댓글분석 웹페이지 개발 프로젝트와는 달리, 주가예측 프로그램 개발 프로젝트의 경우 모델링에 대한 고민이 꾸준히 필요하기 때문에, 모델에 대한 변동이 발생할때마다 추가적인 게시글을 업로드 할 예정입니다.
1. 현재 문제점 LSTM 모델을 사용하기 때문에, 전날의 데이터가 영향을 크게 끼쳐서 실제 종가의 증감과 거의 무관하게 전날과 비슷한 값이 모델의 예측 결과값이 됨. (즉, loss가 가장 작아지는 값이 전날의 값이라고 계산하는 것) 따라서 모델의 정확도는 높지만(loss=0.01미만,R^2=0.98이상), 실제 데이터로 예측 시 증가하다 감소하는 구간, 감소하다 증가하는 구간을 판별하지 못하는 크게 유의미하지 않은 모델이 된 것으로 판단됨. 이에 대해 고민이 필요함.
2. 해결 방안 및 추가 기능 1)기존의 input값(시가, 고가, 저가, MSCI, KOSPI, KOSDAQ 등)들을 모두 Stationary하게 변환(‘오늘 값-전날 값’ 으로, 변동 값을 볼 수 있도록) -> 평균, 분산, 공분산이 비교적 일정한 데이터로 전처리 2)기존에 학습시키던 예측 값을 ‘종가’값이 아닌 +(전날보다 증가), -(전날보다 감소)로 Binary 한 항목 값으로 변환해 학습시켜서, 더 유의미한 모델이 될 수 있도록 함. 이후 모델 평가시에도 +로 예측하여 +인 것, -로 예측하여 -인 것의 Accuracy 확인(지금의 loss보다 더 의미 있는 지표가 될 것) 결과는 +or-로 반환(추후 오를 확률/내릴 확률 계산하여 반환) 3)input종목에 대한 SNS언급량(네이버금융_종목토론방)을 가져와 긍정 부정을 판별하고, 결과에 대해 가중치를 두어 추후 모델의 output값과 더해 최종 예측 결과의 정확도를 높임. 4)기본 데이터의 기본 모델에 대한 정확도, 상관 계수 추세로 구분된 각 군집 데이터를 각 군집에 최적화된 모델에 넣은 정확도의 평균, 종가 추세로 구분된 각 군집의 데이터를 각 군집에 최적화된 모델에 넣은 정확도의 평균을 구해 비교 후 의사결정 추후) 노이즈 제거 관련 논의하기
3. 역할 분담(~9.26(일)) 1)한 종목에 대해 SNS언급량 긁어와서 데이터를 쌓은 후, 긍정/부정 판별(네이버금융-종목토론방-글 댓글-최근1000개) 2) input값을 stationary하게, output값을 binary하게 변환해서 학습시킨 후, Accuracy/loss확인 및 개선시키기 3) 모델 개선에 도움이 될 만한 추가 외부변수를 생각하고, 해당 변수의 10년치 데이터 가져오기(약5개정도,재량적으로)
방학동안 연구 주제를 세부적으로 구상해가려고 했었는데, 교수님께서도 따로 생각해두신 연구 주제가 있으시다고 하셔서 간략하게만 조사해갔다. 대강 말하자면, 이번에 하고싶던 분야가
"종양미세환경에서의 면역항암 치료예측 인공지능 바이오마커(조직 분석 시스템) 연구 : 데이터 기반의 이미징 바이오마커를 통해 의사의 진단 및 치료과정의 정확성과 효율성 향상"
이었다. 교수님께서는 데이터 수집이 다소 어려워보일뿐 충분히 할수있는 분야라고 하시며 교수님께서 생각해두신 주제와 고민해보라고 하셨다. 교수님께서 생각해두신 주제는,
"뉴로 사이언스 분야 논문들을 분석해 향후 영향력이 클 논문을 판별/예측 하는것"
이었다. 그래프역학/네트워크 분석 등을 사용하는 연구인데, 이미 '생명공학'분야의 논문을 대상으로 같은 주제를 분석한 연구가 있어, 그 연구를 벤치마킹하자는 것이었다. 주제를 내가 원하는 주제인 '뉴로 사이언스'분야로 변경하고, 모델 알고리즘을 뜯어보며 이해한 후 모델을 개선시키고, 기존 모델과 내 모델의 기존 데이터를 넣었을때의 정확도와, 뉴로 사이언스 분야의 논문들을 넣었을때의 정확도를 비교하려하였다. 해당 연구에서는 데이터셋 수집 및 저장 툴, 코드가 저장되어 있는 깃허브 등을 모두 제공하기에 가능한 것이었다.
그런데, 막상 깃허브의 폴더 및 파일들을 확인하니.... 중요한 코드들이 다 빠져있었다. 해당 연구를 진행하며 만든 사이트의 프론트엔드에 쓰이는 파일들만 개방되어있고, 모델의 코드를 포함해 중요한 내용이 없었다. 또, 시범을 돌려볼 수 있도록 제공한다는 예시 데이터셋과 예시 모델, 파라미터들도 전송 기간이 만료되었다며 받을 수 없었다. 무슨 일인지 만들어둔 사이트는 정상적인 작동이 되고 있지 않았다. 아마 연구 논문을 게재한 후 일정 기간이 지나 내린것 같았다.
