이번 강연은 헬스케어 분야의 최신 AI 애플리케이션 및 프레임워크에 대한 강연(= 최신 NVIDIA 애플리케이션 소개), 연구 발표, 데모 등 다양한 세션으로 구성되어 있습니다. 파트1은 헬스케어 및 생명과학 분야의 AI, 파트 2는 딥러닝으로의 의료 연구 가속화, 파트 3은 바이오 및 임상분야의 AI 를 다룹니다. 상세 정보는 다음과 같습니다.
파트 1: 헬스케어 및 생명과학 분야의 AI
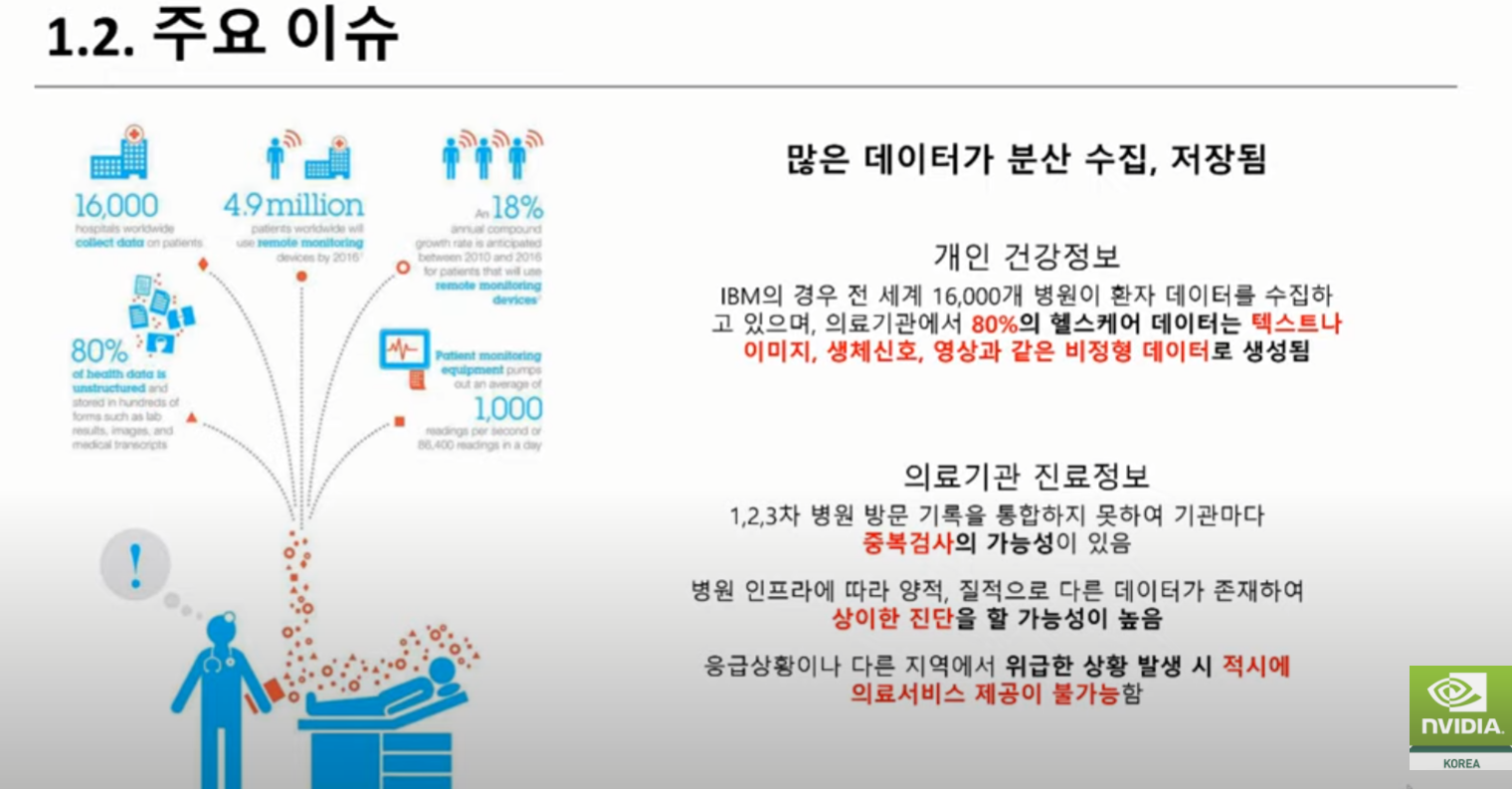
세션 1(AI와 생명과학의 융합):NVIDIA의 글로벌 헬스케어 리더들과 함께 NVIDIA 최신 기술과 생태계의 혁신, 향후 의료 서비스의 미래에 대해 알아봅니다.
