
2021년도 동계 저널클럽 활동을 하며, 발표한 자료입니다.

제가 오늘 함께 공유하고자 하는 논문은 NAACL 저널에 기고된
Multilingual Language Models Predict Human Reading Behavior 입니다.
https://aclanthology.org/2021.naacl-main.10/
Multilingual Language Models Predict Human Reading Behavior
Nora Hollenstein, Federico Pirovano, Ce Zhang, Lena Jäger, Lisa Beinborn. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021.
aclanthology.org
즉, 인간의 읽기 행동을 예측하는 다국어 언어 모델의 개발이 논문의 주제인 것인데요.
여기서 예측하고자하는 ‘인간의 읽기 행동’ 이란, 자연 상태에서 피험자가 문장을 읽을 때, 문장의 어떤 단어, 어느 위치에 피험자의 시선이 오래 머무는지를 의미합니다.
정리하면, 이 연구는 문장 data와, 해당 문장을 읽을때의 Eyetracking data를 이용하여 문장이 주어졌을 때 피험자의 시선이 어느곳에 주요하게 머물지를 연구하는 것이라고 볼 수 있겠습니다.
제가 이 논문을 선정한 이유는, “자연 읽기 상태 뇌파의 자연어로의 해독”이라는 지금의 제 연구 주제에 접목시킨다면 더 좋은 성과를 얻을 수 있을 것이라 판단하였기 때문이고, 동시에 여러분께 이 논문에서 사용된 들어는 봤으나 다소 생소한 Transformer-based 모델에 대해 소개해드릴 수 있기 때문입니다.

오늘의 발표는 다음과 같은 순으로 진행되겠습니다.

언어를 처리할 때 인간은 선택적으로 문장의 가장 관련성이 높은 요소에 더 오래 주의를 기울이게 되죠. 이렇듯 문장에서 단어의 상대적 중요성을 평가하는 능력은, 인간 언어 이해에 있어 핵심적인 요소라고 할 수 있습니다. 그러나 여태껏 인공지능 모델에서 이러한 상대적 중요성이 어떤 방식으로 인코딩-디코딩 되는지는 알려진 바가 없습니다. 그래서 연구진은, 인공지능 모델에서 어떻게 인간 언어의 상대적 중요성을 파악하는가를 알고자 하였고,
그 방법으로, 피험자가 글을 읽을 당시의 시선의 움직임을 추적하고, 해당 위치에 고정되어있는 기간과 같은 Feature를 측정 및 예측함으로써 파악할 수 있다고 생각했습니다.

다음의 그림은 해당 문장이 주어졌을 때, 피험자의 시선 추적 데이터를 시각화하여 나타낸 것입니다.
원은 눈이 고정되어 있던 위치, 그리고 원 아래 숫자는 시선이 고정되어 있던 시간을 의미합니다.
이 문장은 Laurance를 소개하는 글에서 가져온 문장인데요. 이전에 나왔던 이름인 Laurance 보다, 새롭게 등장한 단어인 Mary가 피험자에게 상대적으로 더 중요했기 때문에, 두 번, 그리고 더 오래 고정된 것을 확인할 수 있습니다.
연구진은 이러한 시선 추적 데이터를 통해 우리는 눈의 움직임 패턴을 예측할 수 있게되고, 이것은 동시에 모델의 인지적 타당성을 이해하는데 한걸음 더 다가갈 수 있게 해준다고 주장합니다.