9.10일,
기존 논문 벤치마킹의 문제점을 포함한 기존 연구에서 쓰인 분석 기법, 데이터 수집 및 저장 툴 등등을 더 세부적으로 조사해서 교수님께 보여드리니 교수님께선 핵심 코드가 없다면 굳이 우리가 이걸 할 필요가 없을것 같다며, 좀 더 생각해보신다고 하셨다. 아마 이 주제는 폐기하고 다른 주제를 생각해봐야할 것 같다. 캡스톤 디자인 주제도 마침 생각해둬야하니, 내일 오래간만에 도서관에 가려한다. 도서관에서 책도 읽고, 인터넷으로 관련 저널 및 논문 서칭도 하고, 마침 알고있는 인공지능 관련 연구 업무를 하시는 멘토님께 조언도 구해봐야겠다. 다음주 월요일까지 캡스톤 디자인 주제 후보 2개, 다음주 목요일까지 개인 연구 주제 후보 2개정도 생각해 둘 생각이다.
연구 주제 선정과 함께 교수님께서 내게 주문하신 당분관의 활동은 다음과 같다.
1. 도메인 지식 습득
2. 최근버전 리뷰 페이퍼 작성
3. 맡은 주제 연구 진행---> 주제 고민으로 변경
4. 각종 뇌영상 데이터 이해 후 전처리 과정을 위한 각종 SW 학습
최신 버전 리뷰 페이퍼를 작성하다보면 자연히 도메인 지식은 습득될 수 밖에 없고, 주로 분석에 사용되는 각종 SW의 명칭 정도는 익힐 수 있을테니 리뷰 페이퍼 작성먼저 할 생각이다. 주제 고민과 함께 기존에 발행된 리뷰 페이퍼부터 예시로 읽고, 주제 선정 및 리뷰페이퍼 작성 완료 후 뇌영상 데이터 이해 및 각종 SW 학습을 하며 연구를 진행해야겠다.
Data는 Lens API에서가져오기때문에이미명확하다고할수있으나, 추가적으로명확하게끔하는기법도입. 가령node가저자라면, Microsoft Academic ID와ORCID id 등으로hash함. 이러한해시맵을사용해중복ID가없는지모든저자의노드를식별하고병합함. 또, 모든edge에대해인용된논문이인용한논문전에발행된게맞는지재확인함. 모든저널의노드에대해중복이나복제가존재하지않는지확인함.
Biotechnology knowledge graph를 사용해 기계학습 파이프라인의 기능으로 사용하는 출판, 저자 매트릭의 시계열을 계산함. 메트릭은 1)논문 수준 메트릭, 2)저자 수준 메트릭, , 3)저널 수준 메트릭, 4)네트워크 수준 메트릭의 4가지 기본 범주로 나뉨. 각 메트릭에 대해 그래프의 구조를 사용하여 원하는 값을 계산하는 알고리즘 구현. (일반적으로 사용되는 메트릭과, 강조 표시된 작업에서 사용된 기능에서 수집된 메트릭을 통해 구현함)
1)논문 수준. : 각 논문에 대해 1980~2020 사이 출판된 데이터세트의 논문에서 인용한 논문 수를 계산. 이 계산을 이용해 각 논문의 다른 인용 기반 속성을 계산함. (총 논문 수, 총 인용 수, 연간 인용 수 등)
2)저자 수준 : 각 저자에 대해 이전예 계산한 논문 수준 메트릭을 집계해 관심 있는 추가 저자 수준 메트릭 도출. 저자의 h-index, 첫번째 논문의 출판 이후 연도, 총 논문 수, 인용 횟수 등이 포함됨.
3)저널 수준 : 그 후 논문수준, 저자 수준 측정항목을 모두 사용해 각 저널에 대한 집계된 측정 항목 계산. 저널의 논문 수, 최대 인용 횟수와 같은 측정항목 포함. 각 저자에 대해 각 저널 수준 매트릭에 대해 해당 저자가 출판한 모든 저널의 최대값, 평균값, 최소값이 저자에게 다시 집계됨.
4)네트워크 수준 : 위의 인용 및 문헌 기반 메트릭은 그래프의 구조와 관계의 다양성을 포착하기에 충분하지 않을 수 있음. 따라서 비지도 방식을 이용해, 해당 논문이 존재하는 각 연도에 대해 방향성 설정 및 80단계 랜덤 워크, node2vec알고리즘을 사용하는 로컬 인용 네트워크 구조를 기반으로 하는 각 논문에 대한 연속적인 특징 표현을 학습시킴.
위의 세부적인 내용은 아래의 테이블에서 확인 가능함.
Machine Learning)
위에서 나열된 metric을 입력data로 하는 기계학습 파이프라인 개발.
