그간 또 바쁘게 살아와서 티스토리 업로드를 하나도 하지 못했다. 시간이 없었다기보다 맘에 여유가 없었고.. 생각도 못하고있었다. 소식 안올린사이에 너무나 많은 일들이 있었는데...!! 언제 다 올리지.?
티스토리는 아무도 모르게 나 혼자 몰래 작성하는 일기장, 수행한 활동과 결과물들을 정리하며 뿌듯해하는 공간이었는데. 몇달 전인가에 별 생각없이 친구에게 링크를 알려줬다. 바본가?! 상관없나 싶기도 하구.
귀찮지만 티스토리 글을 앞으로도 업로드 하려고 노력해야겠다 싶은게, 오늘 내가 예전에 무슨 활동들을 했더라 찾아봤는데.. 기억에도 없던 활동들이 막 있더라. 자잘해서 기억 안하고 묻어둔 것들이.. 나중에라도 이런거 기억해서 어필하려면 꾸준히 상세하게 기록해두는게 좋겠다는 생각이 든다. 장기 기억력이 안좋아가지고 ㅡ. ㅡ
남은 3월도 할일이 산더미처럼 쌓여있어서, 아마 4월에나 업데이트를 좀 할수있지 않을까 싶다. 오늘 살짝 정리해본 링크드인 링크나 올리고가야지 아 공지에 추가하면 되겠다! https://www.linkedin.com/mwlite/in/evedayekim 사실 링크드인에 정리해둔것보다 한거 훨씬 많은데 ㅠㅠ 나중에 정리해야겠다.
앞으로도 파이팅!!!
# 유종의 미를 거두려 노력하자 # 늘 성장에 굶주린 사람이 되자. 배부르다고 느끼지 말아라 # 제대로 공부하고, 공부한건 머리에 붙들고있자 방금 든 생각이당
+ 아... 고등학생때부터 연고지 장학재단, 드림스폰 사이트 등등 매주 한번씩은 확인하면서 받을 수 있는 장학들 다 도전해봤어야했는데. 4학년 2학기때 깨달았네... 인생 다시 살면 진짜 받을 수 있는거 누릴 수 있는거 다 하면서 살텐데 TT 아쉽다
If you try to create anaconda environment to another machine, you should edit the envconda.yaml file's prefix to the another machine's anaconda3 directory.
개강하기 전에.. 방학에 본격적으로 공부하기 전에 남자친구먼저 찾아두려고했는데 방학이 다 끝날무렵까지 찾질 못했다. 난 2주면 찾을 줄 알았는데;; 2달이 지나도록 못찾을줄은 몰랐지.. , , , ㅠㅠ 이제는 그만 찾고, 살 빼고! 공부하며! 나를 더 가꾸고 커리어를 쌓는 일을 해야겠다. ㅎ... 더이상은 시간낭비일듯 그래도 2개월동안 이런저런 사람들을 만나며 다양한 경험도 해보고.. 얘기도 많이 나눠보고.. 한 것에 의미가 있는 듯.! 주의할 점이나.. 내가 할 수 있는 실수들.. 고민할 부분들도 많이 파악되던 시간인 것 같다. 분명 이 경험두 나중에 도움이 되겠지... 그리고 최근에 느낀건.. 어디서든 인사성 밝은 사람이 되어야겠다는 것. 인사 많이 한다고 안좋은 것두 아닌데. 일상 생활을 예로 들면, 택시/버스를 타고내릴때나 가게 들어갈때? 음식 나올때.. 사람을 만나고헤어질때.. 직장 생활을 예로 들면, 어디 멀리갈때, 돌아왔을때 인사.. 매일 출퇴근할때 한분씩 인사,, 화장실 갈때 돌아올때 등 복도에서 마주쳐도 인사,, (+ 인생 선배님께 얻은 팁.. 직장생활에서, 초반에 너무 열정적인 모습 보이지 말 것... 본 업무를 받으면 열심히 하되, 잔 실수를 몇개라도 일부로 낼 것... 안 그러면 다른 자잘한 업무 다 나한테 몰린대.. 인사성 밝고 착하고 열심히 하려고는 하는데 일할때 잔실수가 좀 있어 본업무를 잘하게 좀 챙겨줘야 하는 직원이 되는게 베스트... , , 인사성 안밝고 인성 별론데 일 완벽하게 하는것보다 나음. 추가업무만 과중될 수 있공,, ㅠㅠ 솔직히 나는 신입으로 들어가면.. 열심히!! 최선을 다해!! 해야지! 라는 생각으로 하라는거 다 하며 임했을 것 같은데.. 이번에 조언을 듣고 맘이 좀 바뀐게 있다. 실제 이 선배님은 열정적으로 하다가 직장내괴롭힘수준으로 업무가 자기한테만 쌓여서 10시 11시 퇴근은 기본이고 주말에도 나와서 했다고 한다. 스트레스 받아서 살이 7키로가 빠졌다고.. 과거 이 분과 비슷하게 열정적으로 하시던 분이 계신데, 업무중 과로로 쓰러지셨고 뇌에 문제가 생겨 지금까지 고생하신다고 한다. 산재인정 못받으셨고 대신에 직장 계속 다니시고 쉬운 업무만 드린다고.. 이 말을 듣고.. 아.. 뭐든 과한건 좋지 않구나, 열심히 하고싶어도 내 건강을 챙길 수 있을만큼 봐가면서 업무를 해야하는구나 생각했다. )
아 그리고 하고싶던 봉사활동도 해야겠다. 그냥 하는게 아니라, 꾸준히 해서 봉사동아리 회장 정도는 해보고 싶긴 하다. 찾아봐야지.. 무슨 봉사가 좋을까? 어린이 대상 영어 회화 교육 봉사... 이런거 있나? 경제봉사동아리도 있을테고.. 어딘가의 회장이라는 게 참 그 사람을 볼때 + 요인이 되기는 하는 듯.. 무슨 동아리 회장이다~ 무슨 뭐뭐다~ 나도 일단은 과 대표 였던 적이 있으니까.. 잘 한 것도 있구.. 그거도 쓸 수 있을 것 같고.. (대학생 경제교육봉사단 JA 코리아 등 ) 최소 6개월~1년? https://blog.naver.com/chongroblog/222843101054 https://210306.tistory.com/43 일단 올해 말.. (빠르면 10~11월, 늦으면 2~3월달까지도 있음)에 원서를 쓸테고. 결과는 빠르면 12월중 늦으면 ?? 중에 나올테지. 다음년도 가을에 입학예정이구... 일단 10월달까지 준비를 완벽하게 마쳐야해! (학회는 올해 7월중순 그리스) 타임라인을 그리자.
2월 말~3월 초 2.25 토플 1차시험 (연습겜) 2.25-3.2 토플&졸논, 3월초에 교수님 연락 후 졸논미팅, 수강신청(디사, 창종설), 창종설 주제 등 고민 생활비장학 찾기 3월 3.2-18 토플 2차시험 (마무리) 3.6~3.30 학회논문 1개 신경쓰기(분석알고리즘, 3.31 abs제출) 3.18~ GRE 공부 학점챙기기 졸논 2개 신경쓰기(의료딥러닝/..딥러닝) 4월 4.7 full paper 제출 4월 내내 GRE 공부 학점-졸논2개(이때까지는 어느정도 윤곽이ㅠ) -학회논문 5월 5.6 GRE 시험응시!! 5.15 학회논문 accept 확인 5.23 Fulbright 장학 마감일, 오후5시까지 신청하기 (Fulbright 아니더라도 찾아둔 다른 장학목록 찾아놓기) 학점-졸논2개마무리 6월 학점-졸논2개 마무리. .--> 국내/해외 저널에 제출 학회논문 발표준비, 비행기 등 알아보기 미리 연구기관 인턴할 곳 찾아두기 7월 졸업 연구기관 인턴 ( Kist, Etri, Kosep 등.. 한국과학기술평가원 좋다던데) 7.17~20 컨퍼런스 미국 대학원용 토플, GRE 시험 한번더 응시, 오픽시험보기 SOP, 등 준비.. 8월 대학원 지원 준비.. 연구기관 인턴.. 9월 대학원 지원 준비/연구기관인턴 10, 11, 12, 1, 2 월 인턴+영어공부 미국 대학원 지원 ( 스펙 네이버 메모인가 적어둔거 참고. + 겸사겸사 한국 대학원도 서카포만 다 지원해보는것도 좋을듯) 학회1 저널2 봉사 국책연구기관인턴 학생회 공모전수상경력및프젝 퍼듀대연구인턴 경희대학부연구인턴 데이터자격증 영어자격증(토플,GRE) 추천서(이원희교수님 Eric교수님 정재윤 교수님 --> 12월~3월 사이에 결과가 다 나올텐데. 다 안되면 국책연구기관에 학사로 갈까? 연구기관에서 석사 보내줄수도 있댔음. 주제사?? 해외로도 많진않지만 비용 다 대주며 보내준다던데. 함 찾아보자.
팀 프로젝트도 많았고, 시험도 많았고, 과제도 많았고, 연구도 해야했다. 수업도 들어야하고 복습도 해야하고.. 거기에 각종 지원서 작성, 영어 면접 준비, 헬스장까지.. 숨을 돌릴 교양과목도 없이 6전공이었다.
여러 팀 프로젝트(무려 3개..)에 시간을 쏟는 동안에는 정작 내 연구를 못해서 불안했고, 과제를 하는 동안에는 수업 복습을 못해서 불안했고, 시험 공부를 하는 동안에는 팀 프로젝트나 과제를 더 해야해서 불안했고,.. 그냥 뭔갈 할 때 다른 뭔가도 해야한다는 마음이 동시에 있어서 계속 급박하고 조급한 마음으로 살았던 것 같다.
중간고사나 기말고사도 이상하게 한 교수님께선 이르게 시험보는걸 좋아하시고 다른 교수님께선 늦게 시험보시는걸 좋아하셔서, 거의 2-3주동안 시험기간으로 보냈다. 기말 시험이 모두 끝난 이후에도, 제출해야하는 과제나 제출물이 있어서 남들보다 종강이 1주정도 늦게 끝났다.
저번 학기는 교외 공모전을 동시에 하느라 바빴는데, 이번 학기는 교내 수업 외에 더 벌려놓은 일이 없는데도 너무 바빴다. 그러다보니 내가 선택과 집중을 할 수 있는 상황이 아니었다. 어쩔 수 없이 이 과한 일정을 한 학기 내내 끌고 갔다. 매일매일 간신히 그 날의 일정을 끝냈다. 일정을 끝내면 다음날 바로 또 빡센 일정을 끝내야만 했다. 이번 학기의 목표는 학점 잘 받기와 연구 열심히 하기였는데... 학점은 잘 받았으나 연구를 성실하게 했는지는 모르겠다.
4학년은 원래 다들 이렇게 바쁜건가 싶었다. 양해를 구하고 1달에 1-2번정도 갔던 헬스장에서, 피티쌤이 4학년이어도 나처럼 바쁜 사람은 처음본다고 하셨다. 그런가? 싶어 주위 친구들에게 물어보니 내가 유독 바쁜 삶을 살고 있더라. 수강신청의 실패와.. 복수 전공을 늦게 시작한 여파가 있던 것 같다. 한 학기에 수업을 그렇게 들었으면 안됐는데, 졸업을 맞추기 위해 어쩔 수 없었다. 또 같은 수업의 팀 프로젝트더라도 우리 팀이 더 시간, 노력이 많이가는 주제를 선정한 탓도 있던 것 같다.
한 학기 내내, 마음속으로는 지금의 나에겐 연구를 하는 것이 가장 중요하다는 생각을 하곤 했지만.. 사실 학점을 높이는데 집중하고 싶은 마음이 더 컸었던 것 같다. 미국에 가기 전까지는 다른것들 보다도 연구에 더 집중하고 싶다. (...)
미국.. 미국에 간다는 내용도 tistory 에 적고 싶었는데. 너무 바쁘고 마음에 여유가 없어서 이번 학기는 게시글을 많이 올리지도 못했네.. 일단 그간 밀린 얘기들은 방학 동안에 차근차근 해보자.
지금은 종강(6.26) 이후 2주정도 지난 시기이다.
그리고 나는 지금 번아웃 상태같다. 아무것도 하기가 싫다. 그냥 쉬고만 싶다...
사실 그동안 열심히 산 만큼, 종강 직후 1-2주동안은 아무것도 안하고 마냥 놀려고 계획을 했었는데
연구쪽에 신경을 많이 못쓴게 사실이라, 진행해야 하는게 너무 많아서.., 온전히 내 일이라 내가 하지 않으면 진전되지 않아서 마음 놓고 쉴 수 없었다. 연구실 팀원과 다함께 제주도에 놀러갔다가 복귀하고, 이후부터 계속 뭔가를 또 했다.
제대로 딥하게 쉬질 않아서 그런지 정말 아무것도 하기가 싫다.. 그렇다고 아무것도 안하는 것도 아니고 뭔갈 집중해서 제대로 하는 것도 아닌 애매한 상태가 되어버렸다.
그나마 위안이 되는건 학점을 잘 받은것, 그리고 예전부터 신경쓰였던 과목을 성공적으로 재수강 한 것이다.
그리고 교내, 교외의 SW 활동( 논문, 학회발표, 공모전수상, 데이터톤수상, 특허등록, 등등의 활동) 이 우수한 학생을 장학생으로 선발하여 장학금을 지급하는 SW 마일리지에 금상 장학생으로 선정되었다! 200만원 받았당. 뿌듯
아무튼, 이번 학기 덕분에 총 평균 평점이 많이 높아졌다. 1학년때부터 열심히 살 걸 후회된다! 아니, 열심히 공부할걸 후회된다!
나도 열심히만 했으면 높은 학점을 받아왔을텐데.. 졸업을 앞둔 지금은 평균 평점이 높은 친구들이 너무너무 부럽다.
그래서 더더욱 2023-1학기에 다닐 4-2학기는 더욱 열심히 해서 높은 학점을 받고 싶다. 마침 이번학기 학점이 좋은 덕분에 다음학기에 3학점을 추가로 받을 수 있어서, 21학점을 들을 수 있다. 평점 평균을 더 높일 기회인 것이다.
그런데 문제는, 마지막 학기인만큼 졸업 논문을 써야하고, 연구를 마무리해야한다는 점이다. 심지어 나는 복수전공이라 졸업 논문을 2개 써야한다. 그리고 늦게 복수전공을 시작한만큼, 전공 졸업학점을 채우기 위해 이 때에도 최소 5전공을 들어야 한다.
......
전공 과목 공부하고, 과제하고 하느라 이번 학기처럼 매우 바쁠 게 예상되는데, 연구를 해야한다. 그것도 2개나..
그나마 졸업 논문 중 하나는 팀 프로젝트 예정이어서 다행인가? 그리고 다른 하나는 이번학기에 하던걸 이어하는 것이니 괜찮을지도...
학점을 높이기 위해 최대한 많은 수업을 들을지, 연구에 더 시간을 투자하기위해 최대한 적은 수업을 들을지가 고민이다.
