성한데가 없어서 빠른 시일내로 고장나겠거니 생각하고 있어서그런지, 크게 놀랍지도 슬프지도 않았다.
그냥 어 고장났네. 새거사야지. 근데 조금 아쉽다 이정도...
2018년 초에 구매해서, 2022년 초까지 썼으니 약 4년정도 쓴 셈이다.
SSD, ram 도 추가하고.. 키보드 연결도 바꾸고... 액정도 한번 간 노트북이라.. 1년은 더 쓰고 싶었는데.... ㅠㅠ
근데 하필이면 노트북 고장난 시기가 설날 연휴 직전이었다.
연휴때문에 노트북 배송도 더 오래걸릴테고, 친가 외가 돌아다녀야해서 랩실을 못가는데 노트북도 없으니 프로그램도 못돌리고,.. ㅠㅠ 할 수 있는게 없었다.
노트북 배송 지연되었다는데 언제오려나... 당분간은 새벽 코딩은 못할 것 같다. 난 새벽에 뭔갈 하는게 제일 잘되는데.
내가 고민한 노트북 종류는 3가지였는데,,
▪ 1. ASUS 비보북 프로 14X OLED (N7400PC-KM005)
무려 그래픽카드 RTX 3050에 윈도우 포함하여 160만원의 가성비 가격대.
디스플레이도 매우 좋고 그 외 스펙도 모두 무난+좋음.(램16, SSD 512)
CPU는 라이젠인데 인텔이 달려있는 것도 있다고 들었던 것 같음.
디자인이 별로라는 평이 있고, 외국브랜드인만큼 AS 가 쉽지 않다. (외국브랜드중에선 AS 측면에도 Asus가 가장 낫다는 평이 있음)
내가 고민됐던부분은 '이정도 성능 노트북이 나한테 필요한가??'였다.
대학원에 진학할 예정이니 내 데스크톱을 받을거고, 프로그램도 아마 서버로 돌릴텐데 말이다.
나에게는 데스크톱 보조용, 사무용 노트북이 필요했다.
더구나 나는 게임도 안한다.. 디자인 부분은 맘에들었지만 AS가 걸렸다. (AS하러 잘 가지도 않으면서!)
▪ 2. 맥북air M1
매우매우매우 좋은 평가를 받고있는 애플의 M1! 소문은 익히 들어 좋다는걸 알고있었다.
이걸 쓰는 주위 사람들도 다들 만족하며 쓰고있다고 하고.. 가격대도 괜찮은편.그런데 15인치가 없고 13인치밖에 안나온다는게 흠... 15인치에 익숙해진 나에겐 너무 답답할것같았다.그리고 나는 어렸을때 아이폰, 아이패드 이런걸 많이 써서그런가 이제 애플 디자인에 질렸다. 하나도 안예쁘다.감성적인것보다 갤럭시나 Asus 같은 투박한 디자인이 더 좋다.
▪ 3. 2022 갤럭시북
무난. 딱 사무용 + 데스크톱 보조용으로 쓰기 좋음.
AS하기 조음. 디자인도 무난. 그러나 키보드자판 등 디스플레이에서 원가절감을 했다는 말이 있음.
나는... 고민하기 귀찮고 급하게 필요해서 노트북 고장난 날에 바로 2022 갤럭시북을 샀다.
갤럭시 캠퍼스 스토어에서 안샀으면 170~180마넌 정도 하던데
갤캠스에서 사서 137마넌에 샀다. 이 가격 아니면 다른거샀을듯.
---> (3.17 내용추가) 갤캠스에서 샀더니 배송이 진ㄴㄴㄴㄴㄴㄴㄴㄴ짜 오래걸려서 (거의 3주는 걸림) 그냥 취소하고 기존에 쓰던 노트북 AS 했다. 메인보드 고장일줄알았는데 액정 고장이더라. 다행이었다. 그래도 20만원 날렸다. ㅠ
설치에 대한 얘기를 하기 전에, 미리 알아두면 좋을 AlphaFold2 에 대한 내용을 소개하려 한다.
ppt 열심히 만들었다.
결론적으로, ranked_0.pdb 를 확인하면 된다.
이제 설치에 대한 얘기를 해보자.
내 서버 환경은 다음과 같다.
Ubuntu 18.04.01
Conda 3.9.2
Nvidia-driver-465
CUDA 11.3
cuDNN 8.2.1
Pytorch 1.9.0
내가 겪은 오류는..
unable to create StreamExecutor for CUDA:0: failed initializing StreamExecutor for CUDA device ordinal 0: INTERNAL: faild call to ceDevicePrimaryCtxRetainL CUDA_ERROR_OUT_OF_MEMORY: out of memory; total memory reported: 2544170048
Attemping to fetch value instead of handling error INVALID_ARGUMENT: device CUDA:0 not supported by XLA service
Fatal Python error: Aborted
이건 내가 기록해둔것만 나열한거고, 이것 말고도 오류가 정말 많았는데.. (+ jaxlib 버전 문제 등)
구글 서칭을 통해 누군가 해결했다는 방법을 내 dockerfile에 적용해도, 계속 오류가 수정되질 않았었다.
dockerfile을 다른 버전으로 바꿔도 보고 수정도 해보고 했는데 계속 오류오류오류...ㅜㅜ
내가 CUDA 11.3 version을 쓰는 문제도 있던것같고, Alphafold2 소스코드 자체에서 발생한 문제도 있던 것 같다.
그러다 1주? 쯤 전에 AlphaFold가 새롭게 release 되어서(v2.1.2), 다시 git clone 하여 약간의 오류를 수정해주니 정상 작동했다! 아마 앞으로 알파폴드를 실행해보려는 분들은 오류 걱정 없이 편하게 실행할 수 있을거라 생각된다. 난 2주를 고생했다! 니가이기나 내가이기나 해보자는 집념으로 2주동안 계속 오류 수정했다..
참고) 기본적으로 docker에 대한 지식, 리눅스 명령어에 대한 지식이 있는 사람만 시도하라.
약간의 팁을 주자면..
1. 만약 build시 오류가 났거나, dockerfile을 바꿔서 build 를 다시 해야할때 등등의 상황에서는, 미리 세팅된 image 및 container 를 지워주고 다시 build 하도록 하자.
docker image ls
docker rmi -f <image name>
docker image prune
docker container prune
2. 데이터셋 다운로드 받는데는 약 2~3일정도 걸린다. 걱정하지말고 냅두면 잘 다운로드 될 것이다.
경희대학교(서울캠퍼스, 국제캠퍼스) 에서 주관한 캡스톤 디자인 경진대회에서 최우수상을 수상하였습니다.!!
캡스톤디자인 수업은 모든 학생이 3, 4학년때 참여하는 수업으로, 그동안 배운 내용을 토대로 창의-종합적인 프로젝트를 설계 및 수행하여 유의미한 결과를 도출해 발표하는 프로젝트입니다. 이 프로젝트를 더 발전시켜 후에 졸업논문으로 쓰기도 하구요.
이번 대회는 이번 학기(2021-2)에 캡스톤디자인 수업을 들은 모든 학과, 모든 분야 학생들의 종합설계 프로젝트를 평가 및 시상하는 대회였습니다. 그래서그런지 입법제안, 식품제조와 같은 주제부터 스마트팩토리 기계, 안내형로봇 등의 주제까지 정말 가지각색의 프로젝트가 본선에 올라왔더라구요.
저는 데이터분석캡스톤디자인 수업을 들었고, 팀 프로젝트로서 뇌파를 이용해 사용자의 감정을 잘 드러내주는 음악 작곡 알고리즘 구현 및 UI개발을 주제로 하였었습니다. (저번 포스팅에도 간략히 언급했었죠.)
심사는 총 예선, 본선으로 이루어졌으며 예선으로는 서류심사, 본선으로는 발표를 통해 평가했고,
다양한 접근을 통해 제한된 데이터에서 더 효율적으로 학습가능하며 데이터의 복잡성과 다양성에 대처할 수 있는 네트워크를 형성했습니다.
Framework
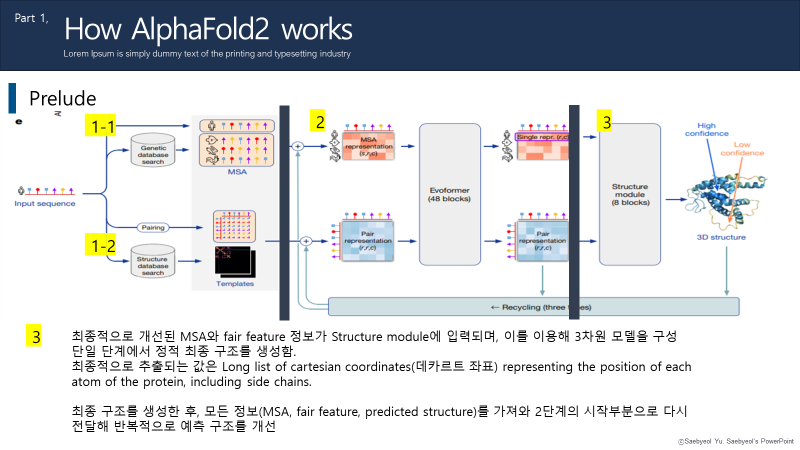
.fasta 입력파일이 들어오면, 모델은 각각 두 가지 경로로 나눠 서칭을 진행합니다.