1-네트워크 데이터베이스에서 데이터를 추출해 논문 수준으로 집계
2-각 논문에 대해 출판 연도부터 출판 연도 5년후까지 최소 1번 이상 인용된 모든 논문에 대해 위에서 설명한 모든 메트릭을 계산함.
3-저자 정보가 누락된 모든 논문을 제거해 약 150만개(원래 160만개였음)의 출판물을 남김
4-‘영향력 있는’ 논문 정의 : 출판 후 5년 후에 해당 연도의 전체 점수 중 상위 5%에 시간 환산된 pageRank 점수가 있는 경우
5-추적할 특정 연도를 입력하면, 특정 연도로부터 5년 이후 까지의 모든 데이터를 불러와 훈련(75%) 및 테스트 데이터(25%)셋으로 분리. 이 때, 합성 소수 오버 샘플링을 적용해 균형 잡힌 훈련셋을 생성함.
6-측정된 값을 직접적으로 비교할 수 있도록 계산된 메트릭에 대한 사전 처리를 수행함.
7-Train data가 주어지면 가능한 모델 매개변수의 그리드에서, 훈련 데이터에 대한 교차검증을 수행해 최적화할 때 기계 학습 모델을 훈련함. 본 연구에서는 랜덤 포레스트 분류기를 사용함.(감소된 과적합 위험, 예측 분산의 잠재석 감소 및 비선형 관계를 캡쳐하는 능력 때문.)
8-네트워크 수준 기능이 모델에 상당한 차원을 추가하기 때문에, 이러한 기능을 포함해 모델의 성능이 향상되거나 저하되는지의 여부를 검사하고 가장 성능이 좋은 모델을 선택
9-보류 테스트 데이터에 대해 이전에 계산된 실제 영향 레이블과 영향 예측을 비교해 모델의 성능을 평가함.
->최종모델: 780만개이상의노드, 2억 100만개관계미 38억개계산된매트릭
-> 과학논문의자금조달포트폴리오구축을지원하는도구개발. DELPHI(Dynamic Early-warning by Learning to Predict High Impact)
사실 위의 1~5 순위 모두가 나에게 너무너무 중요한 요소지만, 이번학기는 무엇보다도 학점에 좀 신경을 쓰려한다.
내 영혼의 단짝을 침대에서 책상으로 바꿔야지... 책상에 앉아있는 시간을 대폭 늘리려 노력해야겠다.
이번 학기 수강 과목들의 해야할 과제를 정리해보면 다음과 같다.
* 특히 주제를 생각해봐야할것..
- 학부연구생 : long-term Project 연구주제
- 데분캡 : 졸논 준비겸 팀과제 <- 전 작품들 주제 확인해보자
* 그 외 과제들..
- 인공지능론 : 인공지능 구현과제 +a
- 산경알고리즘 : 알고리즘 선정 후 구현과제
- 객체지향 : Lab평가, Proj1, Proj2
- 기계, 데센프 : 주기적인 개별과제
당장의 내가 해야하는것은 학부연구생 및 데분캡의 주제를 생각해보는 것이다.
학부연구생은 교수님께서 미리 생각해두신 주제가 있는 것 같다. (최신의 생명공학 분야 논문들 중 미래에 영향력이 있을 논문을 미리 판별(예측)하는 기법을 연구한 논문을 읽어보라고 하셨다. 이 논문과 관련해서 어떤 주제를 생각하고 계신건지 궁금하다! 일단 이것과 별개로 내 의견을 물어보신다고 하니 주제를 3~4개정도 생각해가기로 했다.) 내일 실시간 강의 다 듣고 교수님을 뵈러 가는데 걱정이 앞선다. 단독 대면은 역시 떨려...
데분캡 팀 프로젝트의 주제는 팀원들과 함께 정해야하는데, 관심 분야를 써둔 스프레드시트를 보고 나와 관심분야가 비슷한 분들께 연락을 해서 팀(3인)을 이뤄뒀다. 마침 한 분이 나와 같은 지도교수님 밑에서 연구생을 하더라. 교수님이 오신지 얼마 안돼서, 내가알기로 학부연구생이 1~2명 있다고 했던것같은데 어떻게 우연히 같은 수업에 같은 팀이 되었네.. 다른 팀원 분도 또 다른 교수님 밑에서 연구를 하더라. 비대면이라 다른 학우들을 만날 일이 없고 연락하는 친구도 없어서 다른 학우들은 어떻게 사는지 몰랐는데, 새삼 다들 안보이는 곳에서 열심히 노력하고 있구나 싶었다. 나도 열심히 해야지.