근데 아마 후자를 선택해야겠지.. 교수님께서도 그렇게 조언해주실 것이다. 이 문제는 나중에 생각하기로 하자.
아무튼, 힘들었던 4-1학기가 끝났다.
여름 방학동안에는 연구를 진전시키고, 토플 공부 및 시험을 보고 영어 회화 공부를 할 예정이다. (헬스장도 자주 다녀야 하는데....... 자꾸 우선순위에서 밀려난다)
2022-2학기에는 휴학을 하고 미국에 간다. 거기서 만날 학우들과 열심히 프로젝트 해서 논문까지 쓰고싶고, 영어 회화도 많이 늘리고 싶고, 여행도 많이 다니고 싶다. 지금껏 휴학 없이 스트레이트로 달려왔으니 이제는 좀 쉬엄쉬엄 오로지 프로젝트에만 집중하며 휴식하고 싶다. 이 타이밍에 미국 지원 프로그램에 선정되어서 정말 다행이라고 생각한다.
앞으로는 티스토리도 다시 자주 써야지. 다른 분들께 도움이 될 정보들도 하나 둘 올려보도록 하겠다.
나는 요즘 CAD/CAM 수업을 들으면서 팀 프로젝트를 하고 있다. (이번학기 팀플만 3개.. +그외 개인연구/프로젝트 다수 ㅠㅠ)
주제 선정, 프로젝트 설계 및 제품 분석, 기초 디자인을 마치고.. 이제 직접 3D 모델을 만들어야 했는데,
이번에는 3Dexpeirnece의 Part Design(CATIA) 을 이용해 3D 모델을 만들었다.
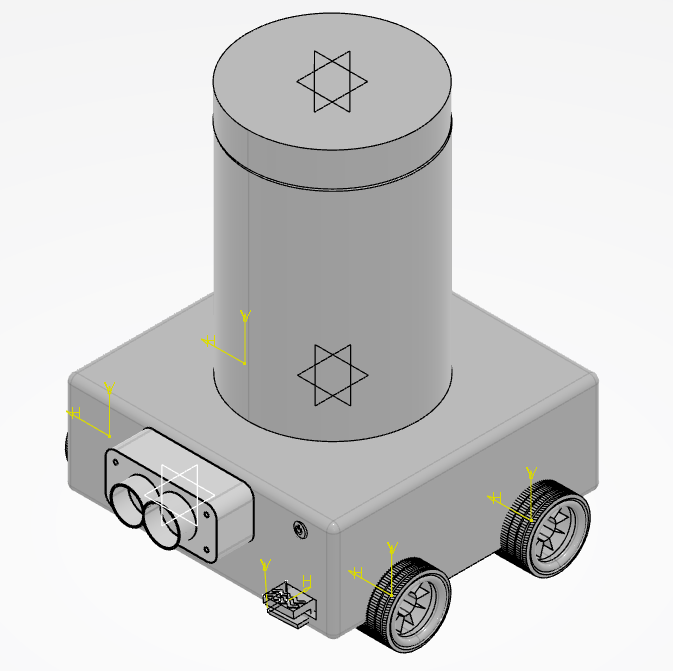
내가 맡은 부분은 Lim(바퀴 안쪽몸체), Tire(바퀴 타이어)이다. Lim과 Tire가 합쳐지면 Wheel 이 된다. (나중에 전체 프로젝트가 완성되면 Proposal 부터 Final report 까지 정리해서 올릴수도 있을것같다.)
이걸 구현하기까지 정말x1000000000 많은 시간을 들였다. 왜냐하면... 프로그램 설치 단계에서 작동 단계에 이르기까지 에러가 끊임없이 발생했기 때문이다.
겪은 에러1. 프로그램 설치가 3Dexperience 설치까지는 되는 것 같은데, Part design 을 설치하려고 하면 자꾸 다음 단계로 넘어가질 않았다. 설치가 안되니 모델링은 커녕 프로그램이 어떻게 생겼는지 보지도 못한다...
에러1 해결 -> 팀 프로젝트를 해야해서 n일에 걸쳐 nn시간동안 설치 오류 관련해서 정말 인터넷을 다 뒤졌다. 기본적인 네트워크 설정이나 방화벽, 포트 번호 확인하고 인바운드 아웃바운드 규칙 바꾸기, 속성 및 영역 재설정, 포트포워딩 등등... 안해본게 없다. 근데도 안돼서 어쩔 수 없이 다른 컴퓨터로 했다. 근데....... 다른 컴퓨터로 해도 똑같이 안되는 것이다........... 희망을 갖고 다시 인터넷을 검색해서 할 수 있는걸 해봤더니 이 컴퓨터는 정상적으로 다운로드 되더라. 설치까지 정말 많은 시간이 들어갔다.
겪은 에러2. 드디어 프로그램이 설치가 돼서, 모델을 만들어보려고 했는데 이상하게 내가 원하는 대로 도구가 작동하지 않았다. 나는 초심자니 내가 뭔가를 잘못하는줄 알고, 어떻게든 만들어보겠다고 이것저것 다 클릭하면서 비슷하게나마 만들어갔는데.... 그런데 정말 대부분의 도구가 동작을 안해서 도저히 불가능했다.... 거의 8시간을 니가이기나 내가이기나 해보자고 끙끙대다가, 이건 내 문제가 아니라 프로그램 문제라고 판단을 했다. 결과적으로 프로그램이 이상한게 맞았다.
에러2 원인 및 해결 -> 3D experience가 하필이면 내가 한창 다운받고 모델을 구현하려할때 서비스 점검을 했던 것 같다. 나 말고도 다른 팀원들이 모두 3D experience 가 작동이 안되거나 작동이 이상하게 된다고 하더라... 난 그것도 모르고....... 또, 하필 내가 다운받은 버전이 옛날 버전의 프로그램이었고, 최신 버전을 쓰지 않아서 기능이 작동하지 않는 이유도 있었다. 시간이 어느정도 흐르고, 프로그램을 업데이트 해주니까 정상 작동했다.
겪은 에러 3 -> 내가 구현한 모델의 특정 선 등을 삭제해주는 remove 기능이 작동을 안했다. Trim 까지는 잘 되는데 삭제가 안된다.... 마우스 우클릭 delete도 안되고 온갖 버튼 클릭을 다 해봤는데 삭제가 안된다. 그러다보니까 내가 원하는 모양을 구현할수가 없고 padding 해줘야 하는데 오류가 났다. remove 없이 어떻게든 하려고 하다가 2시간 날렸다.
에러3 해결 -> delete 키를 쓰면 됐다. 물론 delete 키를 쓰는 것도 맨 처음에 해봤는데.... 그땐 안됐다. 이유는 내 노트북 키보드가 delete 키가 맛이 가서 였다. 처음알았다..... 스페이스바도 맛이 갔는데 이제는 delete키도 맛이 갔구나. 컴퓨터를 바꿀 때가 온 것 같다. 다행히 블루투스 키보드가 있어서 이 키보드의 delete키를 썼다.
이렇게 설치문제, 기능작동문제, delete 키 문제를 해결하고.... 드디어 내가 원하는 대로 프로그램 도구들이 작동하기 시작하니 너무 감격스러웠다. 프로그램을 정상적으로 쓸 수 있다는게 이렇게 감격스러울 줄이야... 에러를 겪을때는 내가 이걸 설치할 수 있을까? 어떤 방법을 해도 설치가 안되는데? 하기도 했고 도구상자가 안먹힐때는 시간도 없는데 대체 왜 나는 내가 생각하는 기능을 쓸 수 없는건가 나는 모델링을 엄청 못하나 우울하고 스트레스 받기도 했고.. delete 키가 안먹혔을때는 대체 에러가 언제쯤 끝날까 내가 정상적으로 이 프로그램을 쓸수는 있을까 다른 기능도 다 에러있는거 아닌가 생각이 들었는데....
진짜 오기와 집념, 될때까지 한다는 마음으로 하니까 만들어지긴 만들어지는구나... 어제오늘 정말 에러 해결하겠다고 열심히 살았다... 생각해보니까 노트북 대신 프로그램을 설치해둔 컴퓨터가 집에서 멀리있어서 원격으로 데스크톱 연결해서 프로그램을 이용했어야 했는데.... 그와중에 원격 데스크톱 연결도 계속 오류나서 그것도 해결한다고 시간을 많이 썼다. 아침부터 가서 해결하고 오고... 바로 다음일정 가고....
그래도 마감 시간 안에 팀 프로젝트를 끝내서 마음이 놓인다.
사실 이거말고도 아직 할게 너무나 많이 남았는데........ 지금은 그냥... 나를 매우 스트레스 받게하던 일을 끝냈다는 거에 기뻐하고 싶다.
아래는 내가 이번에 처음으로 만들어본 휠이랑 바퀴... 처음 만든거치고 꽤 괜찮아 보여서 만족한다.
이것도 뭐 어떻게 쓰는 지도 모르고 하나 하나 기능 눌러보고 인터넷 찾아보면서 멘땅에 헤딩했는데...
모델링 해보기도 전에 에러를 너무 많이 겪다보니까.. 마음이 굉장히 지쳐있었어서.. 모델링 하는건 일도 아니었다.
처음부터 에러 없이 잘 됐으면 고생 안하고 충분한 시간 써서 더 완성도 있게 마무리했을텐데...ㅠㅠ
SW를 하고싶다면 이런거에 익숙해져야지 어쩌겠나는 생각도 든다.
Wheel 부품 중 하나인 Lim// 안쪽은 60mm, 바깥쪽은 150mm
Wheel 부품 중 하나인 Tire// 안쪽은 150mm, 바깥쪽은 200mm
Assembly!
바퀴축에 합체!
다른 팀원 분들이 만들어오신 파츠랑 합체!
제일 마지막에 올린 사진이 우리 팀의 최종 완성본이다. 나중에 보고서랑 같이 업로드할 기회가 있겠지.!!
이제 3D printing 만 하면 이번 수업 팀 프로젝트도 끝이네.
인터넷 찾아가면서 하다보니 이제 어느정도 3Dexpeirnece 기능도 알겠고.. 막연한 두려움도 많이 없어졌다.
3D 모델링 대체 어떻게 하는걸까 궁금했는데 첫 발을 내딛은 것 같아 기쁘다. 은근히 재미있기도 하고
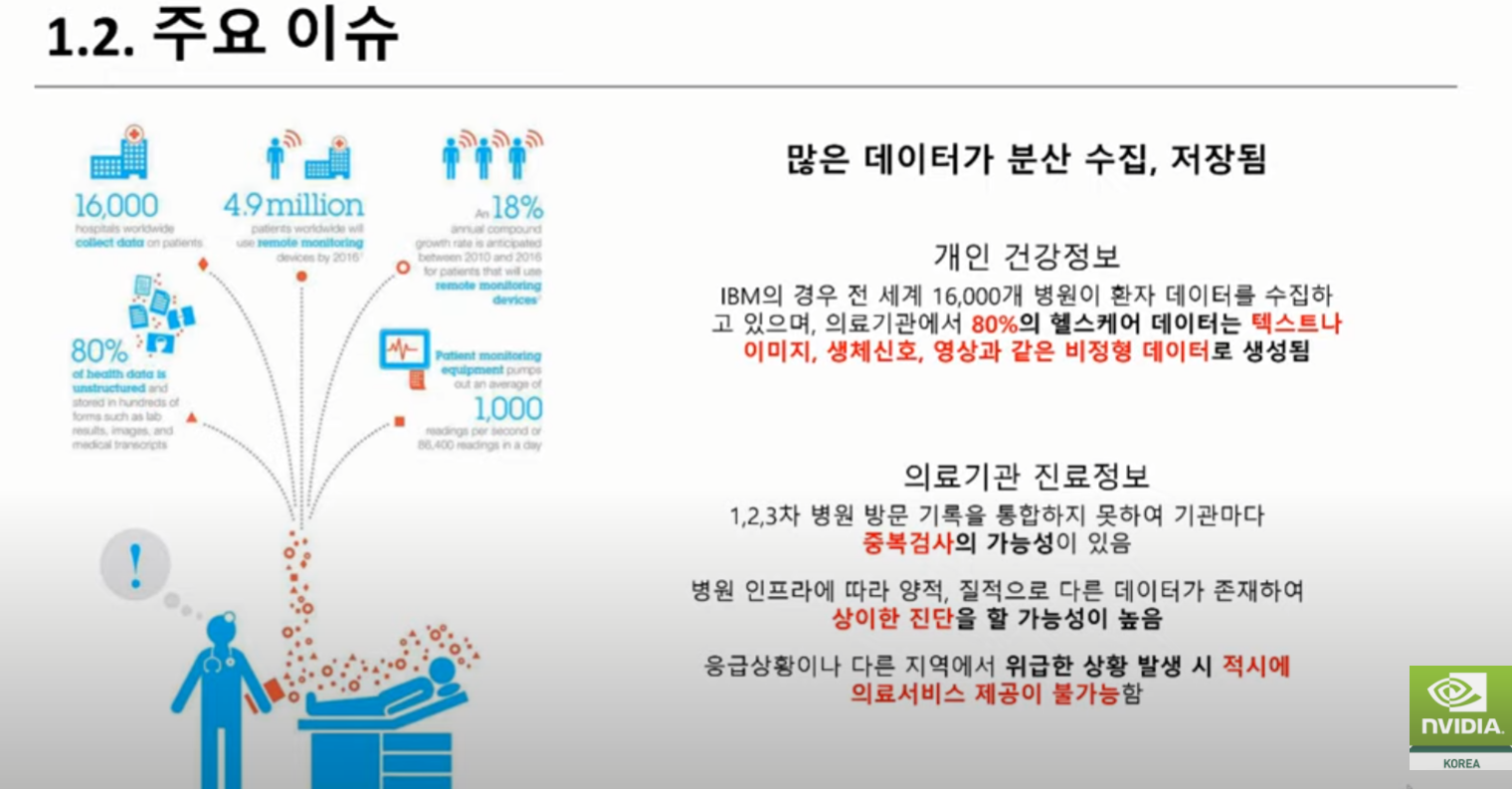
이번 강연은 헬스케어 분야의 최신 AI 애플리케이션 및 프레임워크에 대한 강연(= 최신 NVIDIA 애플리케이션 소개), 연구 발표, 데모 등 다양한 세션으로 구성되어 있습니다. 파트1은 헬스케어 및 생명과학 분야의 AI, 파트 2는 딥러닝으로의 의료 연구 가속화, 파트 3은 바이오 및 임상분야의 AI 를 다룹니다. 상세 정보는 다음과 같습니다.
파트 1: 헬스케어 및 생명과학 분야의 AI
세션 1(AI와 생명과학의 융합):NVIDIA의 글로벌 헬스케어 리더들과 함께 NVIDIA 최신 기술과 생태계의 혁신, 향후 의료 서비스의 미래에 대해 알아봅니다.
세션 2(딥 러닝과 영상 의학):딥 러닝의 핵심, 생명 과학 분야의 획기적인 애플리케이션과 더불어 NVIDIA 컴퓨팅 플랫폼이 고성능 딥 러닝 시스템의 개발을 지원하는 방법을 소개합니다.
