}.pdb
result_model_{1,2,3,4,5}.pkl
timings.json
unrelaxed_model_{1,2,3,4,5}.pdb
msas/
bfd_uniclust_hits.a3m
mgnify_hits.sto
uniref90_hits.sto
결론만 말하자면, 최종 모델 중 신뢰도가 가장 높은 구조는 ranked_0.pdb 파일로, 3D 구조를 확인하고자 할때 이것을 확인하면 된다.
출력된 pdb 파일은 아래의 링크를 이용해 3D 시각화하였다.
https://www.ncbi.nlm.nih.gov/Structure/icn3d/full.html
iCn3D: Web-based 3D Structure Viewer
www.ncbi.nlm.nih.gov
시간을 많이 들였는데 결국엔 정상 작동해서 다행이다.
매번 논문을 읽기만 하지, 실제로 논문에서 제시된 내용, 소스코드를 들여다보면서 실행해본적은 없었는데 좋은 경험이 되었던 것 같다. 앞으로 다른 논문을 보더라도 실제로 연구결과를 재현해 볼 수 있겠다는 자신감도 생겼다.
그러나 알파폴드는 아직 들여다볼게 많다는 것,,, 이제 시작점이라는 것,,, 그게 조금 두려우면서 기쁘다.