오늘은 밖에 비가온다. 요즘 왜인지 마음이 싱숭생숭 울적한데 어둑어둑한 방에서 빗소리와 함께 잔잔한 노랫소리를 들으니 조금 힘이 나는 것 같다. 마음이 울적한건 아마 운동을 안해서(+이번주는 생산적인 활동을 안해서) 그런 것 같다. 고등학생땐 체력 기르는것도 중요하다고 야자 쉬는시간마다 학교 테라스에 나가서 친구들이랑 줄넘기하고, 운동장에서 달리기하고.. 점심 저녁먹고 남는시간에 강당가서 배드민턴치고.. 야자 끝나고 집에오면 1-2시간 홈트레이닝할때도 많았고 주말에도 근처 호수공원 달리고 롱보드탔었는데. 그리고 대학 1학년때는 춤 동아리에서 춤추고, 알바하고 간간히 놀러다니고 해서 어느정도 운동량이 있었는데.. 그 후로 2년정도는 아예 운동을 안했으니... 몸을 안쓰니 간간히 우울해지는것같다. 앞서 언급한 1, 1.5위 우선 순위 만큼이나 운동이 중요하다고 생각해서 집에서도 할 수 있는 운동! 실내자전거랑 홈트레이닝용 요가매트를 샀다. 내일 배송오면 매일매일 30분씩 자전거 타야지.
밤에 창문 밖을 내다보면 불빛을 켜고 도로위를 달리는 자동차들이 보이는데 그 자동차들을 계속 보게되더라. 요즘 밖엘 안나가서 그런가 창문 밖을 자주 내다보게 되는 것 같다. 새로운 내 방 너무너무 좋지만 가끔은 밖에서 혼자서라도 산책해야겠다.
8월 활동보고!! 여름방학의 막바지, 8월달은 학우들을 위해 이것저것 프로그램을 준비해봤답니다!
가장 먼저, 여름방학은 아직 끝나지 않았다! 방학동안 역량쌓기 막판 스퍼트로, 남은 여름방학 기간중에 하기 좋은 교내 프로그램/교외 프로그램/ 대외 활동/ 공모전을 소개하고, 개강 이후 역량쌓기 좋은 활동들도 소개하였습니다.
저번 역량쌓기 프로그램 안내는 산업경영공학과 학우 맞춤형 프로그램들이 많았는데(3D프린터 교육, 금융 관련, 데이터분석 관련 등..) 이번에는 찾아보니 맞춤형 프로그램보단 모두 관심있어할만한 활동들이 더 많았어요. (살짝 아쉽..)
저는 자료조사를 맡아 활동들을 조사하였습니다! 좋은 외부활동도 많지만, 경희대학교 소융/컴공/산공/SW사업단/공학혁신교육센터/알라딘/ 등등에서 주관하는 좋은 내부 행사들이 많아 학우들이 잘 알고 신청해서 역량을 쌓을 수 있었으면 좋겠습니다.
다음으로 산업경영공학과 학생회 일원들과 함께하는 QnA Time 행사를 진행하였습니다. 저희는 평소에도 소통함을 열어 질문들을 받고 있고, 공과대학 학생회 차원에서도 별도로 소통함을 만들어 질문을 받고 있는데요. 소통함에 잘 올라오지 않는 개인적인 (학업에 관한) 궁금증이나 고민들을 나누는 취지로 행사를 진행하였습니다. 저도 이날 행사에 참여하여 학우들의 이런저런 궁금증, 고민들을 들어주고 답변 해주었답니다. (제가 잘 알고있는) 타학과 복전에 관한 것, Tensorflow 관련 등의 질문이 가장 기억에 남는데요. 다른 학생회 분들이 잘 모르는 부분을 제가 답변해 줄 수 있어 기뻤습니다.
저희 학교는 현장실습 학점인정 제도가 있습니다! 현장실습에 관심있는 학우들을 위해 관련하여 상세한 내용을 안내해드렸습니다.
저희는 매 학기 수강신청 이후, 수강하고 싶으나 수강신청에 실패한 학우들을 위해 전공과목 추가인원 수요조사를 진행합니다. 수요조사 결과를 각 과목의 교수님께 전달드리고, 교수님의 해결 방안을 다시 학우들에게 전달하는 방식입니다. 보통은 수요만큼 교수님이 수강 인원을 늘려주시는 편입니다.
저희 학과의 졸업 요건 중 하나가 '창의적 종합 설계' 과목의 수강인데요, 수강하는 학우들과 팀을 이뤄 원하는 주제에 대해 탐구하는 프로젝트 과목입니다. 사실상 이 과목으로 졸업논문을 대체하는만큼 중요한 과목이라 할 수 있습니다.
지금까지는 같은 주제를 원하는 학우들을 찾고 팀을 이루는 과정에 불편함이 있었다고 하는데요, 그런 학우들을 위해 학생회 차원에서 창종설 팀 구인 플랫폼을 만들어 더 수월히 구인을 할 수 있도록 도와드렸습니다. 플랫폼을 어떤 것으로 할지 고민을 많이 했었는데, 학우들의 개인정보 보호를 위해 쉽게 만들었다 파기할 수 있는 플랫폼으로 진행하였습니다.
2020학년도 후기에 학위를 수여하시는 선배님들을 위해 축하 현수막을 제작하였습니다. 선배님들 졸업 축하드립니다. 대면이었어야 하는데.. 너무 아쉽네요. 코로나가 얼른 끝나서 대면으로 축하드릴 수 있었으면 좋겠습니다. ㅠㅠ
2021년 초에 산공과 새내기 가이드북을 만들어 안내해드렸었는데, 이번에 2학기를 맞아 중요 내용만 쏙쏙 뽑아 한번 더 안내해드렸습니다! 내용을 잊어버렸던 학우들이 유용하게 다시 읽으셨으면 좋겠네요.