1-1 경로로는 데이터베이스에서 유사한 '단백질 서열'을 조회하고, 식별합니다. (이 정보를 MSA라고 부르겠습니다.)
1-2 경로로는 데이터베이스에서 유사한 '단백질 구조(템플릿)'을 조회하고 식별합니다.
다음으로, 각 정보에서 MSA와 템플릿을 추출해 변환기를 통해 전달합니다. 이 Transformer를 통해 MSA와 템플릿은 서로 정보를 주고받으며 표현을 계선합니다. 이는 지정된 주기수까지 반복되는 48개의 블록으로 구성되어있습니다.
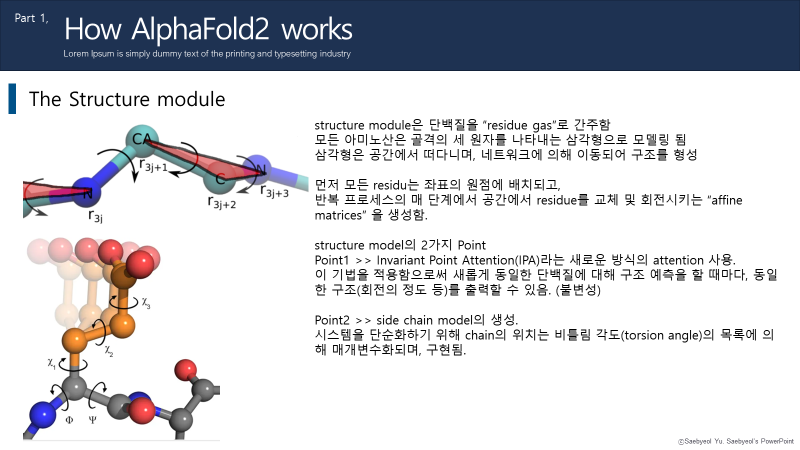
이후 Evoformer를 통해 개선된 정보가 출력되면, Structure module에 넣어 3차원 구조를 예측하고, 모델을 생성합니다.
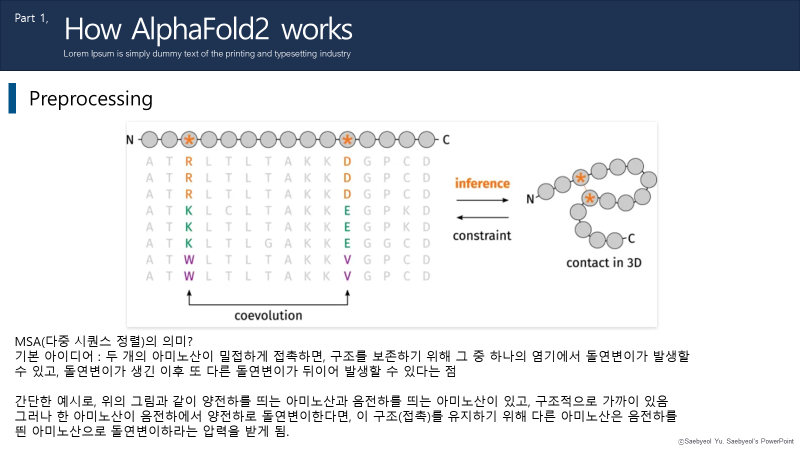
논문에서 중요하게 봐야할 부분중에 하나가 이 Transformer 부분인데요. 연구원이 제안한 Evoformer는 MSA와 템플릿에서 모든 정보를 짜내서,현재의 구조적 가설을 활용해 다중 서열 정렬의 평가를 개선하고(새로운 인사이트 창출)이후 새로운 구조적 가설 등으로 이루어지게합니다.
예를 들어서, 만약 ABCD 라는 서열을 갖고, 일자 구조인 단백질이 있다고 해봅시다. 아미노산은 +, - 성질에 따라 접히기도 하고 펼쳐지기도 하는데요. 예를들어 A가 +, B와 C가 각각 +, -, D가 + 를 갖고있다면 B와 C는 서로 끌어당겨 접히게 됩니다. 이렇게 되면 서열만으로 예상하였을때는 서로 + 라 접힐 일이 없는 A와 D가, 접혀야하는 상황이 오게됩니다. 이렇게되면 둘 중 하나가 -로 바뀌며 돌연변이가 될 수 있습니다. 알파폴드는 이렇게 아미노산의 서열과 구조간의 정보를 서로 교환하며, 매 iteration마다 발전적인 예측을 하게 됩니다. (아미노산은 돌연변이가 종종 발생하며, 이 돌연변이를 예측하는게 단백질 접힘예측의 중요한 부분이라고 볼 수 있습니다. 해당 내용은 원리를 간략하게만 작성한것입니다.)
본 글에서 제가 설명한 부분 외에도 정확도를 높이기 위한 다양한 접근이 시도되었고, 이를 간략히 정리하면 위와 같습니다.
알파폴드는 오픈소스로, 누구나 다운로드받아 실행해볼 수 있습니다.
저도 알파폴드를 설치해 실행해보려하는데.. 왜인지 설치 및 실행 과정에 오류를 많이 겪고 있습니다. -_-
도커가 환경 다 구축해주는데 왜 환경때문에 문제가 발생하는건지?! 는 도커파일에 문제가 있었고...
아무튼 정말 다양하게 오류가 발생하고 있습니다. 이거때문에 글 쓸 의욕이안나는듯
계속 수정하는중이라 곧 성공적으로 돌려볼 수 있을것같은데, 그렇게되면 또 간략하게 글 쓰겠습니다.
이 논문에서는 Covid-19 감염 조기 진단을 위한 의료 이미지의 Transfer learning 프레임워크를 제시합니다.
Transfer learning?
Transfer learning은 자신이 풀고자 하는 task의 데이터가 충분히 많지 않을때 사용할 수 있는 방법으로, 현재의 task와 비슷하면서 다른, 방대한 데이터로 미리 학습되어있는 모델을 이용하는 방법입니다. 간단히 말해 사전 학습 모델의 일부를 이용하면서, 끝부분만 우리가 해결하고자 하는 task의 문제로 바꾸어 원하는 결과를 얻는 방법이라 할 수 있습니다.
사전 학습 모델을 이용함으로써 새로운 모델을 만들때 학습 속도도 더 빨라지게 되고, 가지고있는 데이터 양에 비해 예측의 정확도도 향상될것을 기대할 수 있습니다. 특히 의료 데이터는 다른 도메인의 데이터보다 얻기 힘들기 때문에(비용 등의 문제) 전이학습은 유용하고 중요한 학습 방법이라 할 수 있습니다.
논문 요약
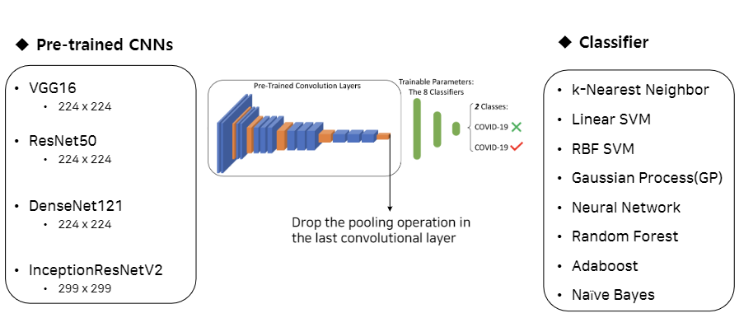
X-ray 및 CT 이미지 dataset에 대하여, 사전학습 모델로 널리 사용되는 VGG16, ResNet50, DenseNet121, InceptionResNetV2 및 CNN 을 적용해 이미지에서 feature를 추출하고, 이를 기계 학습 및 통계 모델링 기술을 통해 Classification하여 Covid-19의 음성/양성을 판별하는 연구입니다. 또한 모델을 통한 분류 결과의 불확실성을 함께 계산하여 보고합니다. 결론적으로는 두 데이터셋 모두 linearSVM 모델과 neural network model에서 accuracy, sensitivity, specificity, ROC curve, AUC 값이 높은 성능을 보였다고 하며, X-ray에 비해 CT 이미지의 예측 불확실성 추정치가 높았다고 합니다.