본 연구에서는 다양한 종류의 데이터세트를 사용합니다.
영어 (Zuco), 독일어, 네덜란드어, 러시아어 등 다양한 언어로 작성된 문장과 시선처리 데이터에 대하여, 인간의 행동 패턴을 예측하는 큰 모델과 작은 모델이 있습니다.
작은 모델은 단일 언어를 학습하고 표현하는 모델이며, 큰 모델은 다국어 transformer 모델로, 모든 언어를 학습하고 표현하여, 작은 모델 보다 보편적인 언어 이해를 목표로 하는 모델입니다.
연구진들은 사람이 문장을 읽을 때, 특정 현상에 대한 시선 추적 패턴은 언어에 상관없이 일관되기 때문에, 단일 모델보다도 다국어 모델이 피험자의 행동 패턴을 예측하는데 있어 더 좋은 성능을 보일 것이라 가정하였습니다. 그리고 연구진은, 이 가설을 영어, 독일어, 네덜란드어, 러시아어 의 총 4가지 언어의 6개 데이터세트에 대해 테스트 하였습니다
표1은 모델 훈련시 사용된 각 데이터셋에 대한 기술통계 입니다. 던디, 지코, 주고, 지코, 포텍, RSC 의 총 6가지 데이터가 사용되었고, 각 데이터셋의 평균 문장 길이, 평균 단어 길이, 총 토큰 개수 등을 확인할 수 있습니다. 플래쉬 점수는 각 언어가 얼마나 읽기 쉬운가를 나타낸 지표인데요, 0 에서 100사이의 점수로 나타내어지며 점수가 높을수록 읽기가 쉬움을 나타냅니다.
데이터셋 각각에 대해 간략히 설명하자면,
1) 던디 데이터셋은 20개의 신문기사가 포함된 데이터셋으로, 한 번에 다섯 줄의 화면이 영어 원어민 독자에게 제시되었습니다.
2) 지코 데이터셋은 영어 소설이 포함된 데이터셋으로, 단락 별로 화면에 표시되었습니다.
3) 주코 데이터셋은 영화리뷰 및 위키피디아 기사의 전체 문장에 대한 시선 추적 데이터가 포함됩니다.
4) 지코 데이터셋에는 네덜란드 독자의 시선추적데이터가 포함되어있고
5) 포텍 데이터셋에는 대학 수준의 생물학 및 물리학 교과서의 짧은 구절이 포함되어 있습니다. 전체 구절이 여러줄로 표시되었고, 독일어 원어민이 읽습니다.
6) RSC 데이터셋은 러시아어로, 국립 코퍼스에서 추출한 문장이 포함되어 있습니다. 성인에게 한번에 하나씩 전체 문장이 화면에 표시되었습니다.