저희 학과 커리큘럼 중 '연구연수활동' 과목이 있는데요, 이 과목은 담당 교수님 아래서 원하는 주제에 대해 연구연수를 진행하는 활동입니다. 학부연구생이랑 비슷한 느낌이라고 생각하시면 될 것 같아요.
수업을 맡아 진행하시는 교수님의 연구분야에 따라, 그리고 시기에 따라 연구 주제가 매번 바뀌는데요. 각 교수님들께 이번 학기의 주제와 기타 사항들을 여쭤보고, 학우들에게 안내해드렸습니다. 수업을 듣길 원하는 학우들에게 도움이 많이 되었을 것 같습니다.
- 빅데이터 처리기술과 인공지능 기술을 이용하여 주가를 예측 및 분석하는 시스템 대신증권 open API 데이터를 이용하여 시가총액, 영업이익률, 환산 주가, 외국인 보유 비율, 오늘의 유망주(거래량, PER) 상위 10위를 출력한다. 종목의 이름 혹은 코드를 입력하면 미리 구현된 모델에 input되어 주가를 예측해 출력한다. 해당 종목의 시가총액, 영업이익률 등 투자정보와 종가그래프를 출력한다.
작품 구성도
작품의 개발배경 및 필요성
기술적 분석, 기본적 분석, 데이터 분석, 통계 기반 분석 등 주식 가격을 예측하려는 움직임은 꾸준히 있었지만 예측의 정확도는 크게 높지 않았다. 최근의 인공지능 기술은 알고리즘의 개선, 빅데이터 처리기술의 발달, 하드웨어의 발달로 매우 빠른 속도로 발전하고 있다. 이에 본 프로젝트에서는 발전한 인공신경망 알고리즘과 최신 ICT 기술을 이용하여 주가를 예측하고, 최적의 수익 창출 알고리즘을 찾아 예측의 정확도를 보다 높이려 한다.
작품의 특장점
오늘의 유망주, 시가총액 등의 다양한 지표에 대한 상위 종목을 참고할 수 있어 매매/매도시 더 신중할 수 있다. 전 종목의 상관 관계분석 및 군집분석을 적용한 종가 데이터의 세분화, 각 군집에 최적화되어있는 각 모델, 체계적인 알고리즘으로 더 정확한 예측값을 출력할 수 있다.
작품 기능
- 최적의 주식 매매, 매도 시점 포착을 위한 데이터 분석 결과 출력 - 항목별 상위 10위 종목을 제시하여 희망하는 항목에 대한 직관적인 지표 제공 원하는 종목의 기대 주가 및 추가 투자정보 제공 - 실제 주가 데이터와 예측 데이터 간의 차이 분석 및 제시
작품의 기대효과 및 활용분야
- 사용자가 가장 집중적으로 보는 상위 기업 지표, 각 종목의 투자정보와 더불어 주가예측 서비스를 도입하여 매매전략 수립에 여러 시각의 도움을 줄 수 있다. 종목을 군집화하고 각 군집에 최적화된 예측모델을 만들어, 타 주가 예측 프로그램보다 더 높은 예측 정확성을 기대할 수 있다. - 주식 매매 서비스 : 객관적 지표 외에 사용자가 선택적으로 열람할 수 있는 추가적인 정보로 주가예측 결과를 보여줄 수 있다.
본 문
I. 작품 개요
1. 작품 소개
1) 기획의도
- 주식 시장의 수치화된 정보, 지표를 분석하는 알고리즘을 설계, 구현하고 정보를 빅데이터 처리기술과 인공지능 기술을 이용해 주식가격 예측시스템을 구현한다.
- 지표들을 분석할 수 있게 설계한 알고리즘들을 실제로 테스트하고 성능을 비교하여 최적의 알고리즘을 채택하여 적용한다.
- 분석한 주식가격정보를 쉽게 알아볼 수 있는 서버를 구축하여 사용자의 접근성을 높인다.
2) 작품 내용
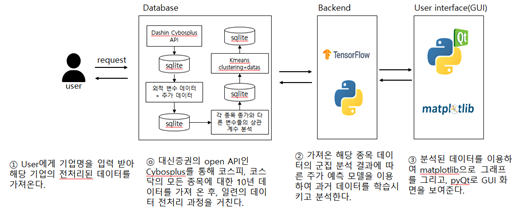
- 대신증권 open API를 통해 전 종목의 10년치 시가, 고가, 저가, 종가, 거래량, 시가총액, 외국인보유비율, 기관거래량, 코스피지수, 코스닥지수, MSCI, 다우존스지수, 나스닥, 항셍지수 데이터를 수집하고, SQLite를 이용해 DB를 구축한다.
- 종가 데이터에 대한 각 항목의 데이터를 상관관계 분석하고, 군집분석을 통해 종 가에 영향을 끼치는 요소가 비슷한 종목끼리 묶어 학습 데이터로 넣는다.