논문에서 사용된 사전학습모델 (VGG16, ResNet50, DenseNet121, InceptionResNetV2) 의 데이터는 1.4 백만개의 이미지, 1000개의 label 로 구성된 방대한 데이터셋인 ImageNet 입니다.
연구진은 ImageNet data를 학습한 모델의 Image detection task와 Covid-19 classification 사이에 Fundamental similarities 가 있다고 생각하여 연구를 진행했습니다.
Dataset
연구에서 이용한 데이터셋은 흉부 X-ray 이미지(2D)와, CT 이미지(2D)입니다.
사전 학습 모델이 2D data를 input으로 받는 모델이다보니, 3D 이미지인 여러장의 CT data에서, 한 장의 CTdata만 이용해 2D로 학습시킨것으로 보입니다.
Chest X-Ray Data set ✓코로나 양성 이미지 25장 ✓ 코로나 음성 이미지 75장 ✓non-Covid : consist of other unhealthy conditions → non-Coviddoesnotnecessarily infer a healthy lower respiratory system
CT Data set ✓ 코로나 양성 이미지 349장 ✓ 코로나 음성 이미지 397장 ✓carry more information compared to chest X-rays
위에도 적어놓았다시피, 흉부 X-ray dataset의 '음성' label 이미지는 단순히 건강한 사람(무질병자)의 이미지가 아니라, Covid가 아닌 다른 질병에 걸린 환자의 dataset도 포함합니다. 즉, 질병자와 무질병자를 나누는 모델이 아니라 코로나 환자와 비코로나 환자를 나누는 모델을 만들고자 하였다는 것입니다.
Framework
연구에서는 CNN을 이용한 사전학습모델로 상기 4가지 모델을 사용했고, Classifier로는 다음의 8가지 모델을 사용했습니다. 최종 모델의 앞부분은 사전학습모델의 Convolution layer를 그대로 가져와서 가중치를 사용하였고, 뒷부분은 Covid classification을 위한 classifier를 사용하였습니다.
Visualization
Performance Metrics (Percentage)
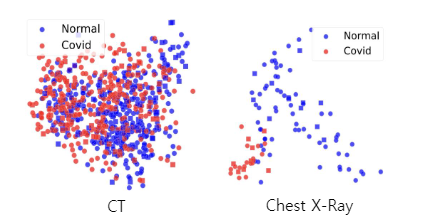
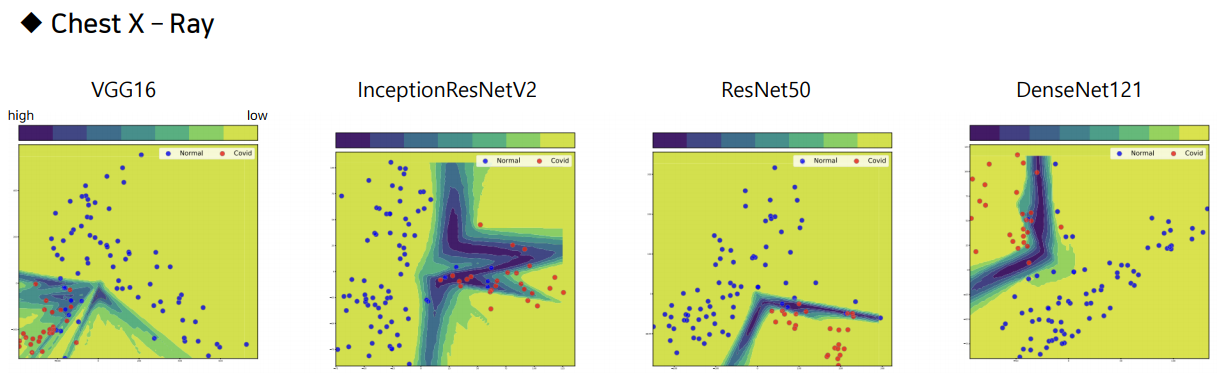
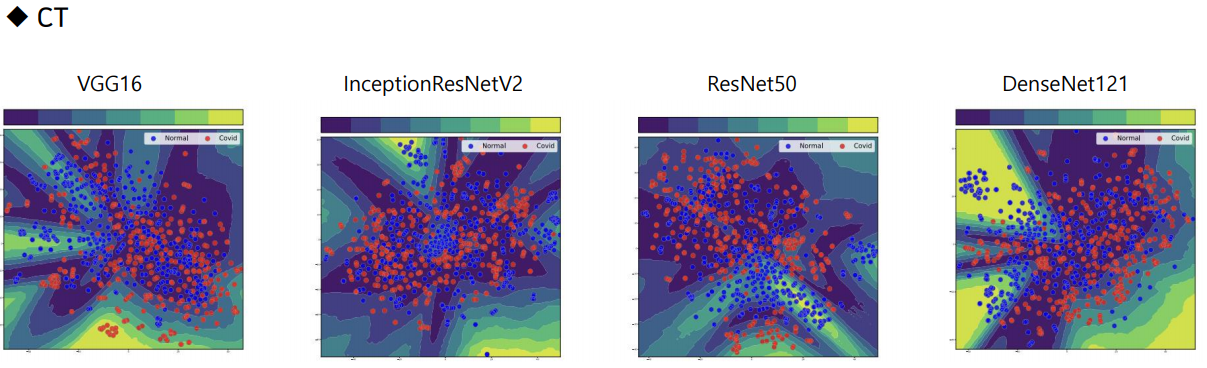
VGGnet 을 이용해 각 data에서 25088개의 feature를 추출하고, 이를 PCA를 통해 2개의 feature로 줄인 그림입니다. (설명력은 논문에 기재되지 않은것으로 보임.) 각 포인트는 환자 한 명의 데이터입니다. 즉, 환자 한 명의 데이터를 2차원 평면에 시각화한 그림입니다. 흉부 X-ray data는 음성과 양성 데이터의 구분이 꽤 뚜렷한 반면에 CT data는 그러한 경계가 없다는 것을 확인할 수 있습니다.
Visualize the effectiveness of extracted features
gradient-weighted class activation mapping 그림입니다. Backpropagating 한 결과를 HeatMap 으로 그려 X-ray 사진에 HeatMap을 덧씌운 그림입니다. 모델이 데이터를 분류할때 어느 부분이 중요하게 영향을 끼쳤는지 확인이 가능합니다.
Evaluation
연구진은 100 회에 걸쳐 Train 및 Evaluation 을 진행하였고, Accuracy, Sensitivity, Specificity, AUC value 값을 평가 지표로서 활용하였습니다. 아래의 표는 모든 예측(100회) 의 평가지표의 평균을 낸 값입니다.
pre-trained 모델로 ResNet50 + 분류기 모델로 Linear SVM을 사용한 조합이 각 데이터셋에서 높은 성과를 보인것을 확인할 수 있습니다.
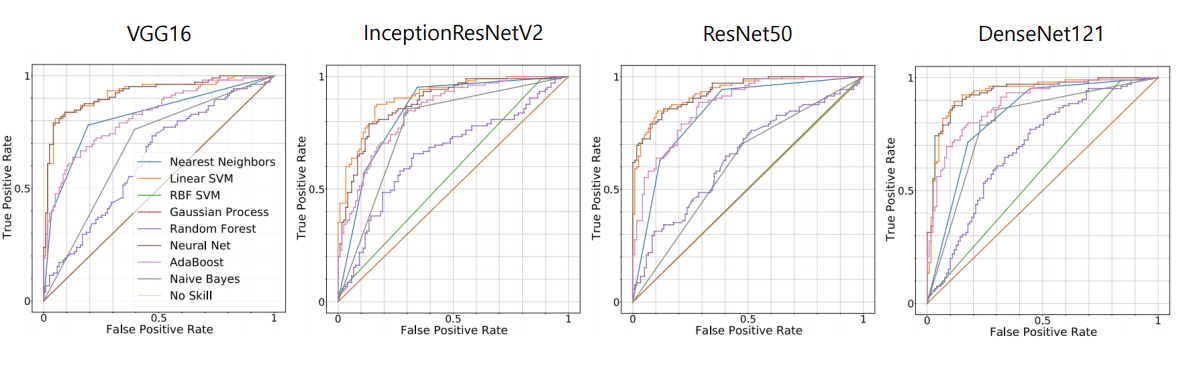
ROC-AUC score
각 모델별 ROC curve 입니다. linear SVM 과 neural Net 이 가장 높은 AUC 값을 가지는것을 확인할 수 있습니다.
또한 classifier의 성능은 pre-trained CNN 모델에 따라 다양하게 나타나고 있습니다.