세션 2(딥 러닝과 영상 의학):딥 러닝의 핵심, 생명 과학 분야의 획기적인 애플리케이션과 더불어 NVIDIA 컴퓨팅 플랫폼이 고성능 딥 러닝 시스템의 개발을 지원하는 방법을 소개합니다.
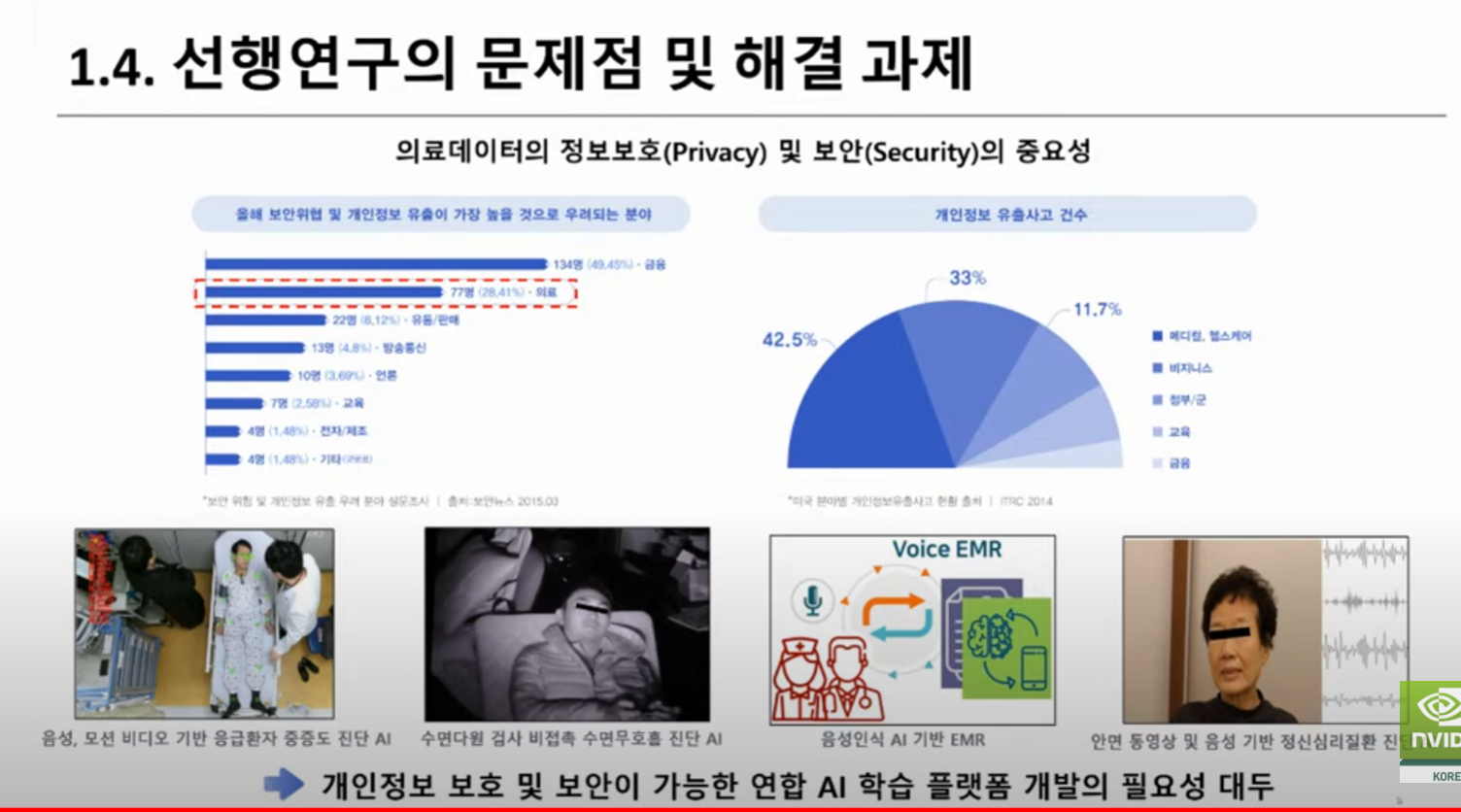
세션 3(연구개발 혁신을 위한 오픈소스 기반 구축하기):의료 이미징을 위한 개방적 혁신을 이끄는 ‘프로젝트 MONAI’와 연합학습 플랫폼인 NVIDIA FLARE가 의료 분야에서 고립된 데이터 문제를 극복하고 협업, 개인 정보 보호 AI 모델을 구축하는 데 어떻게 중요한 역할을 하는지 공유합니다.