나눠진 5개의 군집에 대한 5개의 모델을 수립한다. 각 모델의 input data로는 군집 내 모든 종목에 대한 항목별 상관계수 평균이 일정값 이상인 항목만을 input 데이터로 선택한다.
군집 별 input데이터를 선정하고, 데이터 전처리 – Tensorflow를 이용한 예측 모델 구현을 거쳐 주식 가격을 예측한다. 각 군집 별 최적의 알고리즘을 찾아 정확도를 높인다.
PyQt를 이용해 GUI 프로그램을 개발해‘내일의 주식’프로그램을 만든다.
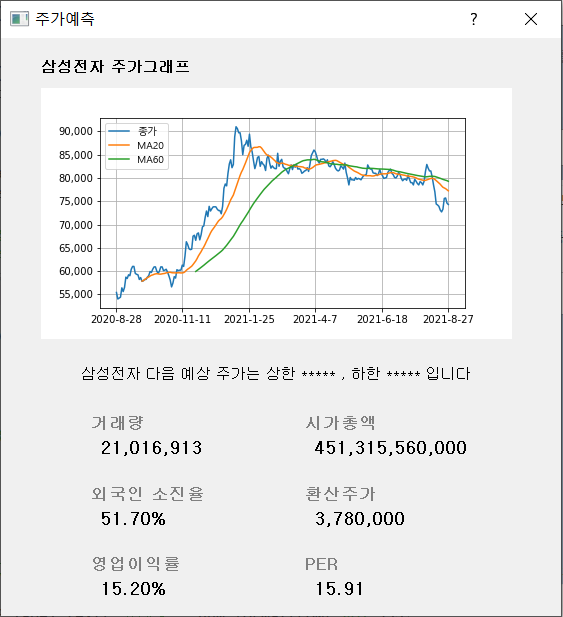
‘내일의 주식’프로그램에 다양한 항목에 대한 상위 10위의 항목을 출력하고, 분석을 원하는 종목의 이름/코드를 입력시 예상 주식 가격 및 기본적인 투자정보를 제공한다.
3) 정의
- 시가총액, 영업이익률, 환산주가, 외국인 한도 소진율, 오늘의 유망주(거래량, PER 기준)에 대한 상위 10위 종목을 보여주어 사용자가 쉽게 유용한 정보를 얻을 수 있다.
- 기업명 혹은 기업코드를 입력했을 때 주가(종가) 그래프 및 예측된 주식 가격을 포함해 해당 종목의 거래량, 시가총액, 외국인 소진율, 환산주가, 영업이익률, PER 등의 투자 지표를 출력해주어 원하는 종목에 대한 다양한 투자정보를 얻을 수 있다.
2. 작품의 개발 배경 및 필요성
1) 작품 제작 동기
- 코로나로 인해 주식 시장이 위축되어있는만큼, 지금 우리에게는 다양한 변수 기반 분석과 신뢰할 수 있는 참고 지표가 필요하다.
-인공지능의 강점은 방대한 데이터 세트 내 상관관계를 파악하는 능력이다. 이러한 상관관계는 시스템적 위험의 모니터링에 유용할 수 있다.
- 현재 4차산업혁명의 핵심기술인 빅데이터와 인공지능기술이 급격히 발전되었기 때문에, 이를 활용해 보다 발전된 알고리즘을 구현할 수 있다.
2) 작품 제작 목적
- 발전된 알고리즘을 이용한 예측 모델링을 통해 보다 정확한 예측결과를 얻을 수 있도록 한다.
- 투자자가 주목하는 여러 항목에 대한 상위 10위 종목 및 사용자가 분석을 원하는 종목에 대한 주가 그래프, 예측 주가, 그 외 여러 투자 정보들을 제공해 사용자가 더욱 쉽게 정보를 얻을 수 있도록 한다.
3. 작품의 특징 및 장점
1) 특징
- 단순히 예측모델만을 만드는 것이 아니라, 상관 관계분석-군집분석-군집별 예측 모델 수립을 통해 학습 데이터와 알고리즘을 최적화 함으로써 정확도를 높일 수 있다.
- CNN, LSTM, DNN 등의 알고리즘을 복합적으로 활용하며 모델을 개선시켜 예측 의 정확도를 높일 수 있다. 데이터 전처리, Early stopping, Model checkpoint 등 의 기법을 활용해 과적합을 피하고 가장 좋은 효과를 내는 모델을 얻을 수 있다.
- 단순하면서 깔끔한 UI의 PyQT 툴을 이용하여 프로그램을 만들고 필요한 정보만을 보여줌으로써 사용자의 접근성을 높여준다
II. 작품 내용
1. 작품 구성도
1) 서비스 구성도
2) 기능 흐름도
2. 작품 기능
1) 전체 기능 목록
구분
기능
설명
현재진척도(%)
S/W
데이터 수집 기능
대신증권 api(CybosPlus)를 이용해 KOSPI, KOSDAQ 전 종목의 주가 데이터를 수집한다.