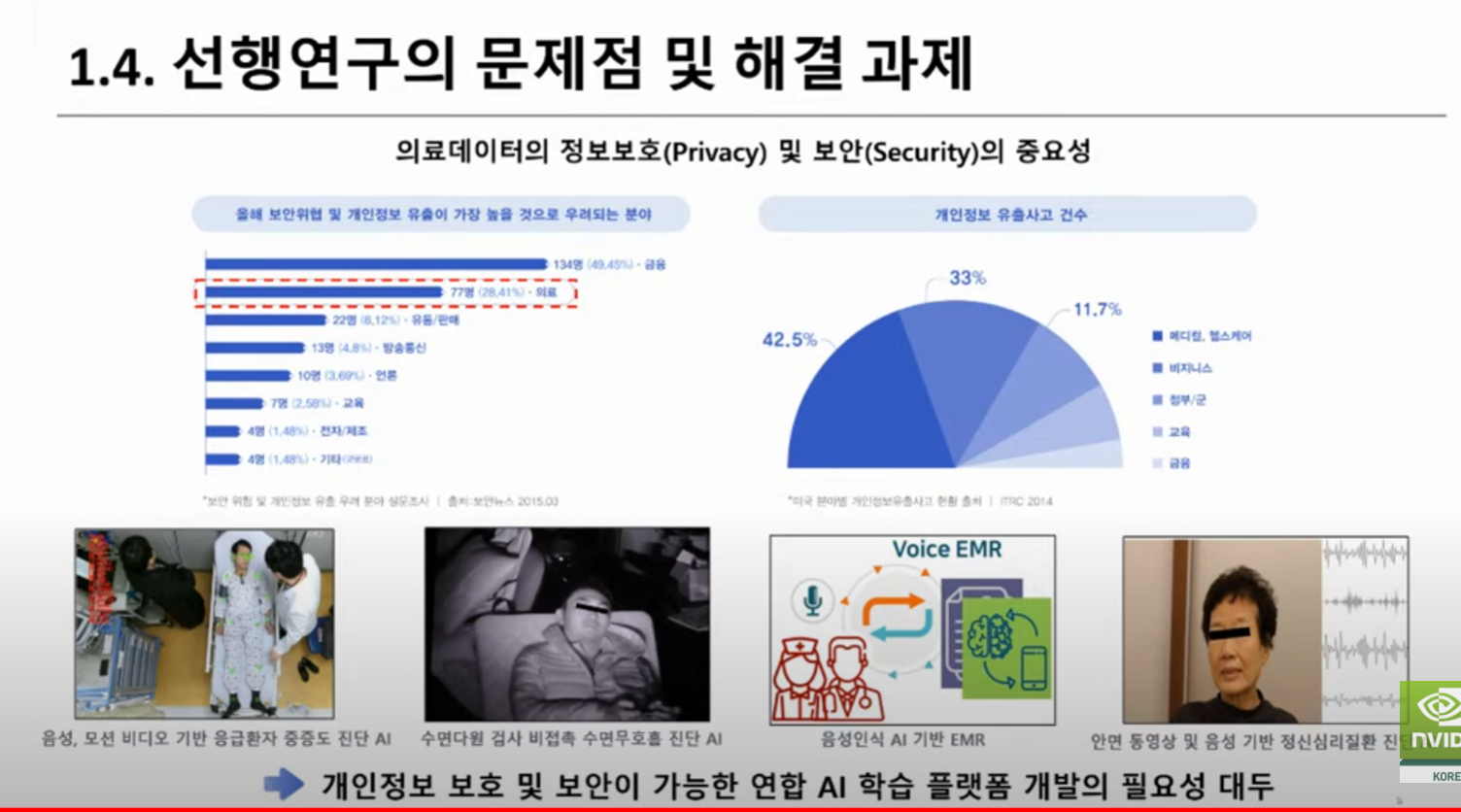
세션 3(연구개발 혁신을 위한 오픈소스 기반 구축하기):의료 이미징을 위한 개방적 혁신을 이끄는 ‘프로젝트 MONAI’와 연합학습 플랫폼인 NVIDIA FLARE가 의료 분야에서 고립된 데이터 문제를 극복하고 협업, 개인 정보 보호 AI 모델을 구축하는 데 어떻게 중요한 역할을 하는지 공유합니다.
세션 4(SNUH 연구발표 – 임상의가 바라보는 AI):실제 연구 사례와 함께 임상적으로 새로운 정보를 제공할 수 있는 AI 모델에 대해 논의합니다.
파트 2: 딥 러닝으로의 의료 연구 가속화
세션 1(HCLS 워크로드를 위한 가속화 컴퓨팅(GPU 컴퓨팅 플랫폼)):참석자들이 의료 분야의 저전력 임베디드 기기부터 데이터센터에 이르기까지 실제 활용 사례를 공유하면서 다양한 문제를 해결하기 위한 올바른 솔루션을 올바른 이해를 돕습니다.
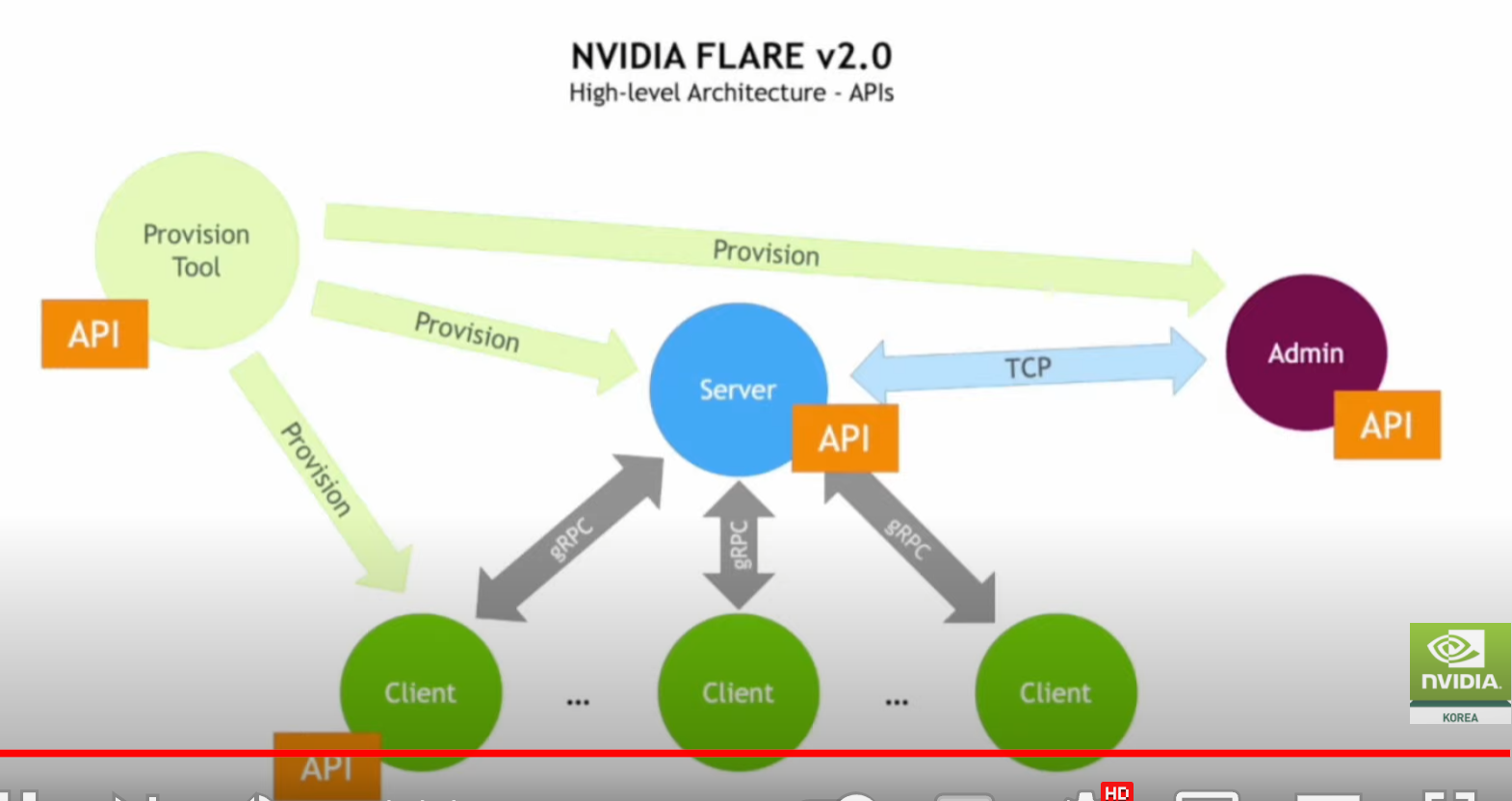
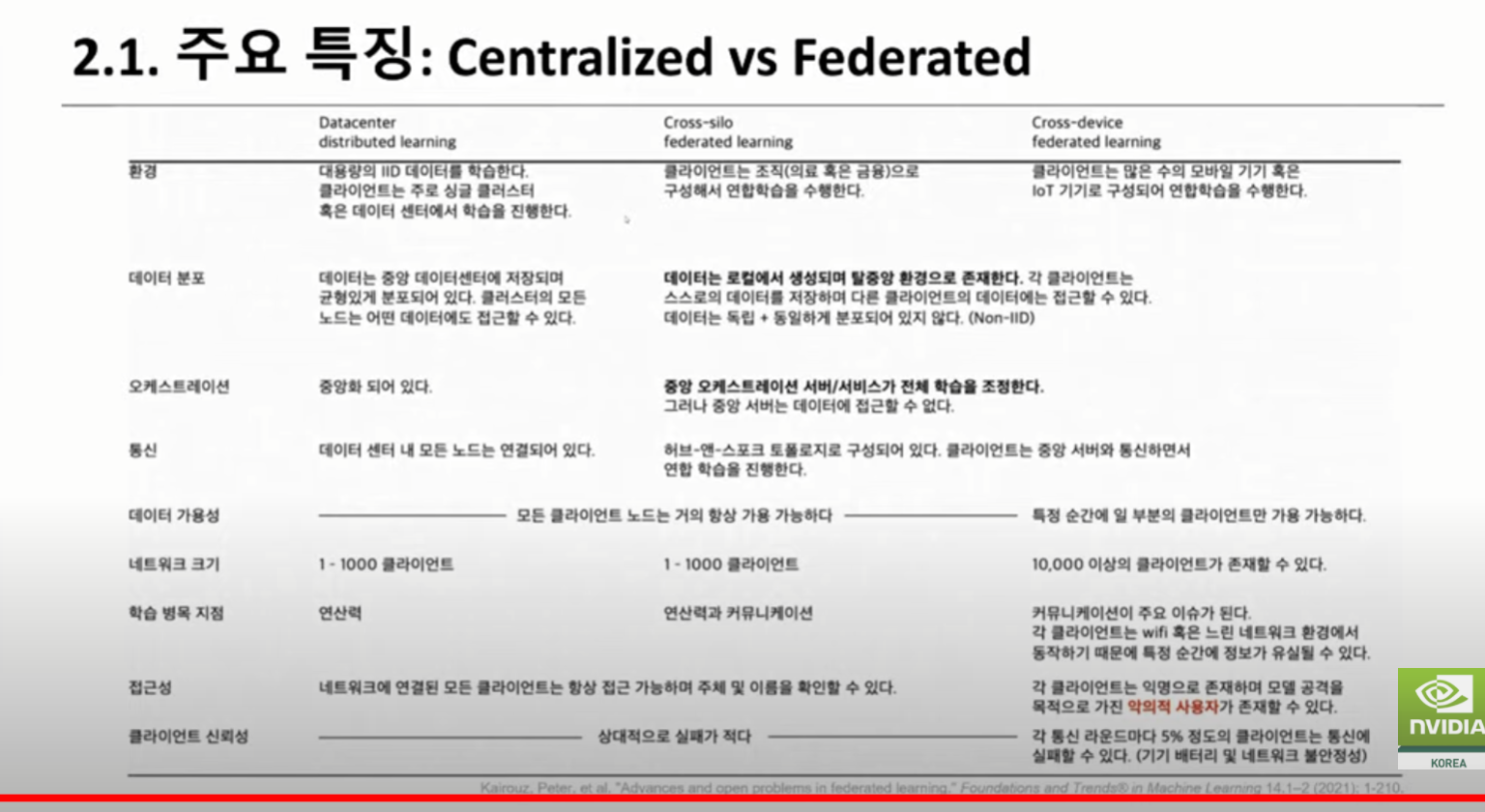
세션 2(연합 학습을 통한 의료 AI 및 연구 혁신):안전한 분산형 멀티 파티 협업을 지원하는 오픈 소스 플랫폼인 NVIDIA FLARE를 핸즈온 레벨에서 소개합니다. 연합 애플리케이션을 신속하게 개발할 수 있는 주요 기능과 워크플로우와 더불어 플랫폼의 실제 적용 분야에 대해 논의할 예정입니다.
세션 3(SNUH 연구발표 #2 – 연합학습 관련 연구 사례):실제 의료 환경에서 개인 정보 보호를 위한 의료 데이터 연합 학습 연구 발표를 진행합니다.
파트 3: 바이오 및 임상 분야의 AI
세션 1(생명과학을 위한 인공지능: 단백질 구조 예측의 미래):인간의 언어를 이해하기 위해 개발된 자기 지도방식의 자연어 처리 모델은 최근 단백질과 같은 생체 분자의 구조와 기능을 이해하고 예측하는 데 도움이 되고 있죠. 본 세션은 이와 관련해 최근 몇 가지 업데이트와 모델 아키텍처를 리뷰하고 생명과학 산업 발전에 필요한 툴, 기술 및 인프라를 살펴봅니다.