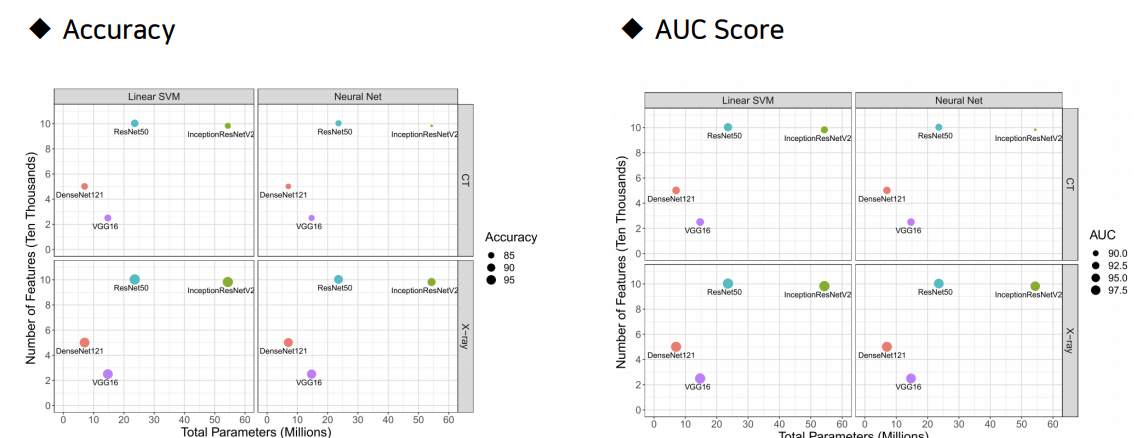
연구진은 추가적으로, 각 모델별로 추출되는 feature 및 파라미터의 갯수 또한 비교하였는데요. 그래프의 원은 pre-trained CNN 모델이며, 원의 크기는 Accuracy를 의미합니다. VGG16 모델은 적은 파라미터 및 feature 갯수에 비해 높은 정확도, AUC 값을 가지고 있고(Most informative& Discriminative), InceptionResNetV2는 높은 파라미터 및 feature 갯수에 비해 낮은 정확도, AUC 값을 가지고 있습니다. (Least informative & Discriminative features)
이러한 자료를 통해, 큰 네트워크를 가진 모델이더라도 반드시 more informative and discriminative features 를 추출하는것은 아님을 알 수 있습니다.
predictive Uncertainty Estimation
Uncertainty 는 2가지가 있습니다.
Aleatoric Uncertainty는, 어쩔 수 없이 발생하는 오류로 학습을 통해 줄일 수 없고,
Epistemic Uncertainty는 모델이 모르기때문에 발생하는 오류로 학습을 통해 줄일 수 있습니다.
연구진은 추가적으로, 모델의 Epistemic Uncertainty를 줄이기 위해 이를 추정해 나타내고자 하였습니다.
그리고 이를 위해 Ensemble model을 만들었습니다.
Ensemble 모델은 1개의 Hidden layer 를 가진 20개의 독립적인 neural network로 구성되어있고, hidden layer의 neuron 는 랜덤하게 50~400 개 중 선택되었습니다.
불확실성은 다음과 같이 계산되었습니다. (p 는 softmax 함수와 비슷해 보이네요..)
이를 다시 PCA를 통해 dimension을 줄여 2차원으로 만들었고, 시각화하여 나타내었습니다.
밝은색(녹색)일수록 높은 확실성, 어두운색(남색)일수록 높은 불확실성을 나타내고,
불확실성이 높다는 것은 앙상블 모델 내부의 classifier들의 분류가 서로 완전히 일치하지 않다는 것을 의미합니다.
X-ray의 Epistemic Uncertainty 는 상대적으로 낮고, CT 이미지는 꽤 높은것을 확인할 수 있습니다.
앞서 말씀드렸듯 CT 이미지는 원래 흉부를 관통하여 찍는 3D 이미지인데요, 이를 모두 사용하지않고 임의로 한 장을 선택해 분류를 진행하였으니 x-ray에 비해 불확실성이 높게 나타난 것이 아닌가 싶습니다. (가령 Covid를 분류하기 위한 설명력 높은 feature를 추출할 수 있는 위치에서 찍은 이미지가 아니었다던가..)
Further Exploration
마지막으로, 연구진은 이 모델을 개선하기 위해 fine-tuning, hybrid models(feature 간의 통합 등), ensembles, more comprehensive Uncertainty measure 도출 등 다양한 방법을 제시하였습니다.
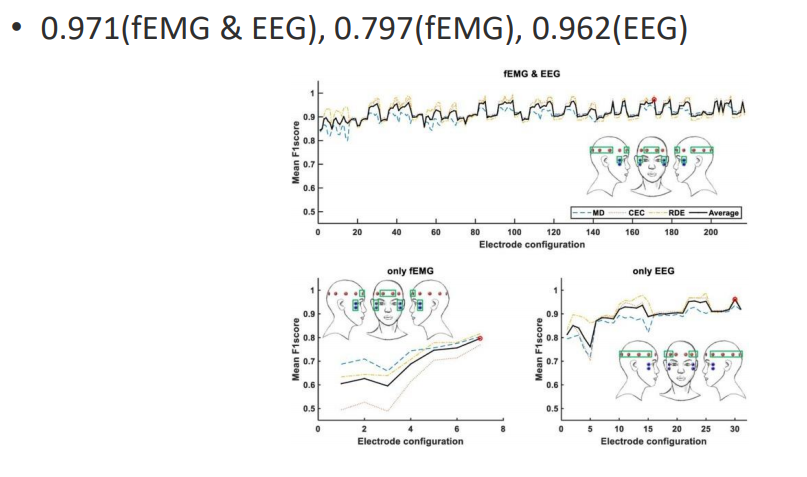
이 연구는 뇌전도(EEG)와안면전자기록(fEMG)을이용한,얼굴미세표현에서의 감정 분류를 목표로 하는 연구이다. 이때, 얼굴 미세표현이란 사람이 자신의 감정을 숨기고 억제하려할때 나타나는 표정이다. 즉, 사람이 감추려하는 감정을 얼굴에 드러나는 미세표현으로부터 알아내고자 하는 연구라고 할 수 있다.
사용한 데이터셋
16명의 피험자에 대해 EEG(10개의 채널)와 fEMG(4개의 전극) dataset을 사용했다. EEG는 뇌의 전기적 활동을 나타내는 신호이고, fEMG는 얼굴 근육 섬유의 수축과 이완을 감지할 수 있는 신호이다. Target값은 피험자의 감정으로, 정답 label은 얼굴의 표정 영상 데이터를 이용한 감정분류값이다. 또한, 정답 label의 보조적 수단으로서 피험자에게 Arousal과 Valence 수치를 설문조사하여, 얼굴 표정영상데이터의 감정분류값과 Arousal/Valence값을 비교해 검증 및 조정하였다. (특정 범위 이하이면 제거하는 방식으로)
연구에서 정답값으로 사용된 '얼굴 표정영상데이터의 감정분류값'은 다음과 같이 결정된다. (기존에 있던 프로그램 이용)
먼저 사용자의 얼굴에 랜드마크를 찍으면, 랜드마크 사이의 거리, 모양 등에 따라 사용자의 감정이 다각도로 분류된다.
랜드마크다각도로 분석된 피험자의 감정
한 예로 분석된 피험자의 감정상태를 보면, 피험자 1은 Happy한 감정임을 알 수 있다.
Framework
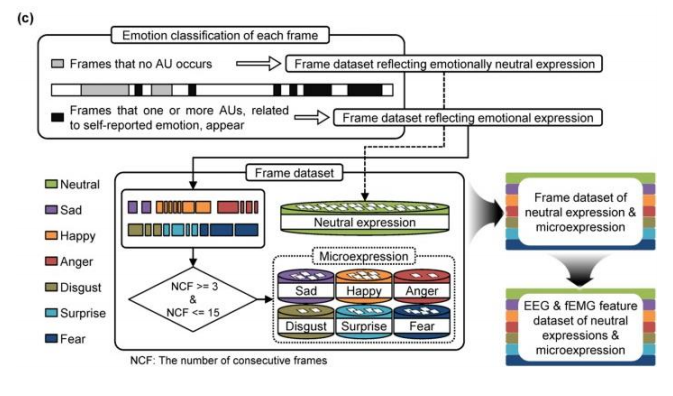
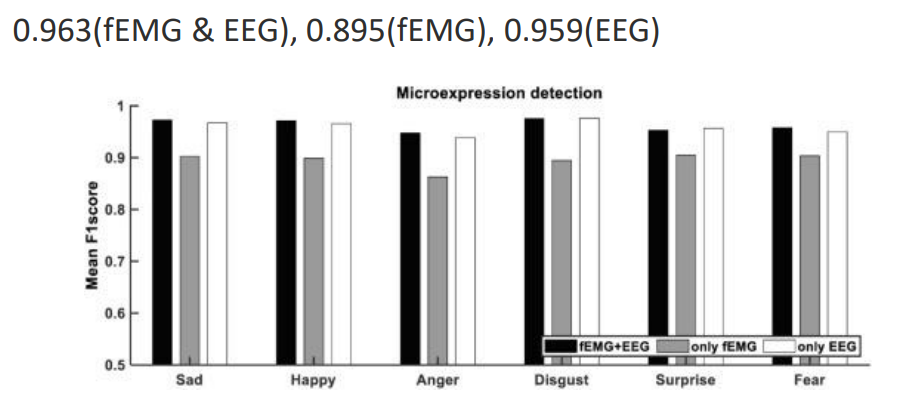
연구는 16명의피험자에 대해 진행되었고, 특정 감정을 느끼게 하는 영상을 보여주며 EEG 및 fEMG signal 을 수집하였다. 최종적으로는 피험자의 감정을 Sad, Happy, Anger, Disgust, Surprise, Fear 총 6가지로 분류한다.