100%
실시간 주가 정보 조회
실시간 주식 데이터를 가져와서 시시각각 동향을 출력하여 사용자에게 제공한다.
100%
항목별 상위 10위 제공
시가총액, 오늘의 유망주(거래량, PER 기준), 영업이익률, 환산주가, 외국인 한도 소진율에 대한 상위 10위 종목들을 한눈에 볼 수 있도록 한다.
100%
주식 가격 예측 및 투자정보 제공
종목명/종목코드를 사용자에게 입력받은 후 해당 종목의 분류를 확인하여, 각 군집에 해당하는 모델에 input해 주가를 예측한다. 해당 종목의 주가 그래프 및 세부 투자정보를 추가 제공한다. - 완성 가능 시점 : 10월 30일 예상
40%
데이터 업데이트 및 모델 개선/평가
수집한 데이터 및 예측한 데이터를 저장해 모델의 정확도를 평가하고, 모델을 개선한다. 완성 가능 시점 : 10월 10일 예상
40%
2) S/W 주요 기능
기능
설명
작품실물사진
주요 항목에 대한 투자정보 제공
- 항목별 상위 10위의 종목을 제시하여 희망하는 항목에 대한 직관적인 지표를 제공함.
거레량, PER 지표를 활용 분석해 ‘오늘의 유망주’를 제공하는 등 투자 지표를 활용하여 제공함.
주가 예측 및 세부 투자정보 제공
- DNN, CNN, LSTM 등 다양한 알고리즘을 이용해 주가를 예측하고, 각 알고리즘의 정확도를 비교하여 가장 적합한 알고리즘을 채택함.
- 예측된 주식 가격을 출력하고, 해당 종목의 추가적인 투자정보와 그래프를 제공하여 사용자의 의사결정을 도움.
3. 주요 적용 기술
- 과거 내부 변수 데이터 수집 : 대신증권 Cybosplus API를 이용하여 모든 종목의 과거 10년 데이터 수집(시가, 고가, 저가, 종가, 거래량, 시가총액, 외국인보유비율, 기관거래량)
- 과거 외적 변수 데이터 수집 : Investing.com과 대신증권 API를 이용하여 모든 종목의 과거 외적 변수 10년 데이터 수집(코스피지수, 코스닥지수, MSCI, 다우존스지수, 나스닥, 항셍지수, 금리)
- 상관계수 (Correlation coefficient) 분석 : 수집한 주가 데이터와 외적변수 데이터를 바탕으로 ‘종가’에 대한 각 변수 데이터의 상관관계 분석 (pearson 상관계수 분석, kendall 상관계수 분석, spearman 상관계수 분석을 모두 진행하여 비교 분석)
- 군집(Clustering) 분석 : KMeans clustering을 이용하여 영향을 끼치는 상관계수 별 군집화 (해당 종목에 영향을 끼치는 상관계수 분류), KMeans clustering 및 시계열 군집 분석을 이용하여 상관계수 수치 동향 군집화 (군집 결과에 따라 각기 다른 주가 예측모델 도입) scikit learn과 tslearn을 사용하여 KMeans clustering을 진행한다.
- 주가 예측 모델 {
∘데이터 노이즈 제거 : 전처리된 데이터를 Christian-Fitzgerald Band Pass Filter (이하 cf 필터를 이용하여 노이즈를 제거한 후, 주가 데이터를 3차원 shape으로 변환하여 CNN 모델에 입력하여 노이즈를 재차 제거
∘주가 예측 모델 : 양방향 LSTM 모델, GRU 모델을 이용하여 앞서 노이즈를 제거한 과거 주가데이터와 상관관계가 높은 외적변수 데이터를 함께 학습시킨다. (학습 과정에서의 과적합을 피하기 위해 dropout과 dense를 이용한다.)이때 파라미터는 앞서 분류한 각 군집에 대해 최적화된 파라미터를 사용한다.
∘모든 예측 모델은 tensorflow와 scikit-learn의 모듈을 이용한다. }
4. 작품 개발 환경
구분
상세내용
S/W 개발환경
OS
Windows
개발환경(IDE)
Anaconda Sypder5 및 Pycharm
개발도구
python 3.9.6, QT designer
개발언어
Python
기타사항
open API를 통한 데이터 수집 (python 3.7 32bits), 데이터 전처리 및 예측모델 개발 (python 3.8 64bits)
프로젝트 관리환경
형상관리
GitLab
의사소통관리
GitLab, 카카오톡, Google meeting, 오프라인 미팅
기타사항
코로나 19에 따라 오프라인 미팅이 불가할때는 Google meet로 온라인 미팅 진행
5. 기타 사항 [본문에서 표현되지 못한 작품의 가치(Value)] 및 제작 노력
- 상관계수분석을 통해 각 종목에 과거 주가 데이터의 동향과 상관관계가 짙은 내적, 외적 변수를 파악하여 학습시킬 데이터셋을 각 종목마다 다르게 설정하고, 상관관계 동향에 따른 군집분석을 통해 다른 예측 알고리즘 모델로 해당 데이터를 학습시킴으로써 각 종목에 최적화된 예측을 하도록 한다.