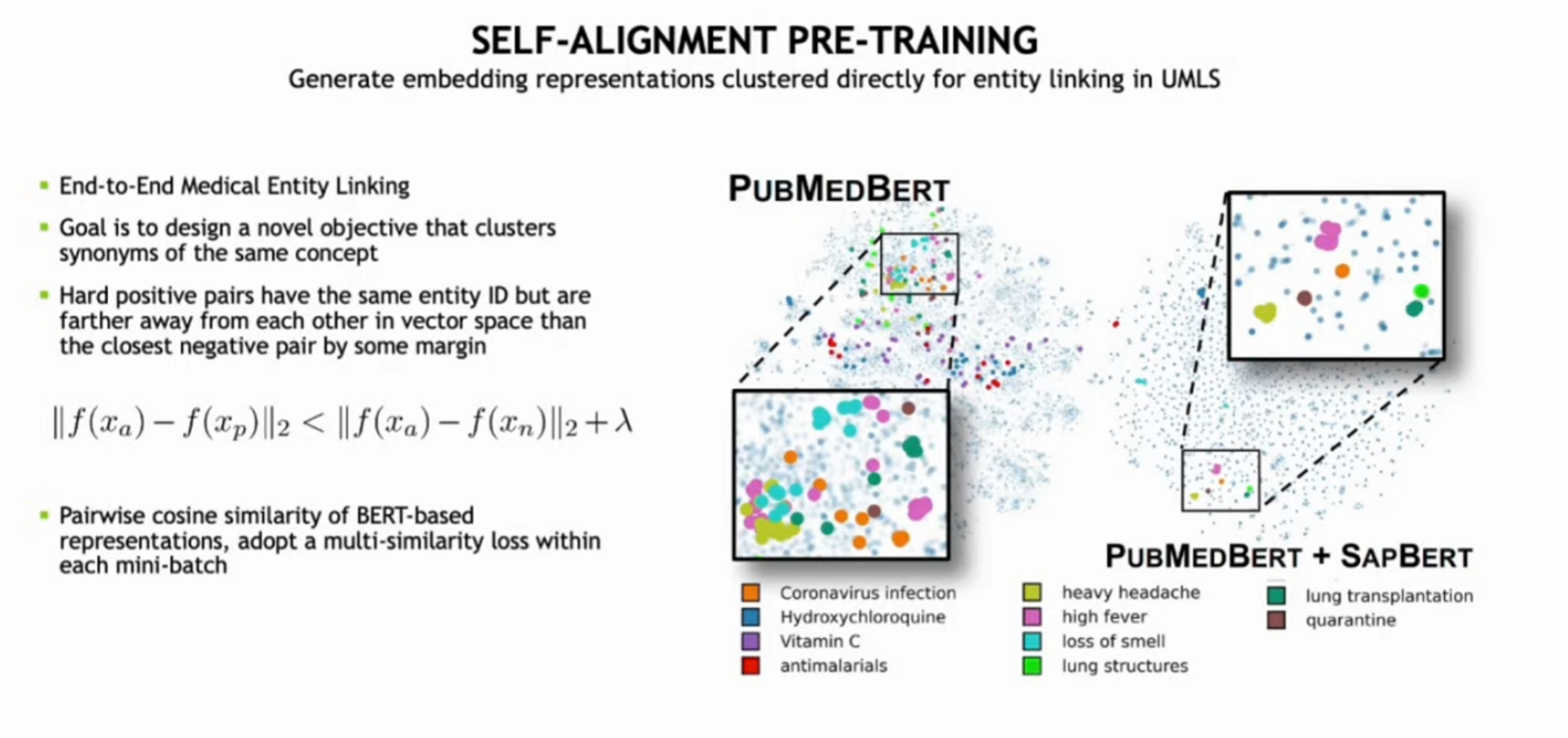
세션 2(바이오메디컬 및 임상 분야의 지식 추출 및 검색):NVIDIA가 지원한 고유한 임상 음성 및 텍스트를 위한 도메인별 트랜스포머 NLP 모델 아키텍처 프로젝트를 공유하고, 지식 추출 파이프라인을 통해 약물 대상 식별 및 우선순위 지정, 임상 시험의 구조화, 의료 코딩 및 엔터프라이즈 서치와 같은 다양한 사용 사례를 어떻게 지원하는지 보여줍니다.
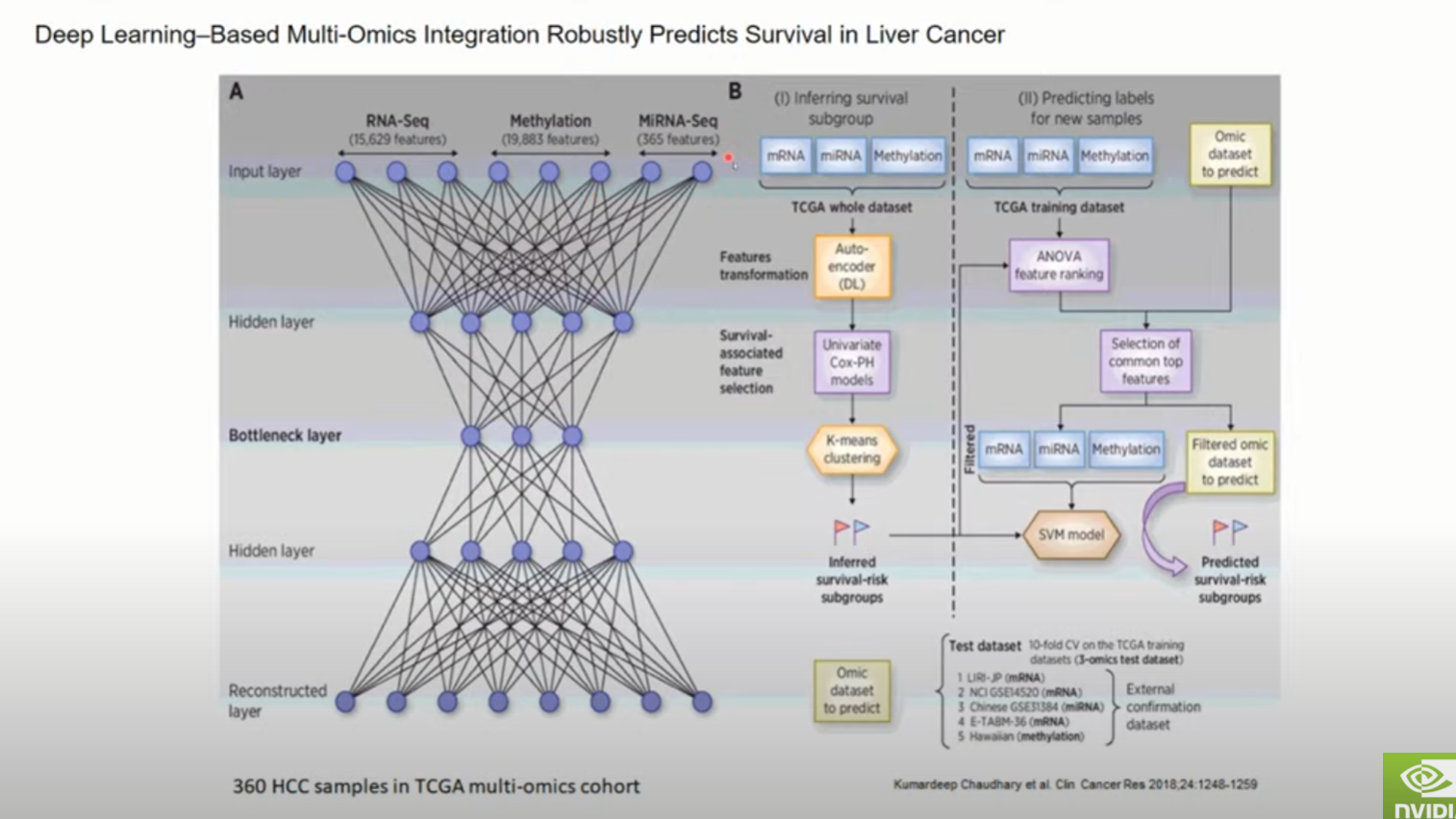
세션 3(SNUH 연구발표 #3 – Bio 관련 ML/DL 연구 사례):정상인과 코로나 확진자들의 생명자원을 분양 받아 생성한 7개 종류의 멀티오믹스 데이터(scRNA-seq(BCR/TCR), Cytokine Profiling, Bulk TCR/BCR-seq, SNP array, WGS, HLA-typing, COVID-seq)를 통합 분석하고 정상인, 경증 및 중증환자 분류모델을 개발하고자 합니다. 코로나19 세포 반응(COVID-19 cellular response) 네트워크를 통해 중증도 예측 그래프 신경망(GNN) 모델을 구축하고, GNN 결과에 대해 설명가능한 인공지능(explainable artificial intelligence, XAI)을 활용하여 바이오마커 후보를 발굴하고 생물학적 의미를 도출하고자 합니다.
해당 강연의 모든 세션이 제가 관심있는 부분이어서 강연을 듣게 되었습니다.
강연 신청을 조금 늦게해서 별도의 참여 링크 없이 NVIDIA korea 유투브로 들을 수 있었고, 오전 10시부터 오후 5시까지 다양한 주제로 강연이 진행되었습니다.
강연이 자막 없이 영어로 스피디하게 진행되어서 내용을 완벽히 이해하기 힘들었기에, 최대한 내용을 기록해두고 나중에도 차근차근 다시 읽어볼 목적으로 글을 남깁니다.
각 강연의 내용(PPT)과 함께 해당 세션의 사전 질문 내용과 답변을 기록해두었습니다. 모든 내용이 기록되어있는것은 아니며, 일단은 PPT만 기록해두었는데 추후에 시간이 되면 간략한 보충글도 적어볼 예정입니다.
개회사
Part 1. 헬스케어 및 생명과학 분야의 AI
1-1. AI 와 생명과학의 융합/ 르네 야오
[사전질문 및 답변]
(사전질문 1) Cloud 방식으로 활용 가능한 서비스가 있는가요?
(사전질문1 답변) 예, Clara, Monai, Rapids와 같이 클라우드에서 사용할 수 있는 SDK/서비스가 많이 있습니다. (Colleen)
(사전질문 2) 인공지능 관점에서 NVIDIA가 가장 유망하다고 보는 의료 관련분야는 무엇이고 관련해 개발 중인 유망 기술들은 어떤게 있을까요?
(사전질문2 답변) Radiologists의 행동으로서 의료 이미지 분류, 세분화 및 감지 기능을 제공합니다.
(사전질문3) 임상에는 아직 AI가 도입되지 못하는 것으로 알고 있습니다만, 향후에는 AI가 직접 임상에도 사용이 되려면 어떤 부분이 중요할까요? 그리고 의료에서의 AI 정확도는 꽤나 높지만 적용까지는 더디게 진행되고 있다고 생각하는데 어떤 부분이 가장 해결되어야 할 부분이라고 생각되시는지 궁금합니다.
(사전질문 4 답변) 기존의 기계 학습 방법 외에도, NLP 및 VAE 모델과 같은 많은 DL 모델이 신약 개발 과정에 사용되었습니다 (Colleen)
(사전질문5) NVIDIA가 보유하고 있는 의료관련 플랫폼의 활용 사례가 궁금합니다.
(사전질문5 답변) NVIDIA Clara는 AI 기반 이미징, 유전체학, 스마트 센서 개발 및 배치를 위한 의료 애플리케이션 프레임워크입니다. 여기에는 개발자, 데이터 과학자 및 연구자를 위한 풀 스택 GPU 가속 라이브러리, SDK 및 참조 애플리케이션이 포함되어 있으며, 실시간, 보안 및 확장 가능한 솔루션을 만들 수 있습니다.
(사전질문 6) 저희는 반려동물의 건강과 관련한 AI Service를 준비하고 있습니다. 인간보다 신체의 크기가 작은 반려동물의 경우에도 NVIDIA의 기술을 어떻게 활용할 수 있는 지 알고 싶습니다.
(사전질문6 답변) NVIDIA의 기술은 사람과 애완동물 모두에게 사용될 수 있습니다. 이 두 가지 차이는 데이터 정의와 작업 정의이지만 사용되는 기술은 동일할 수 있습니다.
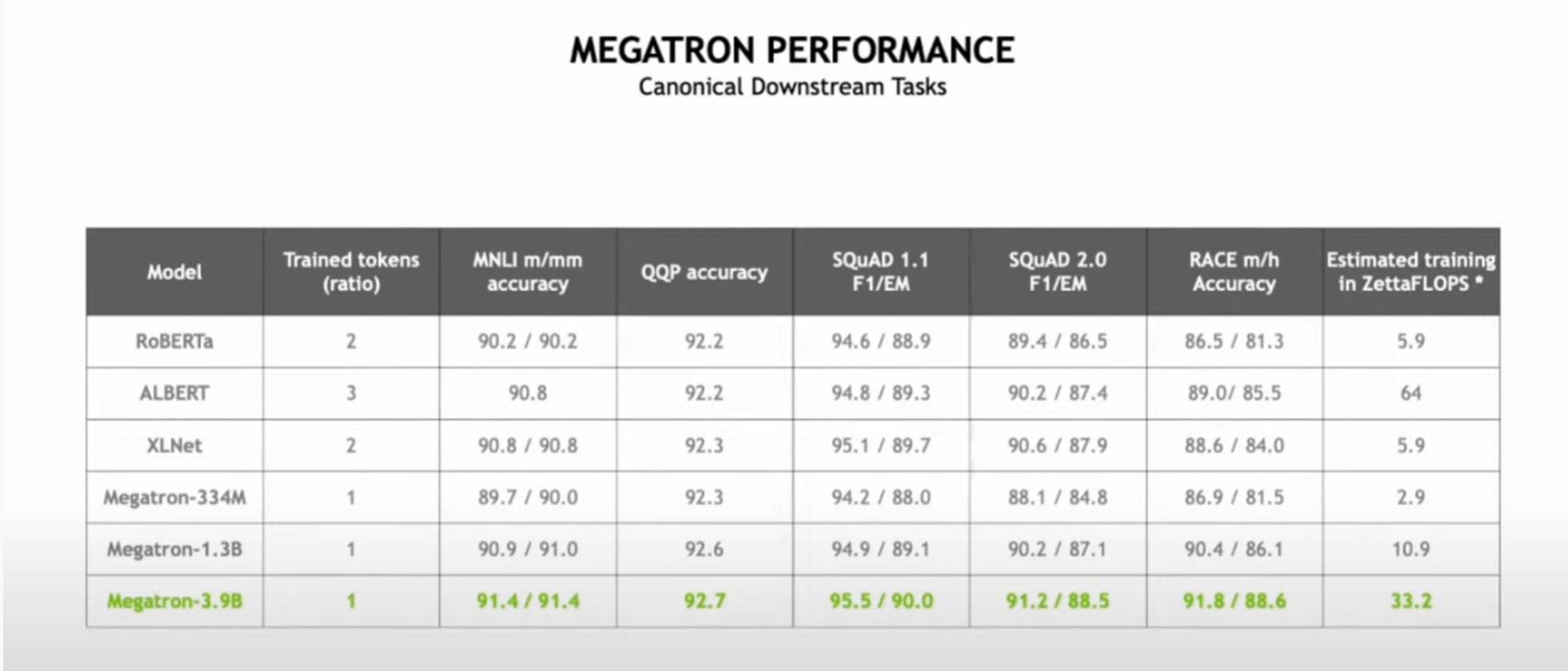
(사전질문7) 유전자 염기서열을 분석하고 특정 약물과의 투약에 대한 상관관계를 알아내고자 할 때, Transformer를 사용할 수 있습니다. 이 때, Megatron-LM과 같이 거대 모델과 이를 위한 학습 방법을 도입하는 것이 항상 유효한지 궁금합니다.
(사전질문7 답변) 데이터 집합 규모에 따라 다를 수 있습니다. 대규모 데이터가 있는 경우 거대 모델이 정확도에 더 많은 이점을 가져다 줍니다.
1-2. 딥 러닝과 영상 의학/ 싯다르트 코트발
DNN(feed-forward), CNN, RNN, Transformers. Graph Neural Networks, GAN
[사전질문 및 답변]
(사전질문1) 대부분의 인공지능은 설명할 수 없습니다. 의학 영상에서 가장 중요한 것을 설명할 수 있는 가능성입니다. 인공지능의 신뢰성을 어떻게 극복해야 하는지 조언해주시면 감사하겠습니다.