그림과 같이 EEG 및 fEMG signal 에서 Filtering -> Segmentation -> Feature extraction 의 순서로 전처리 및 feature를 추출한다.
Band stop 필터는 신호의 주파수를 통과시키지만, 특정 범위의 주파수를 매우 낮은 수준으로 낮추는 필터이고,
Band pass 필터는 특정 주파수만을 통과시키는 필터이다.
연구에선 58-62 Hz의 주파수를 낮추고, EEG에서 1-50Hz만 통과, fEMG에서 20-450 Hz만 통과 시켰다. 이는 감정분석에 주로 많이 사용되는 주파수 대역대이다.
이후 window마다 높은 비율로 overlap하여 signal을 segmentation한다. (중복되게 자르는 비율이 높다)
마지막으로 EEG에서 Average spectral power, fEMG에서 Root mean square을 추출한다. 이 두 개의 feature를 통해 감정 분류를 하는 것이다.
결국총feature는 EEG에서 10 x EEGfeature 개 (10개채널xEEG의ASP), fEMG에서 4xfEMGfeature(4개채널xfEMG )개가 된다.
이 과정을 더 자세히 나타내면 다음과 같다.
연구에서는 전체 signal을 이용해 감정분석을 하지 않고,
Frame별로 얼굴 표정(정답값)을 분류해, 감정이 감지되는 Frame의 signal만을 이용해 해당 프레임의 감정을 분류한다.
모델은 SVM 을 사용했다.
연구 결과
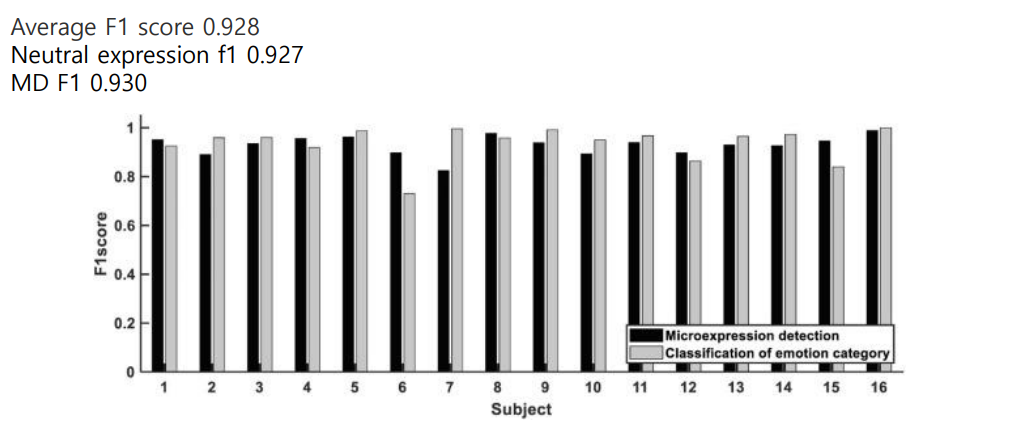
결과는 F1 score를 통해 검증하였다.
* F1 score는 다음과 같이 Precision 과 recall의 조화평균으로 계산된다.
적은 수의 feature를 사용하였음에도 average f1 score = 0.928 로 성능이 매우 좋은것을 확인할 수 있다.
개인적인 의견
전체 signal을 이용해 감정을 분류하지않고, 특정 감정이 드러나는 Frame 에 대한 signal 만 이용해 분석한것이 정확도를 높인 설계라고 생각한다.
개인적으로는 프로그램이 분류한 감정 상태를 정답값으로 두어도 괜찮은가? 하는 의문이 들었다. 이것은 사실 온전한 정답이라기 보다 예측값에 가깝기 때문이다. 연구진도이 부분을 우려하여, 이를 보완하기 위한 방법으로 설문조사를 통해 수집한 Arousal 과 Valence 수치를 이용한것으로 생각된다.
논문에서는 functional connectivity 가 사용되었으나, functional connectivity 뿐 아니라 관련한 다양한 Connectivity 기법이 있다.
•Structural Connectivity •Biophysical connections between neurons or neural elements •Functional Connectivity <-논문에서 사용한 것 •Statistical relations between anatomically unconnected cerebral regions •Effective Connectivity •Directional causal effects from one neural element to another
논문 요약
EEG의 각 채널간의 Functional connectivity metrics를 계산하여 feature를 도출하고,
Eyetracking data에 대한 feature를 도출해 두 feature를 fusion 하여,
이에 대해 SVM 모델을 통해 다중 분류(5가지)하여 감정을 분석하고자 하는 연구이다.
사용한 데이터셋
피험자에게 특정 감정을 느끼게 하는 동영상을 보여주면서,
64개 채널에서EEG 신호를 수집하고, 동시에 Eyetracking data를 수집한 것이다. (SEED, DEAP 등)
Framework
1. 먼저 EEG signal data를 주파수 대역대(알파, 델타, 베타, 세타, 감마)로 나누어 4초 간격으로 잘라서, 64x64 의 Dynamic Brain connectivity Metrics 를 형성한다. (connectivity Metrics 란 네트워크 Metrics로, 각 채널을 vertex로 두고 신호와 신호의 상관(연결)관계를 나타내는 Metrics이다.) 이렇게 하면 결과적으로 5 종류의 64x64 Metrics 여러 장을 얻게 된다.
아래의 그림을 참고하자.
2. 1번에서 구한 Metrics 에 대해 Critical subnetwork selection 의 과정을 거친다. 이 과정은 총 3가지를 거치게 되는데, Averaging, Thresholding, Merging 이다.
Averaging 에서는 각 emotion state 별, 그리고 주파수 별로 connectivity metrics의 평균을 낸다. 이렇게 하면 5가지 emotion 에 대해, 그리고 한 emotion당 5가지 주파수에 대해 Metrics 가 할당되게 된다.
이후 Thresholding 을 통해 신호 중에서도 강력하게 나타나는 신호만을 selection 하게되고,
Merging 과정을 통해 주파수대역대로 나눠진 분류를 기준으로, merging 하게 된다.
최종적으로는 각 주파수 대역대로 나뉘어진 64x64의 Metrics 총 5개가 추출되게 된다.
3. 이렇게 추출된 metrics를 Critical connectivity matrices 라고 부른다.
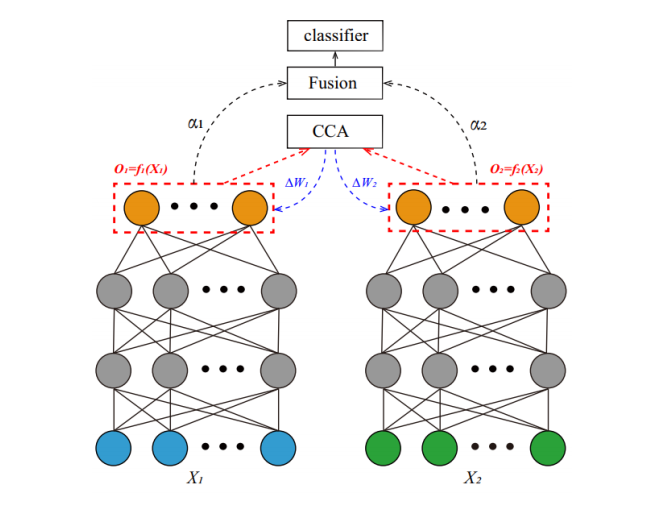
논문에서는 해당 matrics에서 feature를 추출한다. 아래의 그림과 같이 EEG(matrics)에서 3종류, Eyetracking data에서 5종류를 추출한다. 연구진은 이렇게 추출한 EEG, Eyetracking feature를 fusion 하여 최종 feature를 재구성하는데, 이 과정에서 사용한 model을 DCCA라고 부른다.