시선 고정이란 피험자의 시선이 한 위치에 유지되는 시간입니다. 고정은 각 단어에 속하는 화면의 영역 주변 경계를 구분하여 단어에 맵핑됩니다. 단어는 한번이상 고정될 수 있으며, 각 토큰(문장)에 대해 초기 구문부터 후속되는 구분까지의 전체 읽기 프로세스를 인코딩하는 다음 8가지 시선추적기능을 예측합니다. (다음의 각 단어별 특성 추출)
(1) 고정 수—해당 단어에 고정된 횟수, (모든 피험자에 대한 평균값)
(2) 평균 고정 지속시간 – 모든 고정의 평균 고정 지속시간
(3) 고정 비율 – 해당 단어에 고정된 피험자의 수/전체 피험자 수
(4) 첫번째 고정 기간 – 해당 단어에 첫번째로 고정된 기간 . 모든 피험자에 대한 평균
(5) 첫번째 통과 기간 – 주제가 고정될때부터 통과 이후 모든 고정의 합. (????)
(6) 총 읽기 시간 – 모든 고정기간의 합, ?(?)
(7) 재고정 횟수 – 첫번째 고정 후에 고정 된 횟수
(8) 다시 읽은 비울 – 1회이상 고정된 피험자 수 / 전체 피험자 수
이렇게 추출된 데이터는 각각 값의 범위가 다르므로, 0에서 100 사이로 균일하게 맞추어 손실을 계산합니다.
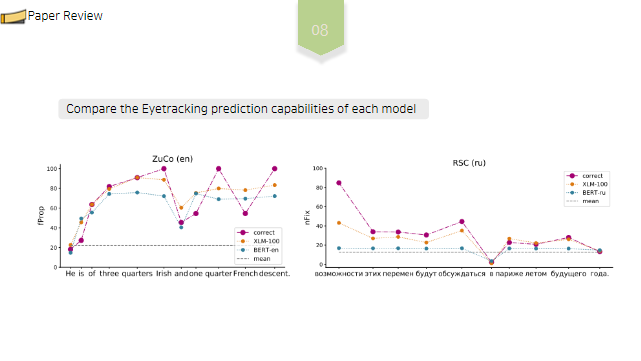
BERT와, XLM의 두 모델에서 시선 추적을 예측하는 기능을 비교합니다.
왼쪽 그림은 ZUCO 영어 데이터셋에 대해 추출한 단어수준 feature 중, (3) 고정 비율 에 대해 예측한 값입니다. (이후 0~100 으로 scaling) 즉, He is of three quarters Irish andone quarterFrenchdescent. 문장에서, 각 단어에 고정된 피험자수/ 전체 피험자수를 나타낸 값인것이죠.
분홍색 선이 정답값이고, 주황색선은 XLM을 이용한 예측값, 파란색선은 BERT-모델을 이용한 예측값입니다.
오른쪽 그림은 RSC 러시아어 데이터셋에 대한 고정 수, 즉 해당 단어에 고정된 횟수에 대해 나타낸 값입니다. 마찬가지로 붉은 선이 실제값, 주황선이 XLM 모델을 이용한 예측값, 푸른색이 BERT 문장의 예측값입니다.
두 모델 모두 상당히 높은 정확도를 보이는 것을 확인할 수 있습니다.
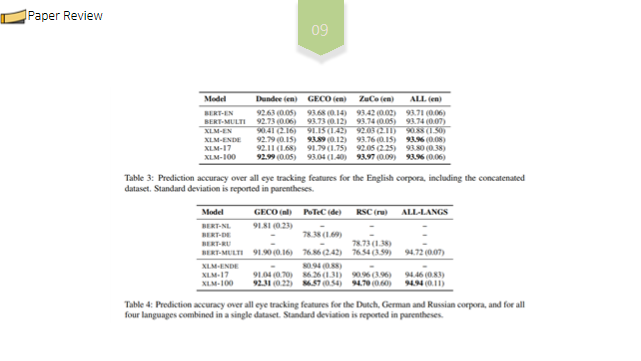
각 언어 및 모델별 정확도를 비교한 최종 결과는 다음과 같습니다. 괄호 안에있는 것은 표준편차입니다.
pre-trained transformer 모델이 4가지 언어의 읽기 행동 패턴을 예측하는데 전반적으로 90% 이상의 높은 정확도를 보이는 것을 확인할 수 있었습니다. 또한 XLM 모델의 결과는 평균적으로 약간 더 낮지만, 훨씬 더 높은 표준편차를 나타냅니다.
상대적으로 작은 데이터세트인 RSC 같은경우, 다국어 XLM 모델이 단일언어 모델보다 성능이 뛰어난 것을 확인할 수 있습니다.
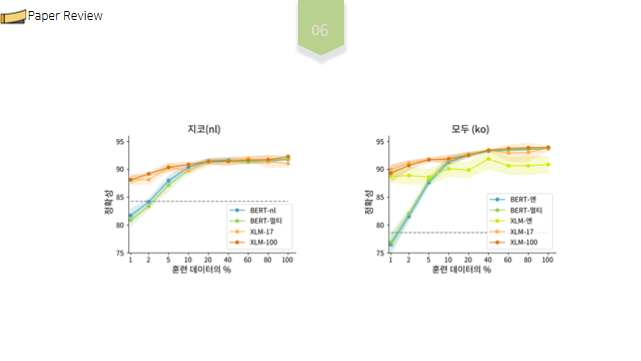
또한 XLM 모델의 성능은 아주 작은 비율의 시선추적데이터로도 안정적으로 유지되지만, BERT 모델의 성능은 데이터의 20% 미만을 미세 조정할 때 급격히 떨어지는 한계가 있었습니다. 음영 처리된 영역은 표준편차를 나타내며, 점선은 파인튜닝없이 사전훈련된 BERT-MULTI 모델의 결과입니다.
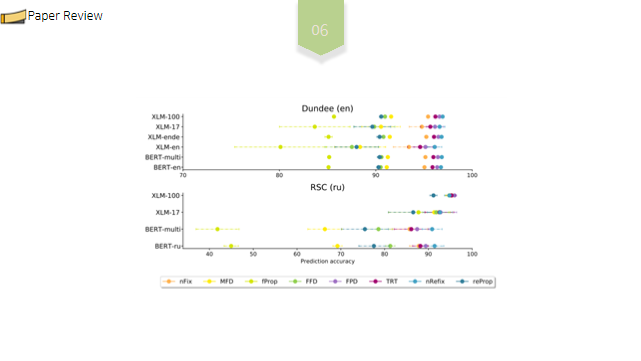
지금까지 다국어 모델보다 특정 언어에만 훈련된 단일 언어 모델이 더 성능이 좋은 경우가 많지만, 다국어 모델은 적은 양의 데이터로 미세 조정될 때 언어별 모델보다 이점을 보여주었으며, 사용된 transformer 모델이 인간의 처리 메커니즘과 유사한 방식으로 언어의 상대적 중요성을 인코딩 한다는 것을 확인할 수 있었습니다.

저는 이번 저널리뷰를 통해 연구원이 연구를 어떻게 진행하는지, 최근에는 어떠한 연구주제가 있는지 등을 아는 것도 중요하지만, 사용된 모델이 무엇이고 어떻게 동작하는 것인지 간략하게나마 이해하는 것도 매우 중요한 요소라고 생각합니다. 그래서 따로 여기서 사용된 Transformer 모델이 대체 무엇인지, BERT 와 XLM 이 무엇인지, 살펴보는 시간을 갖도록 하겠습니다.
관련 내용은 다음의 문서로 가주세요!
https://checherry.tistory.com/111
자연어 처리 분야 최신기술! Transformer model, BERT, XLM 모델이란?
Transformer 는 Attention all you is need 논문에서 제안된 모델 구조로, RNN 의 long-term-dependency 의 한계점을 극복하기위해 제안된 아키텍처입니다. (은닉 상태를 통해 과거 정보를 저장할때, 문장..
checherry.tistory.com