(사전질문1 답변) AI 모델의 설명에 대한 연구가 있는데, 이것은 사람들이 모델이 정말로 그들이 기대했던 대로 학습하는지 이해할 수 있도록 도와줍니다. 또한 트레이닝에 다양한 데이터를 사용하면 모델의 신뢰성이 향상될 수 있습니다.
사전질문2) 디지털 X선, CT 및 MR과 비교했을 때, 높은 실시간/낮은 지연 요구 사항이 있는 초음파 영상은 딥 러닝의 적용이 제한적일 수 있습니다. 특히 고성능 HW를 장착할 수 없는 핸드헬드 초음파 영상 장비의 적용 가능성은 얼마나 됩니까?
(사전질문2 답변) NVIDIA에는 휴대용 기기에 사용할 수 있는 HW 플랫폼이 내장되어 있습니다. 또한 TRT 및 Triton과 같은 몇 가지 SW 최적화 도구를 사용하여 고성능 없이 DL 애플리케이션을 HW에 적합하게 만들 수 있습니다.
(사전질문3) 딥 러닝의 문제는 계산하는데 오랜 시간이 걸린다는 것입니다. 우리는 현재 NVIDIA의 고급 GPU를 사용하는 것을 선호하지만, 앞으로는 더 빠른 양자 컴퓨터를 보게 될 것입니다. NVIDIA의 양자 컴퓨팅 계획은 무엇입니까?
(사전질문3 답변) NVIDIA는 양자 컴퓨팅에 관한 몇 가지 작업을 가지고 있습니다. 우리는 방금 GPU에서 양자 시뮬레이션을 하는 데 사용할 수 있는 cuQuantum이라는 SDK를 발표했습니다.
1-3. 연구개발혁신을 위한 오픈소스 개발 / 프레나 도그발
[사전질문 및 답변]
(사전질문 1) 한국에서 FLARE 적용사례가 있는지 궁금하고, 의료 분야에서 federated learning 적용시 기술과 제도적인 관점에서 이슈가 되는 사항들이 어떤게 있는지 궁금합니다
뇌영상 -> 정성적이 아닌, 정량적인 objective signature score -> 다양한 기능 수행 가능
- rethink Data features.
Image is not image.
의료 영상들은 모두 connection이 되어 있다.
한 사람에게도 다양한 data 존재
레이블 작업 없이 만들기
서로다른종류 multimodal 합쳐서, 유용한 insight를 찾음으로써 유용성..
사람이 레이블링 X 다양한 데이터를 합쳐서 레이블링해서 self-supervise learning. (단순 supervise learning X)
[사전질문 및 답변]
(사전질문 1) 희귀병 등에 대한 원인 추적 등은 위험이 따를 수 있고 데이터가 부족할 수 있습니다. 또, 바이러스 변이와 백신 연구는 곧 특허전쟁부터 무기의 개발로까지 변질될 수 있습니다. 새로운 정보를 얻어낼 때, 정보에 대한 증명과 연구과정에서 부작용을 최소화할 방안은 무엇이 있나요? 어떤 방식으로 학습시키고 어떤 정보를 추출할 지 궁금합니다.
(사전질문 1 답변) Rare disorder 등에 대한 AI 는 여러모로 고민이 될 수 밖에 없는 부분입니다. 대규모 데이터기반으로 만들어지는 현 시점의 AI모델을 고려할 때, Rare disorder를 model이 알아내는 것도 어려운 문제일 뿐더러,
이를 위한 최선의 management를 위한 여러 형태의 AI , Data-driven method를 만들기에 어려움이 있습니다. 우선 Rare disorder에 대한 identification 부분은 강의에서 다루겠지만,
단순한 supervised learning이 아닌 data에 집중하는 unsupervised learning과 data distribution에서 접근함으로서 해결할 부분이 있습니다.
Rare disorder를 치료하고 타겟찾는 등의 일은 적은 수의 data를 극복할 수 있는 여러 technical한 부분이 적재적소에 들어가야할 듯 합니다. 예를들면 Zero-shot, few-shot learning등이겠습니다.
(사전질문 2) 딥러닝이 기존에 전공의나 임상의가 하던 일을 대신하면 사람은 어떤 일에 집중하게 되나요? 또 지금 딥러닝이 대신 해주는 분야에 대한 지식이나 인사이트는 어떻게 얻게 될까요? 요즘 혈압 측정 기기가 있어, 간호사도 수동 혈압측정기를 잘 못쓰시더라고요. 그러나 그런 기기가 없거나 딥러닝 제품을 사용하기 어려운 곳에서도 환자는 있게 마련이어서요.
(사전질문 2 답변) 딥러닝으로 일부의 일이 줄어드는 부분은 있겠으나, 현 단계에서는 많은 일을 대신해주어 업무가 완전히 재배치될 만큼의 모습은 보기 어려울 듯 합니다. 진단 support system의 일부에서 업무량이 줄어드는 정도이고,
결국은 오히려 AI가 생산하는 새로운 정보가 또다른 해석과 진료에 활용되는 방향으로 흘러가기 때문에, 사람이 처리해야하는 정보량이나 일의 양이 줄어들지는 않을 듯 합니다. 물론 먼 미래에 사람의 행동과 사고판단까지 모사하는 기술들, 즉 강인공지능이만들어진다면 모르겠습니다만, 이부분은 현재 논의할 단계는 아닌 것 같습니다.
딥러닝이 대신해주는 분야에 대해 우리가 지식을 꼭 가져야하는가로 질문이 귀결될 수 있을 듯 합니다. 우리에겐 원리가 필요하지 작동원리를 다시 설계해갈 필요는 없습니다. 기술의 발전으로 인해 과거의 행위들에 대한 숙련도가 떨어지는 현상은 자연스러울 수 있습니다. 또한, 이런 기술발전이 사회적 격차를 만들 수 있다는 것도 잘 알려져있습니다.
하지만, 이 역시도 기술이 극복할 수 있는 영역이 있습니다. 오히려 더 많은 부분에서 기술로서 극복하는 사례가 더 많습니다. 예를들어, 안저검사의 경우 미국의 rural area에서는 DL 기반의 장비가 안과전문의를 만나기 어려운 지역에서 screening역할을 할 수 있도록 만들어지고 있습니다.
(사전 질문 4) AI의 설명 가능한 정도와 임상 의사의 AI에 대한 신뢰 수준의 관계가 궁금합니다.
(사전 질문 4 답변) explainability가 의미하는 바는 매우매우 넓습니다. 짧게는 CAM 과 같이 어느 영역을 보고 판단했는지를 의미하는 것 부터, 어떻게 추론했는지를 파악하는 것 등 매우 넓은영역입니다. 임상에서 중요한 것은 그런데, '합목적성' 입니다.
예를들어, CT영상을 보고 특정항암제에 잘 들을 수 있을지 예측하는 모델을 만들었다고 할 때, 이는 explainability가 없습니다. 그런데 기존에 잘 알려진, 해당항암제의 치료반응을 결정하는 PD-L1이라는 마커가 존재하고, CT영상을 통해 이를 예측할 수 있다고 하면 중간연결고리가 생기면서 설명가능성이 발생합니다.
즉, AI가 추구하는 방향은 이러한 detail한 합리적인 추론으로 만들어갈 수 있느냐에 있습니다. 또한, 의사는 환자를 살리기위해서 어떠한 설명가능한 이유보다, 근거가 중요합니다. 즉 어떤 약제가 효과적인지를 판단할 때 물론 기전도 중요하지만, 최종적으로는 기존 약제보다 더 낫다라는 임상적 근거, 즉 임상시험에 의한 근거가 1순위 입니다.
Part 2. 딥 러닝으로의 의료 연구 가속화
2-1. HCLS 워크로드를 위한 가속화 컴퓨팅/ 콜린 컴퍼스
[사전질문 및 답변]
(사전 질문 1) 클라우드 접근 방식 인가요?
(사전 질문 1 답변) NVIDIA 헬스케어 플랫폼은 온프레미스 및 클라우드 두가지 방식으로 활용 가능합니다.
(사전 질문 2) 어느정도 규모의 컴퓨팅 시스템을 활용하시나요?
(사전 질문 2 답변) 워크로드의 크기에 따라 다릅니다.
(사전 질문 3) 가속 컴퓨팅을 효과적으로 활용하는 데 NVIDIA의 컴퓨팅 플랫폼을 적용하는 방법에 대해서 질문드립니다.
(사전 질문 3 답변) NVIDIA 컴퓨팅 플랫폼에는 세 가지 계층이 있습니다. 하드웨어, GPU에 최적화된 범용 가속 소프트웨어 및 특정 도메인용 소프트웨어가 함께 작동하여 컴퓨팅을 효과적으로 가속합니다.
(사전 질문 4) HCLS 워크로드의 속도는 어느정도이며, 구축시 소모되는 비용이나 필요 사항들은 무엇이 있을까요?
(사전 질문 4 답변) 상황에 따라 다르지만 일반적으로 HCLS 워크로드가 몇 배, 수십 배 또는 심지어 더 빠릅니다. 비용은 하드웨어 부분일 뿐이며 99%의 소프트웨어는 되어오픈 되어있으며 무료로 사용할 수 있습니다
(사전 질문 5) 가속화컴퓨팅을 위해서는 컴퓨터의 성능이 하이엔드급의 사양을 요구하게될텐데 엔비디아에선 이부분에 대해 특정 플랫폼이나 기존 그래픽이 아닌 맞는 제품을 별도로 개발하고 있나요?
(사전 질문 5 답변) 아니요. 개발자와 연구자가 작업을 가속화하기 위해 그래픽, 플랫폼, 사전 교육된 모델 및 데모 스크립트를 개발하지만 최종 제품이나 애플리케이션은 제공하지 않습니다.
사전 질문 6) 수백만 개의 분자를 처리하고 수백 가지의 잠재적인 약물을 선별하기 위해 컴퓨팅을 어떻게 가속화할 수 있습니까?
(사전 질문 6 답변) AI 및 HPC 도구를 사용하여 약물 발견을 수행할 수 있으며, NAMD, AMBER 및 AutoDock과 같은 많은 도구를 통해 GPU에서 가속할 수 있습니다.
2-2. 연합 학습을 통한 의료 AI 및 연구 혁신 / 크리스토퍼 커스텐
[사전질문 및 답변]
(사전 질문 1) 대표적인 데이터 관리 기법은 무엇인가요?
(사전 질문 1 답변) 기존 데이터 및 새로운 데이터에 대한 액세스를 단순화합니다.SPARK와 도커를 잘 활용하고 있습니다.
(기타 질문 )Flare 는 Platform independent 한가요? Nvidia machine 이 아니어도 동작 하나요? Mobile 이 client 인 경우도 고려되고 있나요? /NVIDIA의 Flare는 Flare 안에 구현되어있는 ML/DL 알고리즘 등만 사용할수있는게아니라 제가 원하는 모델들을 제한없이 이용할 수 있는 건가요?
(사전 질문 2) Federated Learning과 중앙집중형 처리의 모델 성능을 대규모 데이터에서 비교해 본 사례가 있는지, 또한 작업의 배분, Workflow Monitoring이 플랫폼 상에서 어떻게 이루어 지는지 궁금합니다.
사전 질문 2 답변) 예, FL과 데이터 중앙 집중화의 성능을 비교했습니다. 초기에는 FL이 사이트의 일부 매개 변수만 집계했기 때문에 성능이 떨어졌으나 수백 번의 에포크 후 데이터 중앙 집중화 케이스와 거의 동일한 성능을 달성했습니다. 우리는 ADMIN API를 가지고 있으며,수석 연구원이 이를 사용하여 플랫폼의 작업을 모니터링할 수 있습니다.
사전 질문 3) API 기반 연동외에 사전 개발적용된 도구나 툴킷도 제공되는지 궁금합니다.
사전 질문 4) 1) 의료 태스크는 개인정보에 민감하기에 로컬 디바이스의 데이터를 중앙으로 공유하지않는 federated learning이 적합한 어플리케이션이라는 생각이 들지만, FL을 사용함으로써 생기는 performance degradation에도 불구하고 FL을 사용해야하는 장점이 궁금합니다.2) 의료데이터는 인종마다 특징이 다른데, semantic하게 유사한 이미지 외에 시퀀스 데이터 등은 인코딩했을 때 피처 레벨에서도 인종 간 유의미한 차이가 있을 수도 있다고 생각합니다. 이 경우 FL을 사용하면 클라이언트 간의 data distribution의 차이가 커서 학습이 제대로 안 될 수 있는 문제가 생길수 있을 것 같은데 어떻게 생각하시나요?
(사전 질문 1) 현재까지 crystallography를 통해 밝혀진 구조들은 생체내 존재하는 단백질중 극히 일부입니다. 대부분의 단백질은 세포막에서 발현되거나 crystalization이 힘든 단백질들이 대부분이며 이들이 질병에 굉장히 밀접한 단백질이지만, 구조를 밝히지 못하여 데이터 또한 존재하지 않습니다.
현재의 Alphafold와 같이 기존 데이터를 사용한 기계학습에서는 앞선 구조를 밝혀내지 못한 단백질의 특이적 feature들을 반영한 단백질 구조 예측 모델이 없는데, 이를 타계하기 위해서는 기존의 물리화학적 지식 및 생물학적 발생원리규명등 다양한 추가정보가 필요할 것으로 생각이 됩니다.
어떤 정보를 추가적으로 쓴다면 이러한 한계점을 넘을수 있을거 같으며, 이러한 한계점을 넘기 위한 새로운 모델 Architecture에 대한 생각이 궁금합니다.
(사전 질문 1 답변) 좋은 지적이에요. Dry lab과 Wet lab이 AI 약물 발견의 트렌드인 이유입니다. 생명공학은 DL 모델의 예측을 정확하게 검증하기 위해서는 둘 다에 의존해야 합니다.
(사전 질문 2) 자연어처리 모델은 기본적으로 방대한 언어 데이터 속의 규칙성을 파악하고, 추론하고자 하는 언어학적 시도를 전산적으로 구현한 것으로 배웠습니다. 아직 언어의 변화를 주도하는 원동력에 관해선 많은 부분이 안개 속에 있다고 언어학자들은 이야기합니다. 비록 자연어 처리 모델이 언어의 변화를 사용자에 앞서 예측할 수는 없지만,
현재 사용하는 언어의 컴퓨터적 구현을 통해 HCI적 이점이 크다고 알고 있습니다. 하지만 nvidia 단백질 구조 예측 시스템은 관련 문서상으로 보았을 때 아직 발견되지 않은 바이러스의 단백질 특성 등에 대한 예측을 목표로 하는 것으로 보입니다.
그렇기 위해선 기존의 자연어 처리 시스템보다 더 나아가, 변화의 원동력을 찾아낼 수 있는 시스템이 필요하다고 생각되는데, 아직까지는 이를 위한 이론적, 기술적 구현을 확인하지 못했습니다. 혹시 nvidia에서 위와 같은 내용에 대한 시도가 이루어지고 있는지 궁금합니다.