모든 EEG feature와, 모든 Eyetracking feature를 fully-connected 모델에 input으로 넣고, non-linear 형태로 각각 연산한다. (relu 같은 non-linear activation function 을 썼다는 의미라고 생각된다.) 최종적으로 나온 output에 대해, EEG와 Eyetracking data간의 피어슨 상관관계를 계산하고, CCA 를 통해 둘의 상관관계를 최대한 높일 수 있는 방향으로 파라미터를 업데이트 한다. 그리고 최종 결과를 Classifier(SVM)에 넣어 Emotion을 5가지로 classification 한다.
이때 여러가지 feature, 여러 데이터의 상관관계를 한꺼번에 어떻게 구하는것인지 의문이 들 수 있는데
multi-배리얼-statistic- ?? 이라고 하는 기법이 있다고 한다. CCA 뿐 아니라 PLA 등의 기법 또한 있다고 한다.
또, 상관관계를 최대화 하는 방향으로의 파라미터 업데이트를 위한 cost function은 correlation 의 negative 값을 이용해 SVD 계산을 하여 구했다고 한다.
최종 분류 결과
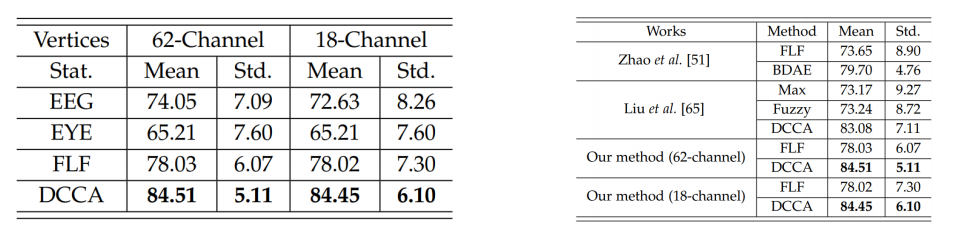
연구진은 다양한 접근으로 정확도를 비교하였다.
EEG 만 이용해 감정분석, Eyetracking data만 이용해 감정분석, 둘 모두를 합쳐 감정분석(DCCA 모델 제외), 연구에서 제안한 DCCA 모델을 이용해 감정 분석.
이 네 가지의 정확도를 비교한 결과는 다음과 같다.
64채널을 모두 이용하고, 연구진인 제안한 DCCA 모델을 이용한 결과가 가장 높은 정확도를 보이는 것을 확인할 수 있다.
Transformer는Attention all you is need논문에서 제안된 모델 구조로, RNN의long-term-dependency의 한계점을 극복하기위해 제안된 아키텍처입니다. (은닉 상태를 통해 과거 정보를 저장할때,문장 길이ㅏ 길어지면 과거 정보가 마지막시점까지 전달되지 못하는 현상)트랜스포머가 출현함으로써 자연어 처리 분야는 획기적으로 발전되었으며, BERT, GPT3, T5등과 같은 혁명적인 아키텍처가 발전하는 기반이 되었습니다.
트랜스포머는RNN에서 사용한 순환 방식을 사용하지 않고,순수하게 어텐션만 사용한 모델이며,셀프 어텐션이라는 특수한 형태의 어텐션을 사용합니다.
트랜스포머는 다음과 같이 인코더와 디코더가 결합된 형태를 가진 모델입니다.먼저 인코더에 입력 문장(원문)을 입력하면 인코더는 입력문장의 표현을 학습시키고,그 결과를 디코더로 보냅니다.디코더는 인코더에서 학습한 표현결과를 입력받아 사용자가 원하는 문장을 생성합니다.
가령 영어를 프랑스어로 번역하는 과제가 있다고 하면,다음의 그림은 영어 문장을 입력받은 인코더를 나타낸 것입니다.인코더는 영어 문장을 표현하는 방법을 학습한 다음,그 결과를 디코더에 보냅니다.인코더에서 학습한 표현을 입력받은 디코더는,최종적으로 프렁스러오 번역한 문장을 생성합니다.
트랜스포머는N개의 인코더가 쌓인 형태입니다.인코더에 결괏값은 그 다음 인코더의 입력값으로 들어갑니다.가장 마지막에 있는 인코더의 결괏값이,입력값의 최종 표현 결과가 됩니다.입력값으로 입력 문장을 넣게되고,최종 인코더의 결과값으로 입력 문장에 따른 표현 결과를 얻게됩니다. N=6이라는 말은 인코더6개를 누적해 쌓아올린 형태를 표현한 것입니다.
인코더의 세부 구성요소를 표현하면 다음과 같습니다.모든 인코더 블록은 형태가 동일하며, 그림에 나와있는두 가지 요소로 구성됩니다.멀티헤드 어텐션 이해하기 전에,셀프 어텐션의 작동원래를 살펴보면,
이 문장에서it은dog나food를 의미할 수 있습니다.그러나 문장을 자세히 살펴보면it은dog를 의미한다는걸 알 수 있죠.위의 문장이 주어질 때,모델은it이dog인것을 어떻게 알 수 있을까요?이때 셀프어텐션이 필요합니다.
이 문장이 입력되었을 때,모델은 가장 먼저 단어‘A’의 표현을,그다음으로 단어‘dog’의 표현을 계산한다음, ‘ate’라는 단어의 표현을 계산합니다.각 단어를 계산하는 동안,각 단어의 표현들은 문장안에 있는 다른모든단어의 표현과 연결해 단어가문장내에서 갖는 의미를 이해하게 되는 것입니다.어텐션을 사용할 때 헤드 한 개만 사용한 형태가 아닌,헤드 여러 개를 사용한 어텐션 구조를 멀티헤드어텐션이라 부릅니다.
트랜스포머는RNN과 같이 순환 구조를 따르지않고,단어 단위로 문장을 입력하는 대신에 문장 안에 있는 모든 단어를 병렬 형태로 입력하게 됩니다.그러나 병렬로 연결하기 때문에 한가지 문제가 발생하는데,단어의 순서 정보가 유지되지 않은 상태에서 문장의 의미를 어떻게 이해할 수 있냐는 점입니다.문장의 의미를 이해하기 위해서는 단어의 순서가 중요하기 때문에,트랜스포머에 단어의 순서 정보또한 제공하게 됩니다.
다음으로 디코더에 대해서는 간략히 설명하도록 하겠습니다.
디코더는 인코더의 결과값을 입력값으로 사용하게 되는데요.
디코더역시 인코더처럼N개를 누적해 쌓을 수 있습니다.디코더 출력값은 그 위에 있는 디코더의 입력값으로 전송되며,인코더의 출력값은 모든 디코더에 전송이 되게 됩니다.즉,디코더는 이전 디코더의 입력값과 인코더의 출력값(표현)이렇게2가지를 입력데이터로 받습니다.
원하는 문장을 생성하는 과정을 들여다보면,시간 스텝1에 시작을 알리는<sos>가 입력되며 첫번째 단어인je을 생성합니다.이후je와 표현 정보 넣고 다음 문장을 생성합니다. 이 과정을 반복합니다.
이후 인코더와 마찬가지로 디코더 입력값에 위치 인코딩값을 더해 디코더의 입력값으로 사용합니다.
하나의 디코더 블록은 다음과 같은 요소들로 구성됩니다.디코더 블록은 인코더 블록과 유사하게 서브레이어에 멀티헤드~와 피트포워드 네트워크를 포함합니다.그러나 인코더와 다르게 두가지 형태의 멀티헤드어텐션을 사용합니다.그 중 하나는 어텐션 부분이 마스크된 형태입니다.
앞서 언급했던 셀프 어텐션은 각 단어의 의미를 이해하기 위해 각 단어와 문장 내 전체 단어를 연결했었던것과 다르게,디코더에서는 문장을 생성할 때 이전 단계에서 생성한 단어만을 입력문장으로 넣는다는 점이 중요합니다.즉,이런 데이터의 특성을 살려 모델학습을 진행해야하는 것입니다.모델이 아직 예측하지않은 오른쪽의 모든 단어를 마스킹하고,학습을 진행하게 됩니다.
이러한 마스킹 작업은 셀프 어텐션에서 입력되는 단어에만 집중해,단어를 정확하게 생성하는 긍정적인 효과를 가져옵니다.디코더는vocab에 대한 확률 분포를 예측하고,확률이 가장 큰 단어를 선택하는 방식입니다.
최종적으로 인코더와 디코더를 결합한 형태는 다음과 같습니다.