- 상관계수 분석과 군집 분석은 최적화된 예측을 할 수 있도록 할 뿐만 아니라, 주가 동향이 비슷한 종목을 구분하고 그 상관관계를 알아볼 수 있다는 점에서 가치를 지니고 있다.
- 사용자의 매매전략에 도움을 주기 위해 주가 예측값을 비롯하여 대박주, 환산주가, 시가총액 등 여러 항목에 대한 상위 기업을 제공하고 검색한 기업에 대한 추가 투자정보를 제공한다. 이를 통해 사용자는 편리하게 다양한 정보를 접하여 매매전략을 세울 수 있게 된다.
III. 프로젝트 수행 내용
1. 프로젝트 추진 과정에서의 문제점 및 해결방안
1) 프로젝트 관리 측면
- 데이터베이스 관리 : 주식 데이터 용량의 문제로 데이터베이스 공유 및 공동 관리에 문제가 있었다. 이를 해결하기 위해 gitlab을 통해 코드를 공유하고 온라인 피드백을 통해 각자의 테스트 데이터베이스를 다듬을 수 있었다.
- 오프라인 미팅 제한 : 코로나19 상황으로 오프라인 미팅에 제약이 있었다. 카카오톡 채팅방을 통한 활발한 소통과 매주 온라인 화상 회의를 진행하여 진행상황을 공유하여 오프라인 미팅의 한계점을 극복하였다.
2) 작품 개발 측면
- 분석 모델의 한계 : 약 3000개의 종목에 대해 같은 분석 및 주가 예측 모델을 사용하니 training set과 test set의 설정에 따라 예측결과가 상이하게 도출되었다. 이를 해결하기 위해 training attribute 간의 상관계수를 분석하고 이를 토대로 군집화하여 군집에 따라 각기 다른 분석 모델을 사용하여 예측의 정확성을 높혔다.
- 다차원 데이터의 군집화 : 일반적인 군집분석의 방법인 KMeans clustering을 사용하여 데이터를 군집화하니 다차원 데이터의 군집화가 잘 이루어지지 않았다. 이를 해결하기 위해 시계열 군집화를 사용하여 다차원 데이터를 그래프화 시켜 군집화를 진행하였다.
- 과거 데이터 노이즈 문제 : 과거 10년의 종가 데이터를 학습시키는 과정에서 노이즈로 인한 후행성 문제가 발생하여 예측의 정확도가 떨어지는 결과를 가져오게 되었다. 이를 해결하기 위해 데이터 전처리 과정에서 CF filter를 사용하여 노이즈를 제거하였다.
- 수집 데이터 한계 : Dashin Cybosplus Open API를 이용하여 과거 주가데이터의 방대한 양을 수집하는 것에는 request의 한계가 있었다. 일반적인 종목의 주식 변동 주기를 기준으로 과거 10년의 데이터를 가져오도록 하였다.
2. 프로젝트를 통해 배우거나 느낀 점
- 방대한 양의 데이터를 수집 및 관리하고 전처리하는 과정에서 빅데이터를 효율적으로 다루는 방법을 터득할 수 있었다.
- 데이터간의 상관계수를 분석하고 군집화시켜 분석하는 과정에서 다양한 데이터 분석기법을 배울 수 있었으며 코드를 정리하는 과정에서 효율적인 알고리즘을 생각해볼 수 있었다.
- 편리한 프로그램 개발을 위해 사용자의 니즈를 생각해보고 사용자의 입장에서 서비스 시나리오를 기획해보며 좋은 소프트웨어 서비스에 대해 생각하는 계기가 되었다.
- 효율적인 분석모델을 설정하고 수립하는 과정에서 머신러닝 하이퍼파라미터 튜닝 과정을 비롯한 머신러닝의 여러 알고리즘에 대해 배울 수 있었으며 예측 정확도를 높힐 수 있는 방법을 고심해볼 수 있었다.
IV. 작품의 기대효과 및 활용분야
1. 작품의 기대효과
- 각 종목의 투자정보와 관련 뉴스 그리고 여러 지표를 기준으로 하여 상위 종목 정보를 제공하여 사용자가 매매전략을 세울 수 있도록 하는 기존 서비스와는 달리 사용자가 가장 집중적으로 보는 상위 기업 지표, 각 종목의 투자정보와 더불어 주가예측 서비스를 도입하여 매매전략 수립에 여러 시각의 도움을 줄 수 있다.
종목에 따라 해당 종목에 보다 효율적인 예측모델을 사용하여 타 주가 예측 프로그램보다 더 높은 예측 정확성을 기대할 수 있다.
2. 작품의 활용분야
- 주식 매매 서비스 : 객관적 지표 외에 사용자가 선택적으로 열람할 수 있는 추가적인 정보로 주가 예측 결과를 보여줄 수 있다. 이를 통해 주식 매매에 어려움을 느끼는 사람들의 매매전략 수립에 도움을 줄 수 있으며 해당 주식 매매 서비스 이용률을 증대시킬 수 있다.