(사전 질문 2 답변) 질문자님께서 매우 정확히 이해하고 계십니다. 우리는 아직 이를 위해 노력하지 않고 있지만, 현재 주로 개발자와 연구자의 워크플로우를 가속화하기 위해 매우 큰 컴퓨팅 능력을 필요로 하는 최적화된 사전 교육 모델을 제공하는 SOTA 자연어 처리 모델을 학습하고 있습니다. 이론적 및 기술적 구현을 확인하는 데는 아직 시간이 필요합니다.
(사전 질문 3) 작년에 ALPHAFOLD로 상당히 깊은 인상을 받았다. 이것이 더 발전하여 물리/화학 작용으로 인한 변성까지 예측하는 것은 얼마나 시간이 걸릴 거 같은가
(사전 질문 3 답변) 알파폴드는 구글 딥마인드가 개발한 제품이라 정확한 답변을 드릴 수는 없지만 시간이 오래 걸리지는 않을 것으로 생각합니다.
(사전 질문 4) 자연어 처리 모델을 통해 크고 복잡한 단백질 구조를 이해, 예측할 수 있었던 방식이 궁금합니다 !
(사전 질문 4 답변) Openfold을 계속 활용해 주세요. 새로운 가중치로 AF2 모델을 재교육하여 보다 복잡한 구조를 예측할 수 있습니다.
(사전 질문 5) 단백질 구조를 이해하고 예측하는 데 자연어 처리 모델을 효율적으로 활용할 수 있는 방법에 대해서 문의드립니다
(사전 질문 5 답변) AlphaFold2와 RosettaFold의 다운스트림 응용에 이어 항체 설계, 표적 추출 등과 같은 많은 연구 논문들이 진행 중입니다.
(사전 질문 6) 그래프 신경망 단백질 구조 예측을 사용할 수 있는 것은 무엇일까요?
NVIDIA Korea(사전 질문 6 답변) 네, GNN은 단백질 구조 예측에 사용될 수 있습니다, 많은 논문에서 GNN이 해당 영역에서 잘 작동한다는 것을 보여주었습니다.
NVIDIA Korea(사전 질문 7) 예를 들어 AI상담센터를 운영하고자 할때 고객의 음성을 텍스트로 변환하고 고객의 요구에 맞는 답안을 도출한뒤 이를 다시 음성으로 변환하는데 있어서 가장 중요한 부분은 학습과 AI 엔진의 고도화일텐데요. NVIDIA 에서 이러한 비즈니스 모델에 적합한 솔루션을 소개해 주신다면 어떤 구성이 적절할지 문의드립니다.
(사전 질문 7 답변) 3가지 제안을 드립니다.
a. 고객이 AI에 대해 잘 알지는 못하지만 컴퓨팅 화학 분야의 적용법이 필요한 경우입니다. NVIDIA는 로코드 또는 코드가 없는 AIDD 솔루션을 사용하는 Schrodinger, AMBER, CyroSPARC와 같은 일부 ISV를 추천할 수 있습니다.
b. 고객이 HPC 및 AI에 익숙하다면 Linux 커맨드 라인을 통해 또는 DL 도커를 통해 활용할 수 있습니다. 그런 다음 고객이 NGC에서 Clara Discovery를 AF2, Rosetta, RF-design, molecularnet, openfold와 같은 인기 있는 도구와 함께 사용할 것을 권장합니다.
c. Customer가 HPC와 AI에 매우 강하다면 NVIDIA는 고객이 DL 모델을 공동으로 파인튜닝하거나 CUDA 커널을 최적화하도록 도울 수 있습니다.
(사전 질문 8) 주제가 신선합니다. 자연어 처리 모델의 어느 부분이 단백질 구조 이해/예측에 적용되었는지와 이 로직을 다른 어떤 분야에 활용가능할지 궁금합니다.
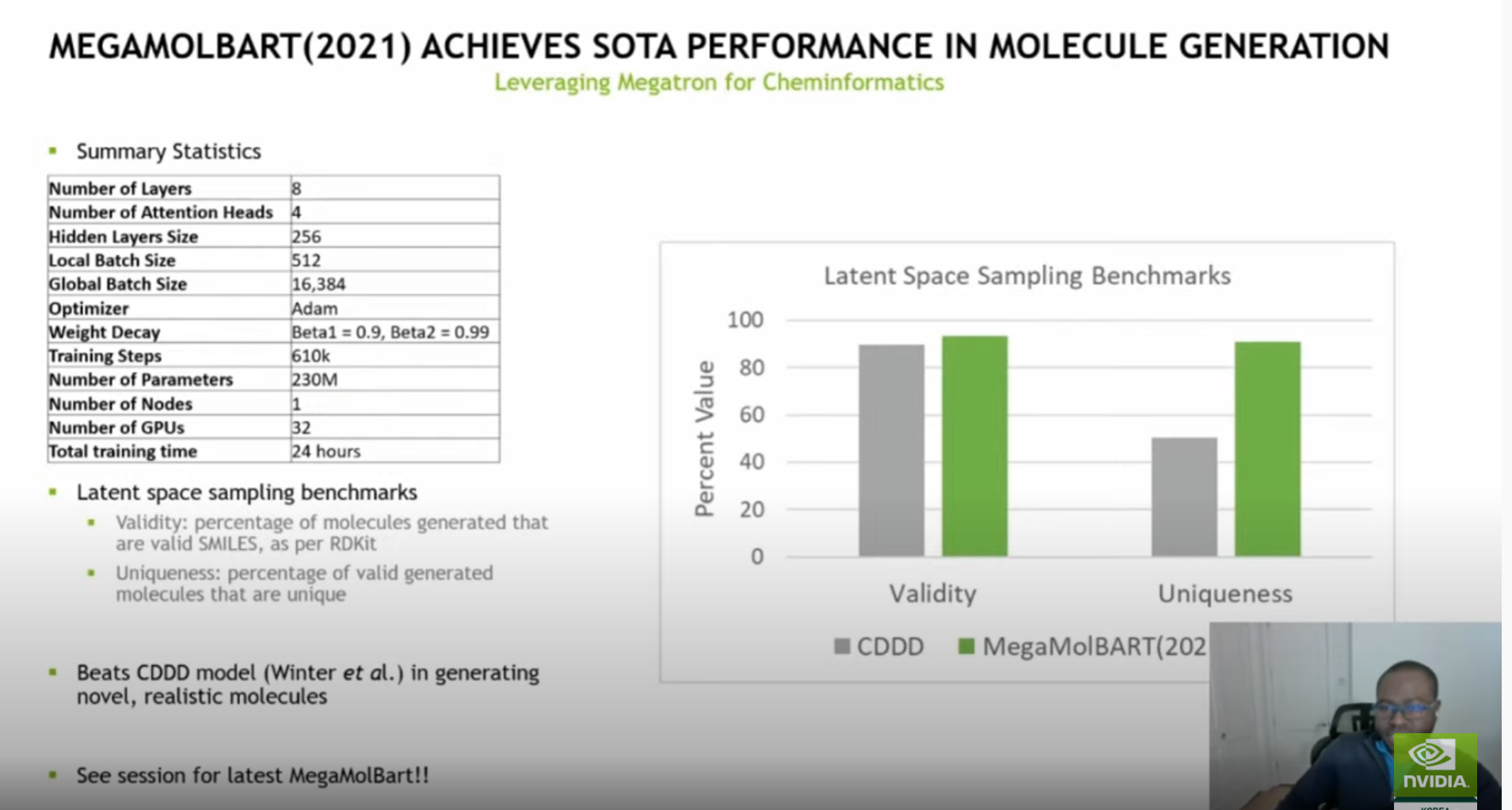
(사전 질문 8 답변) Clara Discovery부터 시작할 수 있습니다. 많은 CUDA 라이브러리는 HTS, Audodock, FEC, 분자 역학에 유용합니다. 그런 다음 트랜스포머에 크게 의존하는 알파폴드2의 논문과 코드를 주의 깊게 읽어 보십시오. 알파폴드2와 로제타폴드는 단백질 구조 예측에 가장 인기 있는 프레임워크입니다. RF-Design은 약물 발견의 Denovo 설계에서 가장 널리 활용되고 있습니다. 분자 생성 분야에서는 NVIDIA에 MegaMolBart가 있으며, moleculenet을 확인할 수도 있습니다.
3-2. 바이오메디컬 및 임상 분야의 지식 추출 및 검색/ 엔서니 코스타
-- future --
[사전질문 및 답변]
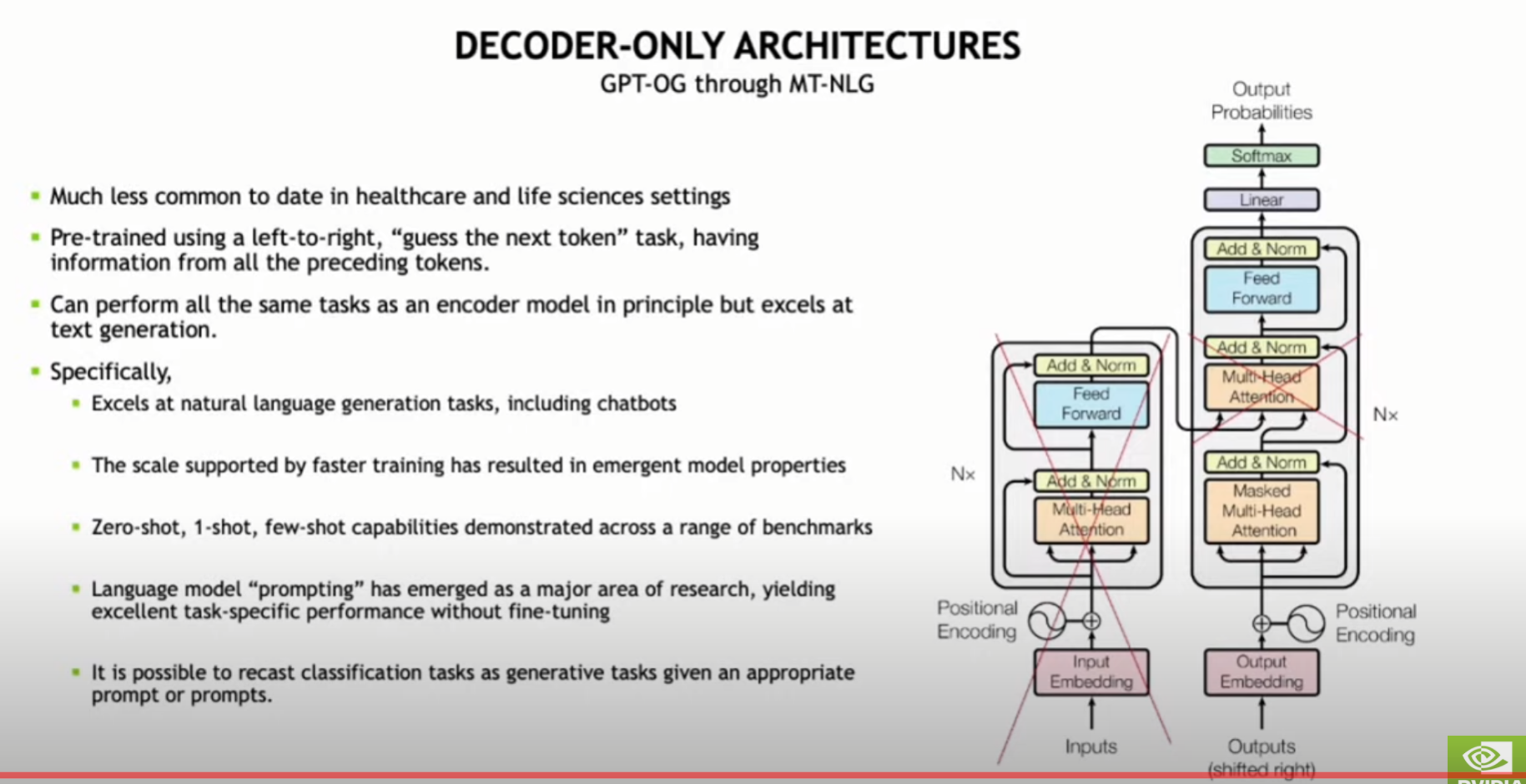
(기타질문) Transformer의 Encoder만 (BERT), Decoder만(GPT) 모델이 유명한데, 왜 둘 다 사용하는 모델이 지양되고, 이런 2가지 모델 형태로 분리되는건가요?
(사전 질문 1) 거대한 언어모델을 이용해야할 것같은데 NVIDIA에서 어떻게 제공해주고 그 비용은 어떠한지 궁금합니다.
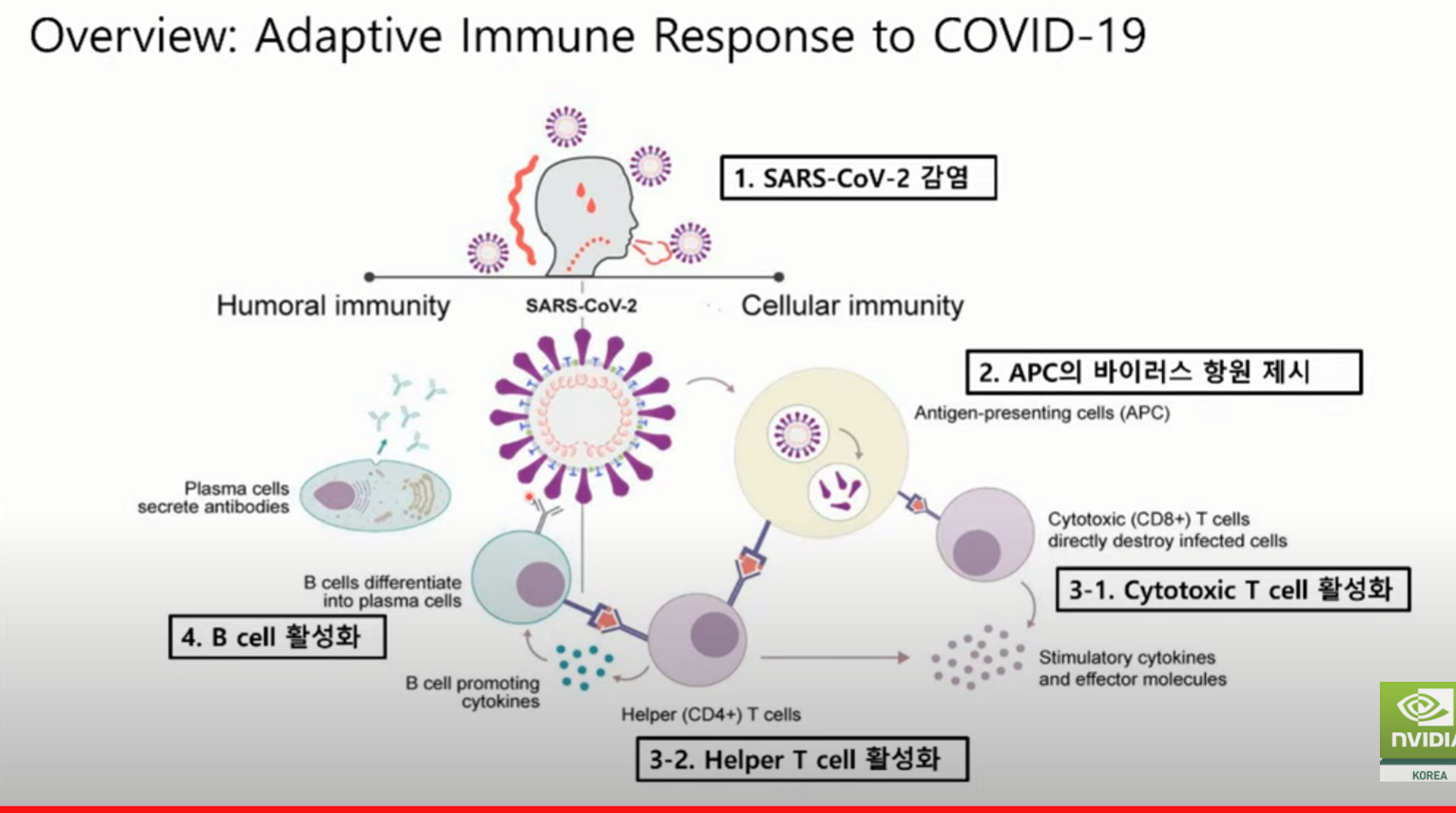
Multi-omics-based severity prediction model for COVID-19 patients.