다시 정리하면,입력 문장을 입력하면 인코더에서는 해당 문장에 대한표현을 학습하고,그 결과값을 디코더에 보내면 디코더에서 타깃 문장을 생성합니다.또한 우리는 손실 함수를 최소화하는 방향으로 트랜스포머 네트워크를 학습시킬 수 있겠습니다.
지금까지 Transformer 모델이 무엇인지에 대해 간략히 살펴보았습니다.
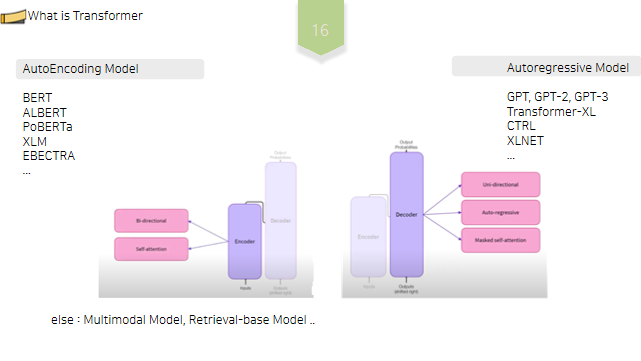
Encoder만을 사용한 모델은AutoEncoding Model, decoder만을 사용한 모델을Auto regessive Model, Encoder및Decoder를 모두 사용한 모델은Sequence to Seqence model이라고 부릅니다.그 외에도Multimodal Model, Retrieval-base model등 다양한 종류가 존재합니다.
Decoder에 기반한 모델,즉Auto regressive모델에는GPT, GPT2, Transformer-XL, CTRL, XLNet등이 있고, Encoding에 기반한 모델에는BERT, ALBERT, RoBERTa, XLM, EBECTRA등이 있습니다.
이 중에서 저희가 오늘 집중해 살펴볼 모델은transformer-Encoding based모델인BERT와XLM입니다.
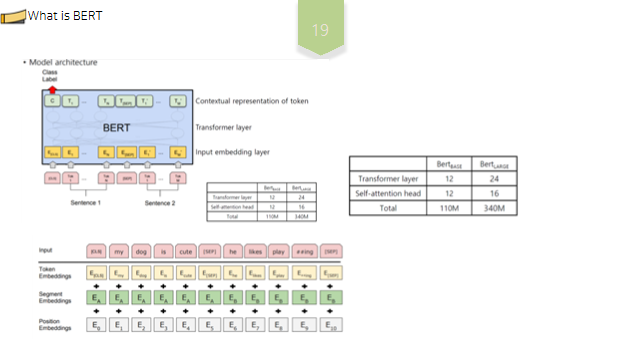
BERT는 가장 널리 사용되는 고성능 텍스트 임베딩 모델로, Bidirectional Encoder Representations from Transformers의 약자입니다.다양한 자연어 처리 태스크 분야에서 가장 성능이 뛰어나며,자연어 처리가 전반적으로 한걸음 나아가는데 이바지 한 모델입니다.BERT는18년에 논문이 공개된 구글의 최신Language Representation Model이며,말씀드렸듯이 인코더 구조만을 활용한 언어 모델입니다.
BERT가 성공한 주된 이유는 문맥을 고려한 임베딩 모델이기 때문입니다.그렇다면 문맥을 고려했다는 의미가 무엇일까요?다음 두 문장을 통해 문맥 기반 임베딩 모델과문맥 독립 임베딩 모델의 차이를 이해해보도록 하겠습니다.
A문장과B문장을 보면,두 문장에서“파이썬”단어의 의미가 서로 다르다는 것을 알 수 있습니다. A문장에서 파이썬이라는 단어는 뱀의 한 종류를의미하고, B문장에서 파이썬이라는 단어는 프로그래밍 언어를 의미합니다.워드투벡터와 같은 임베딩모델을 사용해 두 문장에서 파이썬이라는단어에 대한 임베딩을 얻는경우,두 문장에서 동일한 단어가 쓰였으므로 동일표현.반면BERT는 문맥기반.문맥이해후 다음문맥에따라 임베딩생성.따라서 서로다른임베딩 제공.
그렇다면BERT는 어떻게 작동하는것일까요?
먼저A문장 살펴봅시다.
BERT는 모든 단어의 문맥상 의미를 파악하기 위해 문장의 각 단어를 문장의 다른 모든 단어와 연결시켜 이해합니다.“파이썬”문맥상 의미를,BERT는 파이썬이라는 단어를 가져와서 문장의 다른 모든 언어와의 관계 기반 이해를 시도합니다.따라서 BERT는 파이썬이라는 단어와물었다라는 단어의 강한 연결관계 파악후 뱀의 한 종류 의미 파악이 가능하게 되는 것입니다.
B문장또한 마찬가지로 모든 단어를 연결합니다.이를 통해 B 문장의 파이썬이,프로그래밍이라는 단어와 관련있음을 인지.
BERT는L, H, A파라미터에 따라 성능 및 버전이 달라지게 되는데,여기서Layer는Transformer블록의 숫자이고, H는hidden size, A는Transformer의Attention block숫자입니다.즉, L, H, A가 크다는 것은 블록을 많이 쌓았고,표현하는 은닉층이 크며, Attention개수를 많이 사용하였다는 뜻입니다.블록을n번 쌓았다는 의미는 즉 입력 시퀀스 전체의 의미를n번만큼 반복적으로 구축하는 것을 의미합니다.
또,앞서 잠시 언급드렸듯 생성된Token Emdedding과 함께,각 토큰의 위치정보를 임베딩하는Positional Embedding과,문장을 구분하는segment embedding까지 총3개의 임베딩을 결합하여 임베딩을 표현합니다.
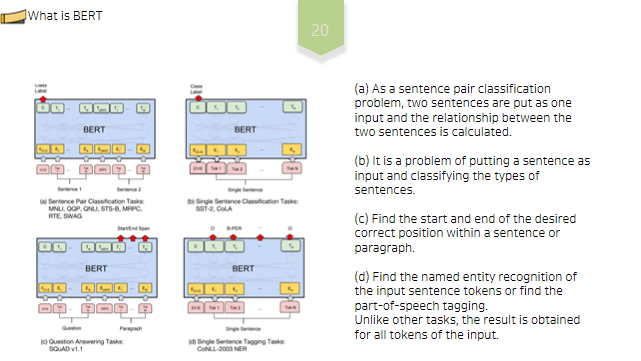
BERT를 각Task에 쓰기위한 예시는 다음의 그림과 같습니다. (a)는 문장 쌍 분류 문제로 두 문장을 하나의 입력으로 넣고 두 문장간 관계를 구한다. (b)는 한 문장을 입력으로 넣고 문장의 종류를 분류하는 문제이다. (c)는 문장이나 문단 내에서 원하는 정답 위치의 시작과 끝을 구한다. (d)는 입력 문장Token들의 개체명(Named entity recognigion)을 구하거나 품사(Part-of-speech tagging)를 구하는 문제이다.다른Task들과 다르게 입력의 모든Token들에 대해 결과를 구한다.
다음으로BERT의 사전학습에 대해 설명드리겠습니다.사전학습이란 무엇일까요.
모델을 하나 학습시켜야한다고 가정해봅시다.일단 특정 태스크에 대한 방대한 데이터셋으로 모델을 학습시키고 학습된 모델을 저장합니다.그 다음,새 태스크가 주어지면 임의 가중치로 모델을 초기화하는대신,이미 학습된 모델의 가중치로 모델을 초기화합니다.즉,모델이 이미 대규모 데이터셋에서 학습되었으므로 새 태스크를 위해 새로운 모델로 처음부터 학습시키는 대신 사전학습된 모델을 사용하고,새로운 태스크에 따라 파인튜닝하는 것입니다.
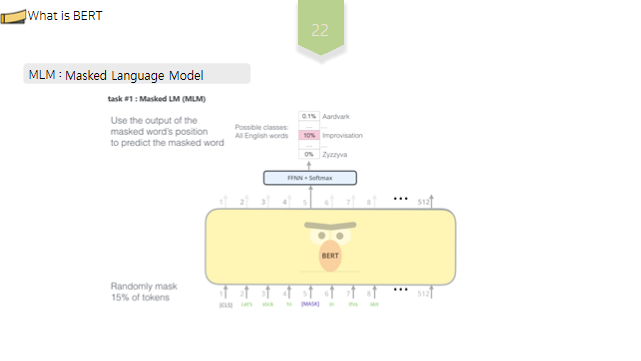
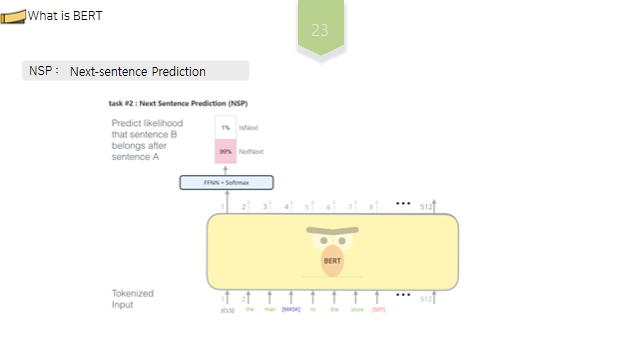
BERT에서는MLM과NSP라는 두 가지 태스크를 이용해 거대한 말뭉치를 기반으로 사전학습,자가 지도 학습이 이루어집니다. MLM은Masked Language Model, NSP는Next-sentence Prediction ,의 약자입니다.