<BackGround>
감염 -> 바이러스가 세포에 들어감 -> 쪼개져서 세포에 제시 -> 다른 세포들이 활성화되고, B cell 이 항체 만듬.
바인딩이 잘 되어야 중증으로 가지 않게됨. 바인딩 메커니즘에 문제가 생기면 중증 생긴다는 가정..
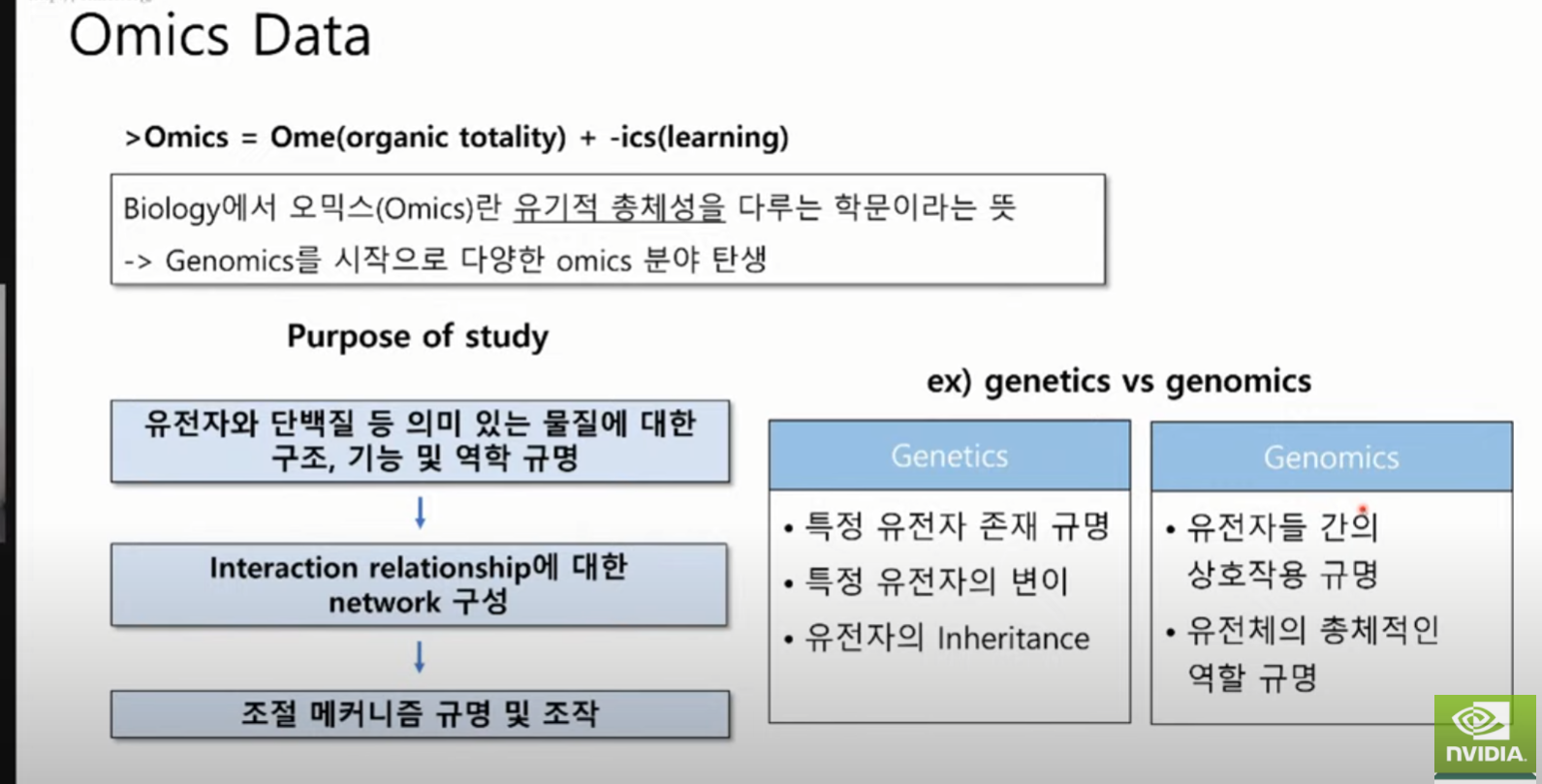
Omics : Total.
-- 선행연구 --
1.
암 전이된사람 vs 암 전이 안된사람 classification.
Gene Expresion + Protein-Protein interaction 정보 --> Graph 로 이용
2.
3.
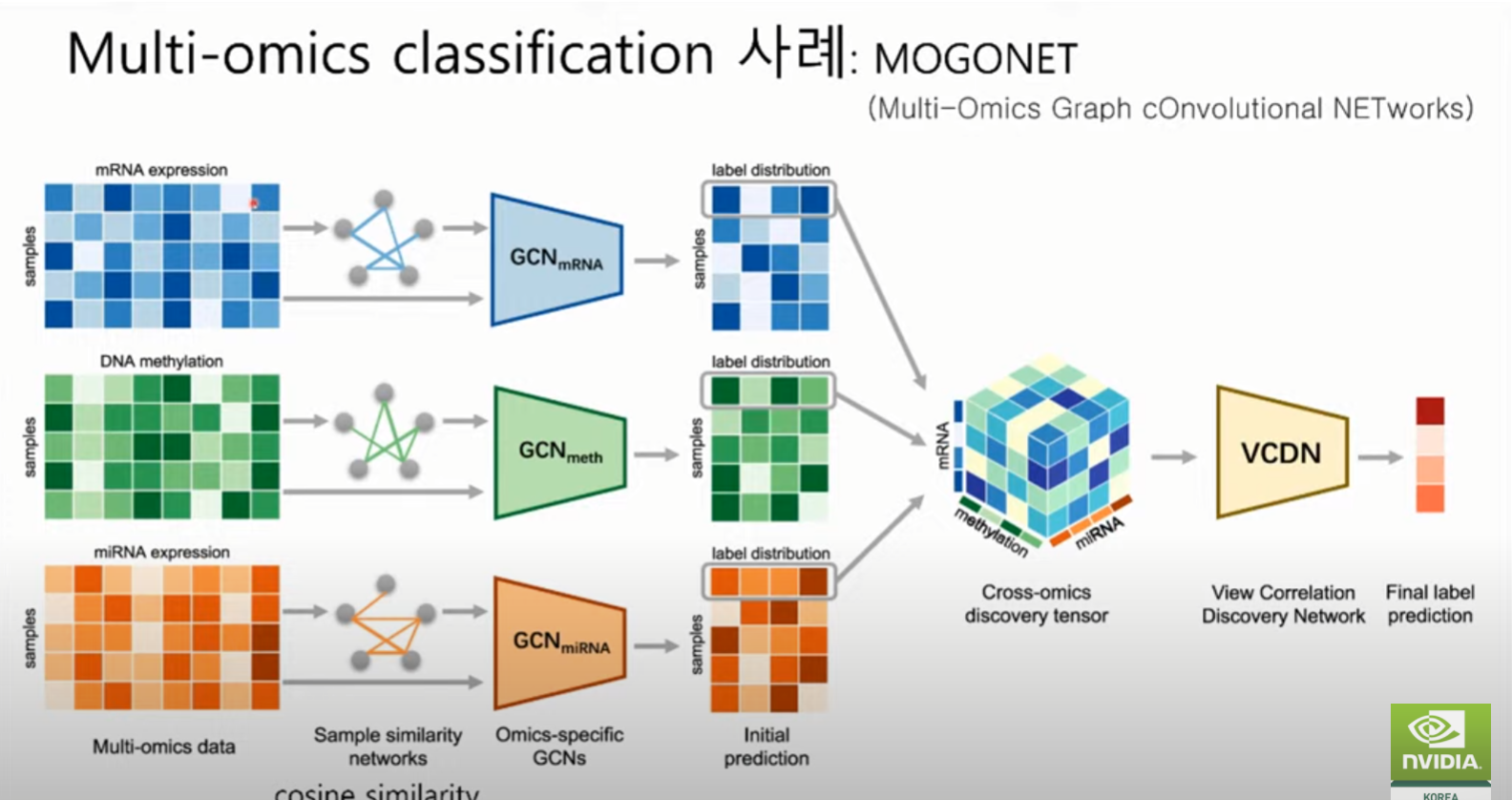
Omics 유사도 구해서, 네트워크 생성 (각각의 Omics 따로 구축한다는 한계)
Protein 유사도 구해서, 네트워크 생성
----> fusion, 하나의 네트워크로 통합 -> classification model & 유사 증상 환자 그룹화
4.
-----------------------
사용 Data
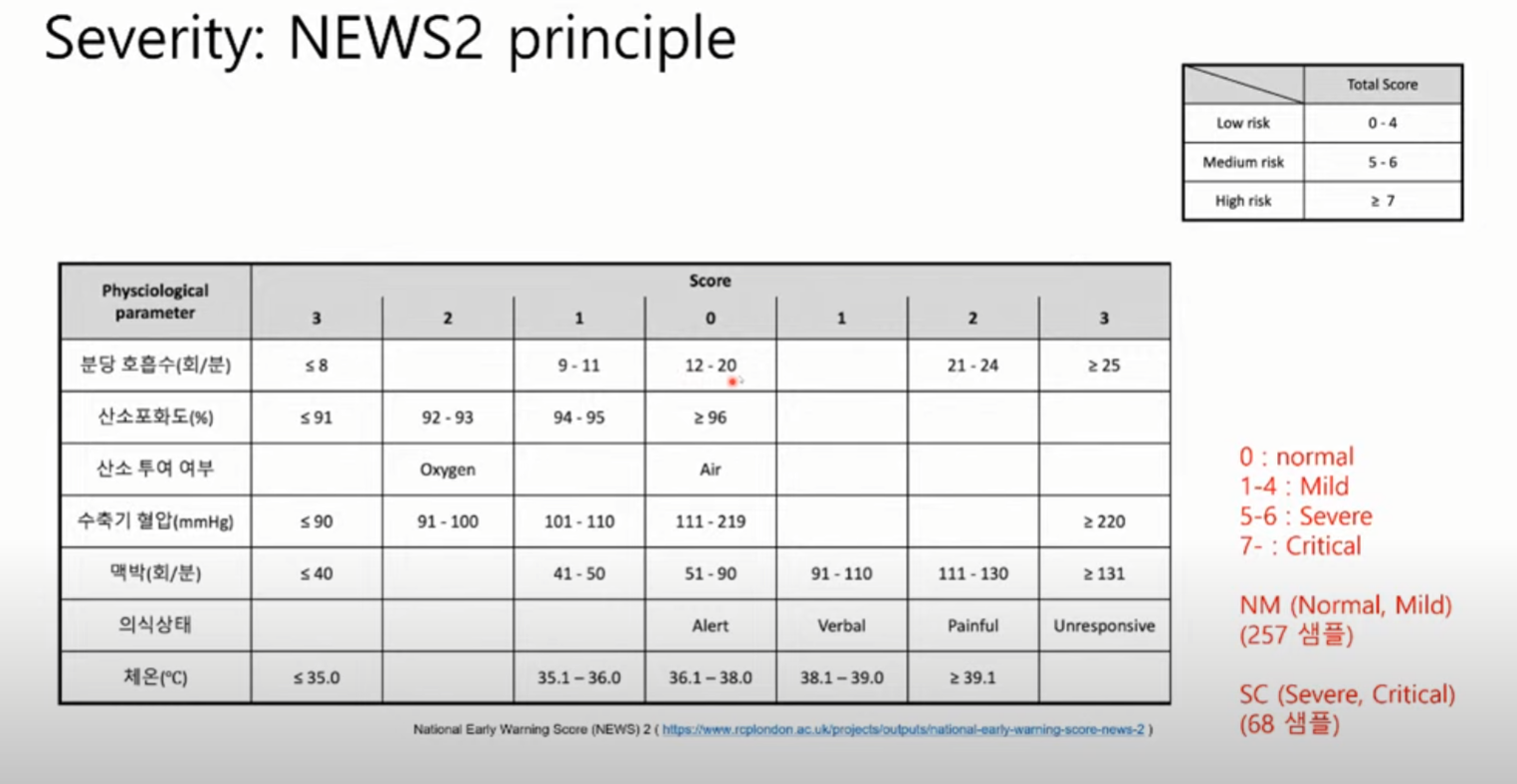
경증 vs 중증 구분 기준
------ 모델 구축
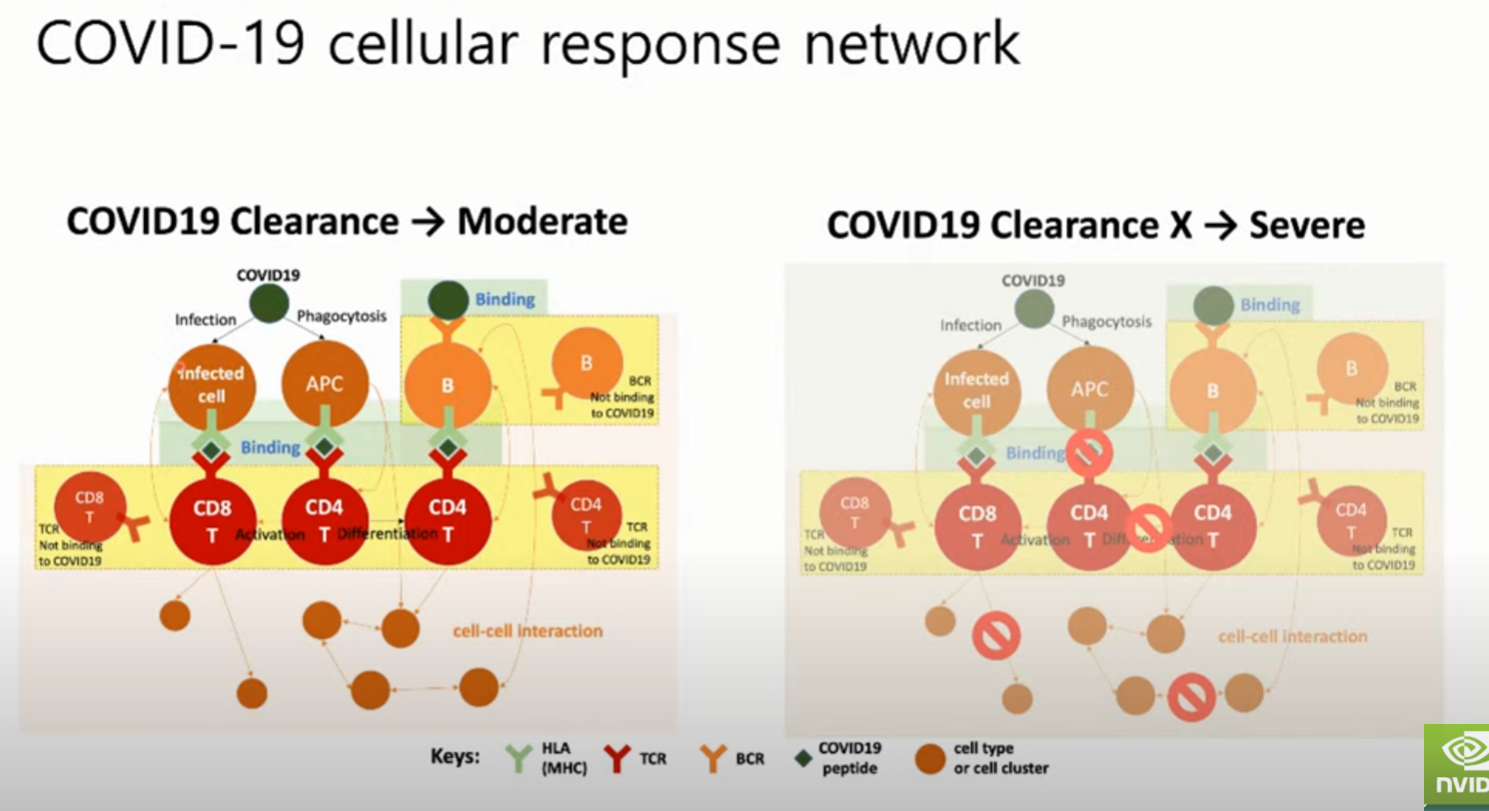
(전제) 바인딩.