간략히 설명하면, MLM이란,문장을 고의로 훼손시킨 후 이를 소스 문장으로 복원하는 방법론으로,해당 과정에서는 입력문장의15%에 해당하는 토큰을 임의로 선택하여,선택한 토큰 중80%는MASK토큰으로, 10%는 임의의 다른 토큰으로,그리고10%는 기존 토큰 그대로 두는 방식으로 훼손시킵니다.즉 레이블이 없는 단일 언어 말뭉치에서,기존 문장을 고의로 훼손시키고,소스 문장으로 복원함으로써,언어에 대한 양방향적 문맥을 파악할 수 있게됩니다.
NSP란 입력문장을 구성할 때, 50%는 기존의 순서대로 ㅇㄴ속된 문장을, 50%는 임의로 선택된문장을 연결함으로써 두 문장간의 문맥적 의미를 파악하는 작업을 의미합니다.두 문장이 연속된문장일때는1을,연속되지않은 문장일때는0을 도출하게함으로써 문장간 연관성이 타당한지를 판별하는 작업을 학습합니다.
이렇게 사전학습을 마친 단어 임베딩은 말뭉치의 의미적,문법적 정보를 충분히 담고있어,훈련되지 않은 언어에 대해서도 우수한 수행능력을 보이며,다운 스트림 테스크를 수행하기위한 파인튜닝 추가학습을 통해 임베팅을 다운스트림 태스크에 맞게 업데이트 하는 방식으로 이루어집니다. BERT가 등장한 이후로는 특정 자연어 처리 관련 문제를 풀기 위한 연구의 방향성이 사전 학습된 모델을 어떻게 활용할 것인가”로 바뀌고 있다고 합니다.
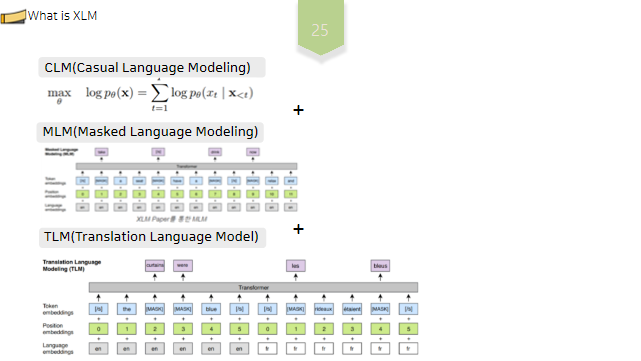
XLM또한transformer-인코더 베이스의 모델입니다.이때BERT에서 활용된MLM뿐 아니라, CLM, TLM을 추가적으로 활용하여 단일 언어 표현을 완화하고 다양한 언어,즉 다국어에 대해 모든 문장을 공유 임베딩 공간으로 인코딩 할 수 있는 범용 교차언어 모델을 구축할 수 있게되었습니다. XLM은 다양한 언어에 대해 공일한 공유 어휘를 사용합니다.이는 모든 언어의 토큰에 대한 공통된 임베딩 공간을 설정하는데 도움을 줍니다.
CLM이란 이전 토큰들을 기반으로 다음 토큰을 예측하는 작업을 의미하며,모델은 훈련과정에서 확률p를 모델링 합니다.즉, XLM모델은CLM을 학습하는 과정에서,이전토큰을 통해 다음 토큰을 예측함으로써 문장 구조에 대한 이해를 얻게됩니다.
TLM이란 병렬 말뭉치에 존재하는 소스 문장과 타겟문장을 하나의 입력으로 연결한 후, LML과 같이 문장 일부를MASK로 치환하고 이를 소스문장으로 복원하는 작업을 의미합니다.이를 통해 모델은 서로 다른 언어간의 연관성을 더 잘 파악하게 됩니다.
즉, XLM은 여러 언어데이터를 활용한MLM과CLM, TLM학습을 통해 여러 언어에 대한 교차언어 정보를 학습하게 됩니다.
이러한XLM을 이용한 다국어 언어 모델은 일반적인 다운스트림 작업에서 더 나은 결과를 얻는데 도움이 되고,유사한 높은 리소스에 대한 학습을 통해,낮은 리소스 언어에 대한 모델의 품질을 개선할 수 있습니다.
Brain-age delta 는 알츠하이머 등의 병의 진단에 있어 효과적인 바이오마커입니다.
연구에서 사용한 데이터셋은 UK-Biobank, PAC2019 의 2가지 이며,
두 데이터셋 모두 T1-weighted-structural MRI 3D brain image 를 제공합니다.
아래의 이미지 T1-weighted MRI 의 예시입니다.
MRI는 수집 및 처리하는 방식에 따라 다양한 종류로 나뉘는데, 그중에서도 T1-weighted MRI image는, T1 강조기법을 사용한 MRI 종류힙니다.
T1 강조영상은 짧은 TR과 짧은 TE를 이용한 스핀에코 기법으로, 조직의 T1 이완시간의 차이를 신호차이로 반영하는 기법입니다. 짧은 TR 을 사용함으로써 조직 간 종축 자기화의 회복정도가 크게 차이나게 되는데, 이를 신호 차이로 반영하는 기법입니다.
모델로는 Simple Fully Convolutional Network, SFCN 을 사용합니다.
즉, VGGnet을 base로 하여 3D CNN 을 이용해 모델링을 합니다. (기존의 2D VGGnet을 3D VGGnet 으로 변경함)
논문에서는 항상 3x3 필터를 이용해 convolution 을 하여, 보다 파라미터를 적게생성하고 층을 늘리는 lightweight 전략을 세웠습니다.
또한, 뇌연령 예측임에도 회귀 분석을 한 것이 아니라, 각 데이터셋별 1년, 2년 단위로 target값을 끊어서 총 40개의 구간(Class)으로 연령대를 만들어서, 다중분류를 하였습니다. (softmax 이용)
연구진은 단일 모델뿐 아니라, 다양한 접근 방식을 비교해가며 다양한 모델을 만들었는데요.
한가지 예로, 3D image 인 MRI를 여러 기법으로 전처리하여, 한 MRI 이미지에서 a linear image, non linear image, GM image, WM image 의 네가지 타입의 이미지를 추출하고, 각 이미지들을 복합적으로 이용해 뇌연령을 예측합니다.
아래의 매트랩에서 각 4가지 타입의 이미지데이터에 대해, 모델을 5개씩 만들어 예측값과 실젯값의 correlation 결과를 분석하였음을 확인할 수 있습니다.
이때 5개의 모델은 모두 같은 아키텍처를 이용해 하이퍼파라미터만 다르게하여 학습한 모델로, (파라미터만 다르게)
각각의 모델에서 예측한 결과값의 mean으로 앙상블 모델을 만든것을 확인할 수 있습니다.
맨 아래 ensb 이라고 표시된 그림이 앙상블 했을때의 correlation 결과값인데요. 모든 데이터셋에서 0.9 이상의 결과를 얻은 것을 확인할 수 있었습니다.
이 결과값은 모델의 예측값과 실제값의 Stability가 보장이 된다는 것을 확인할 수 있는 결과이며,
동시에 다양한 데이터를 이용해 정확도를 높이기 위함으로, 논문에서는 이 모델을 Semi-multimodal model 이라고 부릅니다.
뇌연령 예측 연구에서, 대개 나이가 상대적으로 어린 피험자는 나이가 더 높게 나오고, 나이가 상대적으로 많은 피험자는 나이가 더 낮게 예측되는 경향이 있는데,
연구진들은 이러한 Bias를 Correction 해주었습니다. 그림1 -> 그림2 -> 그림3 으로 갈수록 correction이 된 것을 확인할 수 있습니다.
결과적으로 선행 모델보다 높은 성능을 보이며,적은 데이터셋을 학습시킬때도 성능이 좋게 나올 수 있도록 모델을 비교하며 시도하였습니다. 또한, 최종 모델은 뇌연령뿐아니라 성별예측에서도 높은 정확도를 보였습니다.