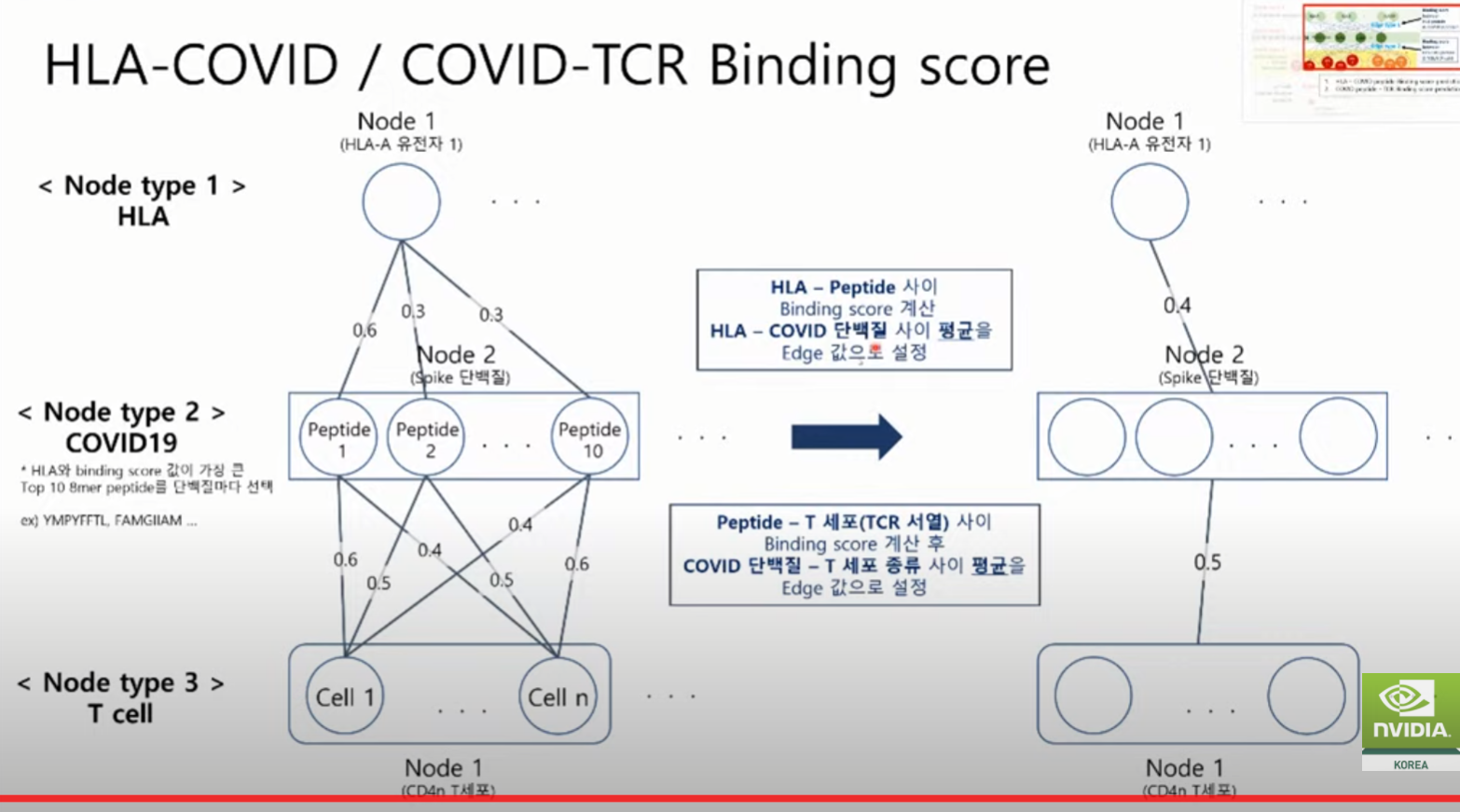
노드타입 : 유전자 정보, 코로나 서열정보, Tcell, Bcell 정보
바인딩 정보 : 노드간의 상호관계
경증과 중증간에 어떤 연결관계가 다른지 확인하고 싶은 것.
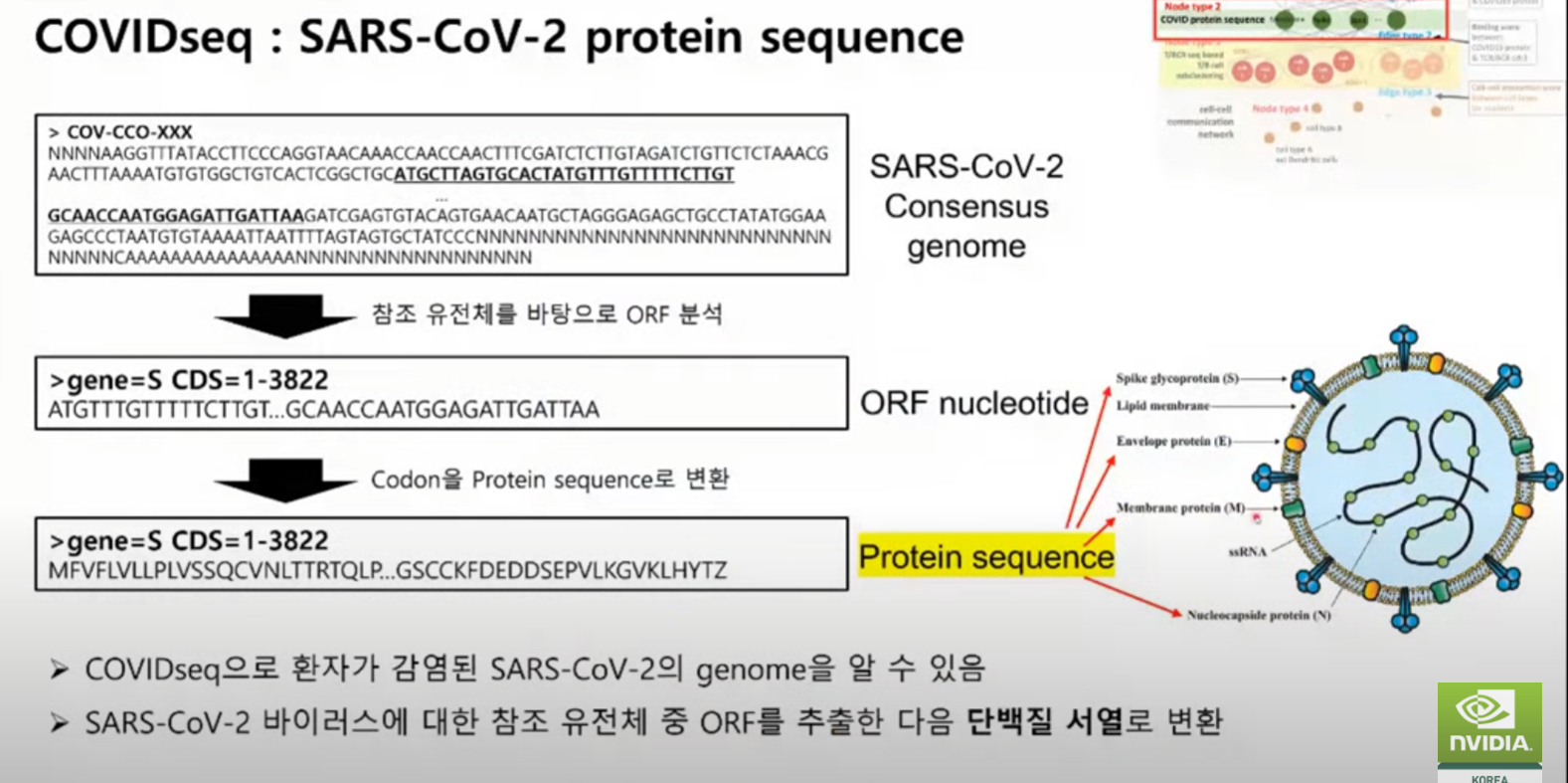
A,U,G,C 중요한 부분 뽑아내서(참조 유전체 바탕 ORF 분석) -> Codon 을 Protein sequence 로 바꿈.
환자마다 각각의 matrix 가 생김.
펩티드 서열 넣으면, HLA-A 값 구하는 Binding 값 내주는 Tool 이 있음.
각각의 바인딩 스코어를 구해서 평균
각각의 서열을 넣고, 바인딩을 구함. 그리고 스코어값이 어떻게 다른지 확인.
바인딩 <- 잘 안되면 항원 제시가 잘 안됨. 혹은 T cell 활성화가 잘 안됨. 높아야 정상 반응
추가적으로..
어떤 Ligand, 어떤 Receptor 가 반응하는지 이미 잘 알려져있음. interaction score 구해서 함.
기존에 있는 것을 이용해 Cell annotation , 이후 Cell-Cell interaction 확인
Cell 안에 어떤 세포,..
-- 결과 --
(아마)교신저자 : kksoo716@gmail.com/ 서울대학교병원 김광수 교수님
마무리 말씀 : Biology -> ML로 계산할 수 있는 문제로 바꾸기까지 Domain knowledge 가 굉장히 많이 필요하다.
[사전질문 및 답변]
질문 1) 멀티 오믹스 데이터를 최적으로 통합하고 분석하기 위해 중점적으로 검토하고 점검해야할 것들?
답변 1) 네트워크 형태로 바꾸는 것이 좋을 것이다. 일단 각각의 데이터셋의 퀄리티를 올리는 것이 중요할 것이다. 모든 feature 를 다 쓰기 보다, 의미있는 feature(약물에 반응하는) 만을 사용하는것이 통합에 도움이 될 것이다.
답변을 얻지 못한 누군가의 질문 >> 코로나 백신도 인체의 면역작용에 기반하는 것으로 보입니다. 어떤 질병은 평생 한번의 백신으로 면역이 유지되는데 반해 코로나는 3~6개월 사이에 부스터샷으로 백신을 추가 접종하였습니다. 질병마다 면역력이 다른 이유를 알고 계시면 설명해주시면 좋겠습니다. 이런 면역력을 길게 더 늘릴 수 있는 방안에 대한 연구도 진행이 되고 있을까요?
폐회사
About 강연 다시보기 :
사전등록하신 분에 한하여 다시보기 링크를 제공할 예정
후기
- NVIDIA 에서 주최하는 만큼 NVIDIA의 MONAI, FLARE 와 같은 TOOL, NVIDIA에서 개발 및 연구한 내용이 주를 이뤘다. 나는 각 주제에서 좀더 General 한 얘기를 들을 수 있을 줄 알았는데, 살짝은 아쉬웠다. 반면 서울대병원 교수진분들은 좀 더 General & Overall 한 내용을 다뤄주셨다.
- 각 세션마다 NVIDIA 연설자가 강연한 이후에 서울대병원 교수진분들이 강연을 해주셨는데, 이 순서를 반대로 바꾸는것이 더 좋을 것 같다는 생각이 든다. 먼저 전반적인 해당 주제에 대한 내용을 다룬 뒤에, NVIDIA의 이를 위한 Tool, 노력으로서의 개발 내용 들을 듣는게 더 유익할 것이라는 생각이 들었다.
- NVIDIA의 MONAI, FLARE 등의 TOOL 및, 데이터 분석을 위한 GPU 등에 관심이 있고, 앞으로 사용해볼 생각이 있는 사람이라면 확실히 도움이 될 것이다. 그게 아니라면 크게 추천하지는 않는다. 개인적으로는 데이터분석을 공부할 사람이라면 앞으로 MONAI, FLARE 등의 툴을 어느정도 이해하고, 경험해봐야 할 것 같아서 듣길 잘했다고 생각한다.
- QnA 시간이 따로 확정적으로 존재하는게 아니어서 아쉽다. 시간이 남으면 그 시간 안에 하고, 시간이 없으면 아예 안하기도 한다. 혹은 강연 중에 실시간으로 질문이 올라오고 답변이 올라오기도 한다. 그렇다보니 본 강연에 집중이 흐트러질때가 종종 있었다.
- 각 세션을 설명해둔 주제와 실제 강연의 내용이 매칭이 안되는 부분이 있는 것 같다. 그리고 녹음된 음성이 명확하게 들리지 않아서 듣기 불편할때가 있었다.
- 가장 아쉬웠던 부분은 자막.. 실시간 강연도 아니고, 시차때문에 녹화된 영상을 틀어주는데 영어/한국어 자막이 없다. 실시간 강연이라면 어쩔 수 없지만 녹화된 영상같은경우는 충분히 달 수 있던 부분이었다고 생각한다.