세션 4(SNUH 연구발표 – 임상의가 바라보는 AI):실제 연구 사례와 함께 임상적으로 새로운 정보를 제공할 수 있는 AI 모델에 대해 논의합니다.
파트 2: 딥 러닝으로의 의료 연구 가속화
세션 1(HCLS 워크로드를 위한 가속화 컴퓨팅(GPU 컴퓨팅 플랫폼)):참석자들이 의료 분야의 저전력 임베디드 기기부터 데이터센터에 이르기까지 실제 활용 사례를 공유하면서 다양한 문제를 해결하기 위한 올바른 솔루션을 올바른 이해를 돕습니다.
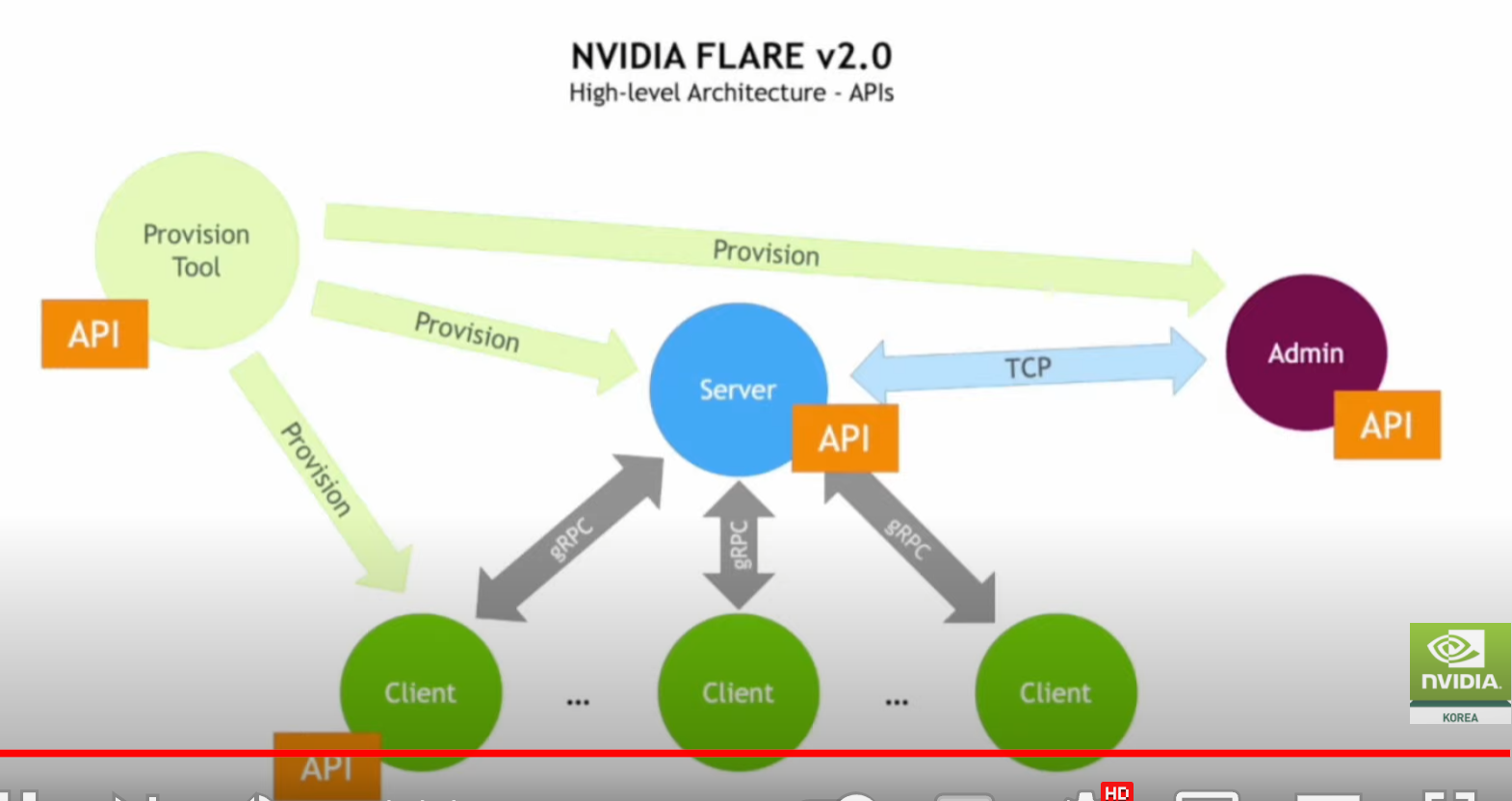
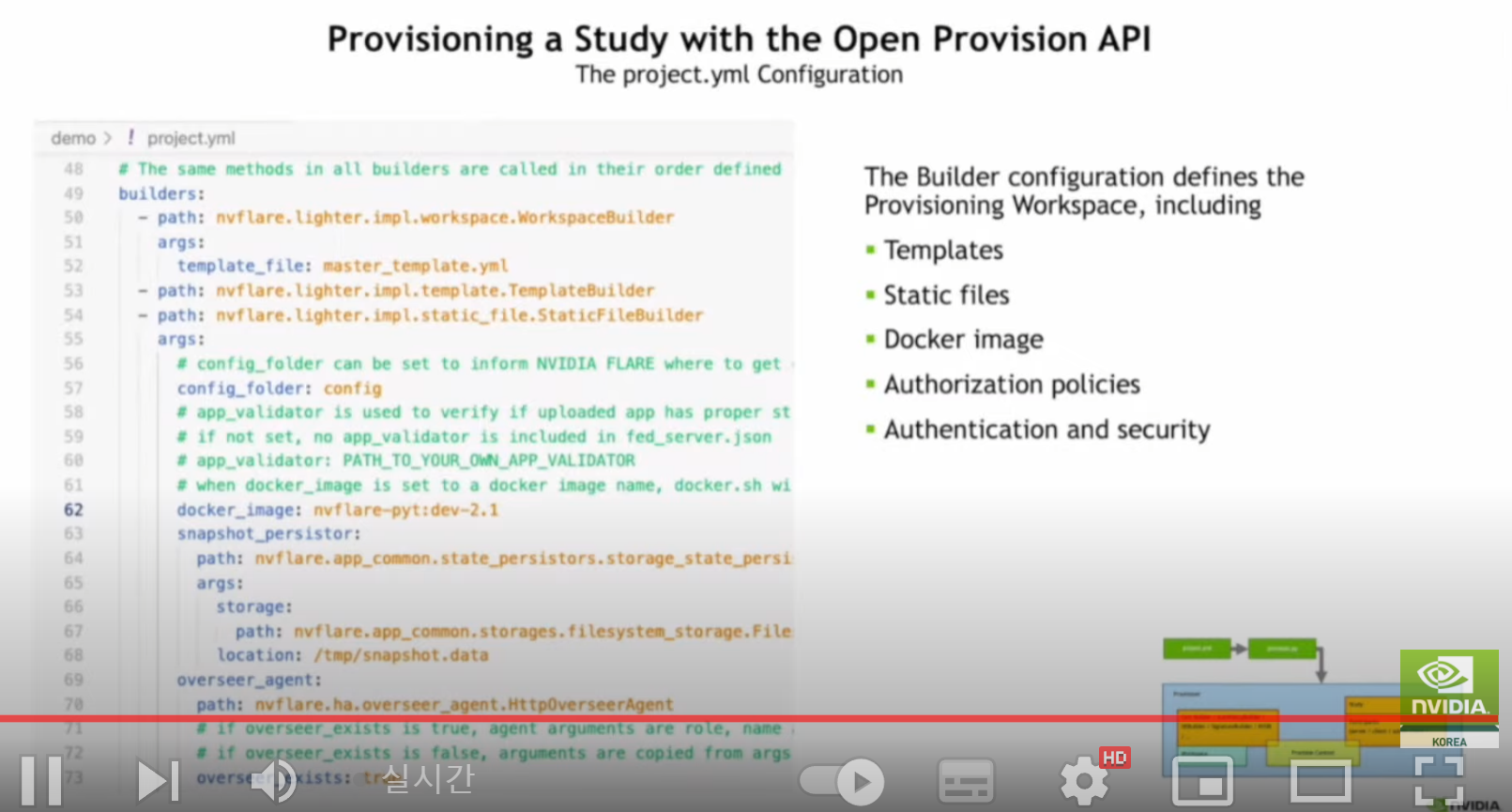
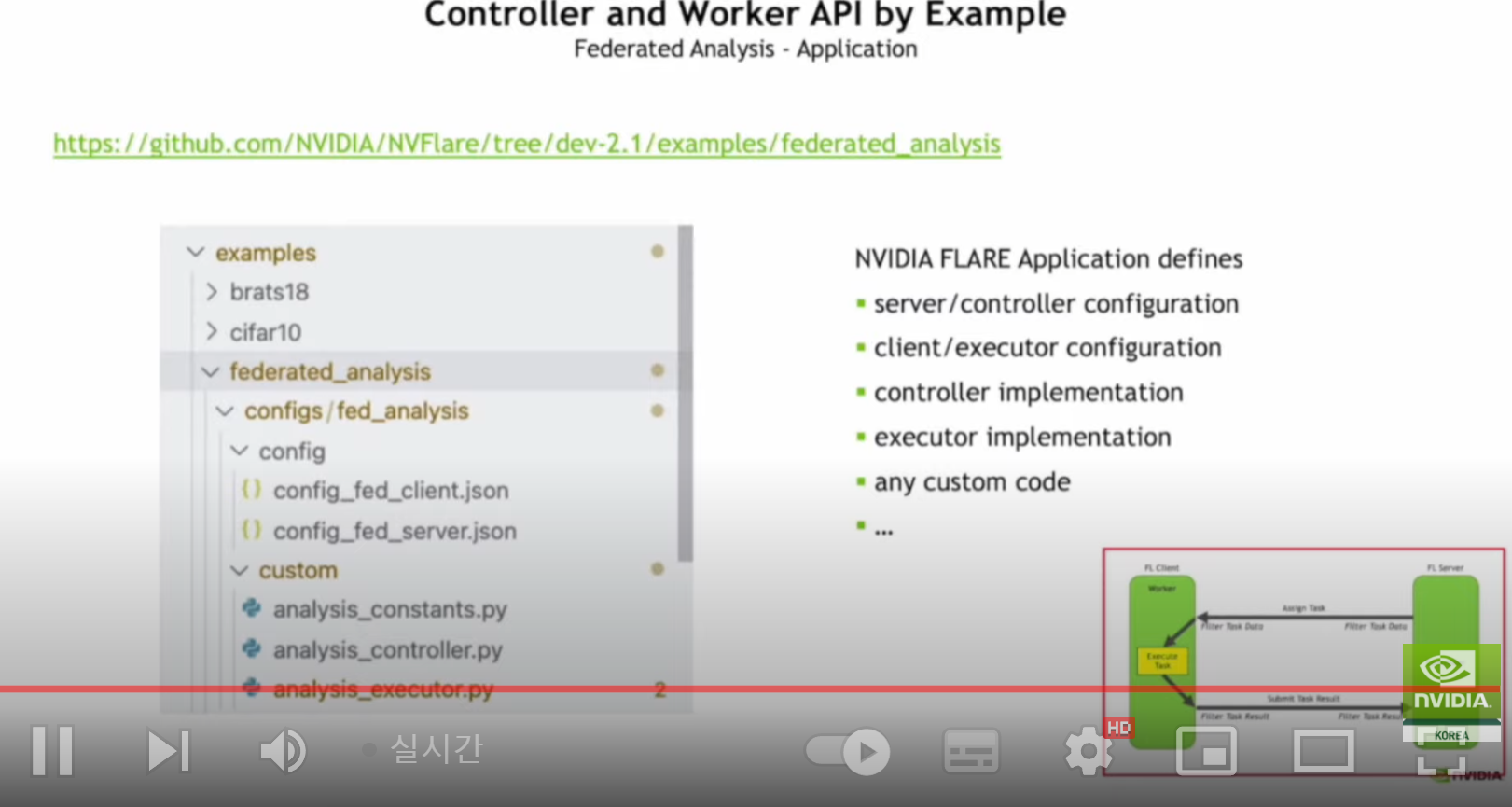
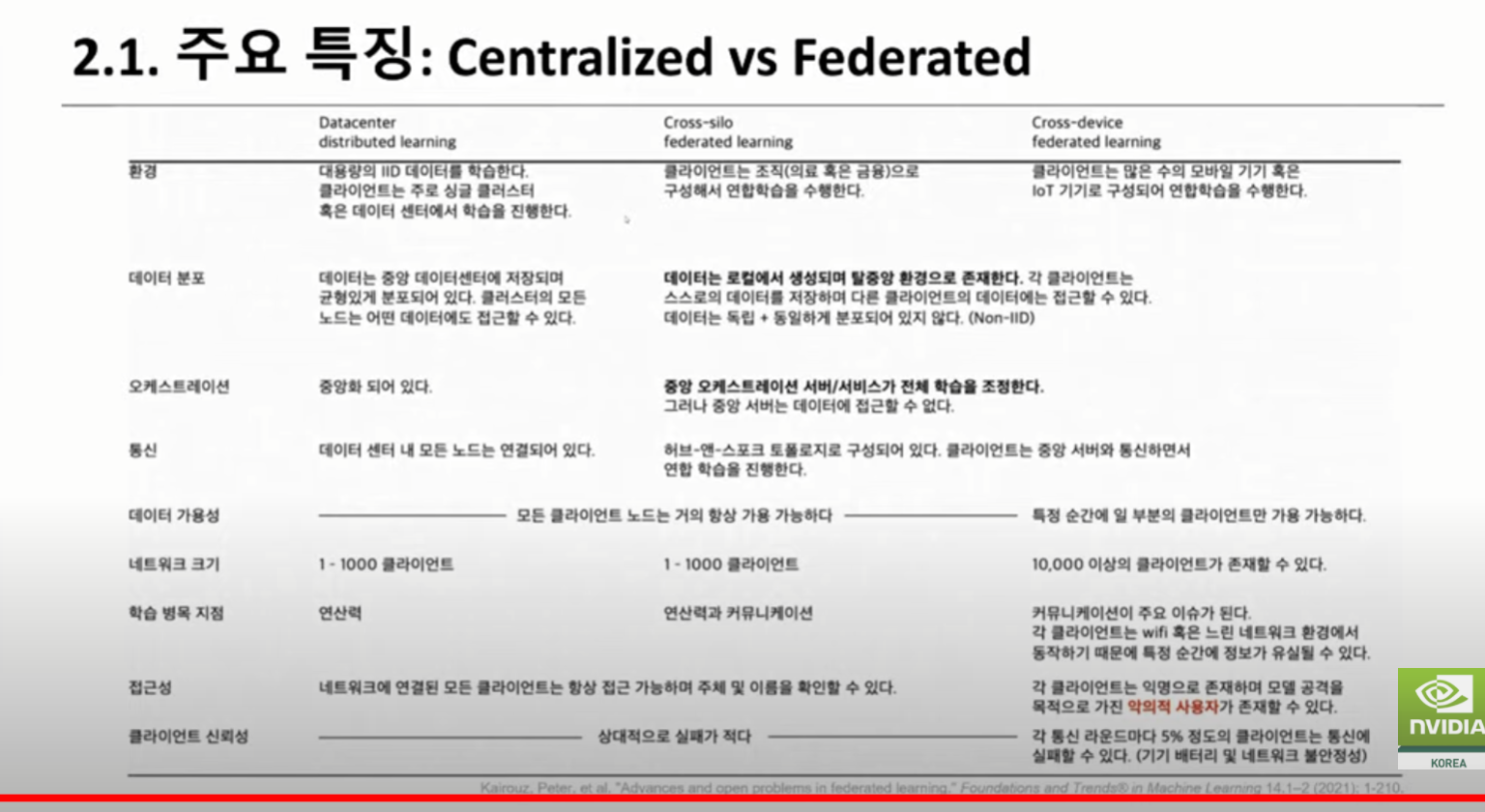
세션 2(연합 학습을 통한 의료 AI 및 연구 혁신):안전한 분산형 멀티 파티 협업을 지원하는 오픈 소스 플랫폼인 NVIDIA FLARE를 핸즈온 레벨에서 소개합니다. 연합 애플리케이션을 신속하게 개발할 수 있는 주요 기능과 워크플로우와 더불어 플랫폼의 실제 적용 분야에 대해 논의할 예정입니다.
세션 3(SNUH 연구발표 #2 – 연합학습 관련 연구 사례):실제 의료 환경에서 개인 정보 보호를 위한 의료 데이터 연합 학습 연구 발표를 진행합니다.
파트 3: 바이오 및 임상 분야의 AI
세션 1(생명과학을 위한 인공지능: 단백질 구조 예측의 미래):인간의 언어를 이해하기 위해 개발된 자기 지도방식의 자연어 처리 모델은 최근 단백질과 같은 생체 분자의 구조와 기능을 이해하고 예측하는 데 도움이 되고 있죠. 본 세션은 이와 관련해 최근 몇 가지 업데이트와 모델 아키텍처를 리뷰하고 생명과학 산업 발전에 필요한 툴, 기술 및 인프라를 살펴봅니다.
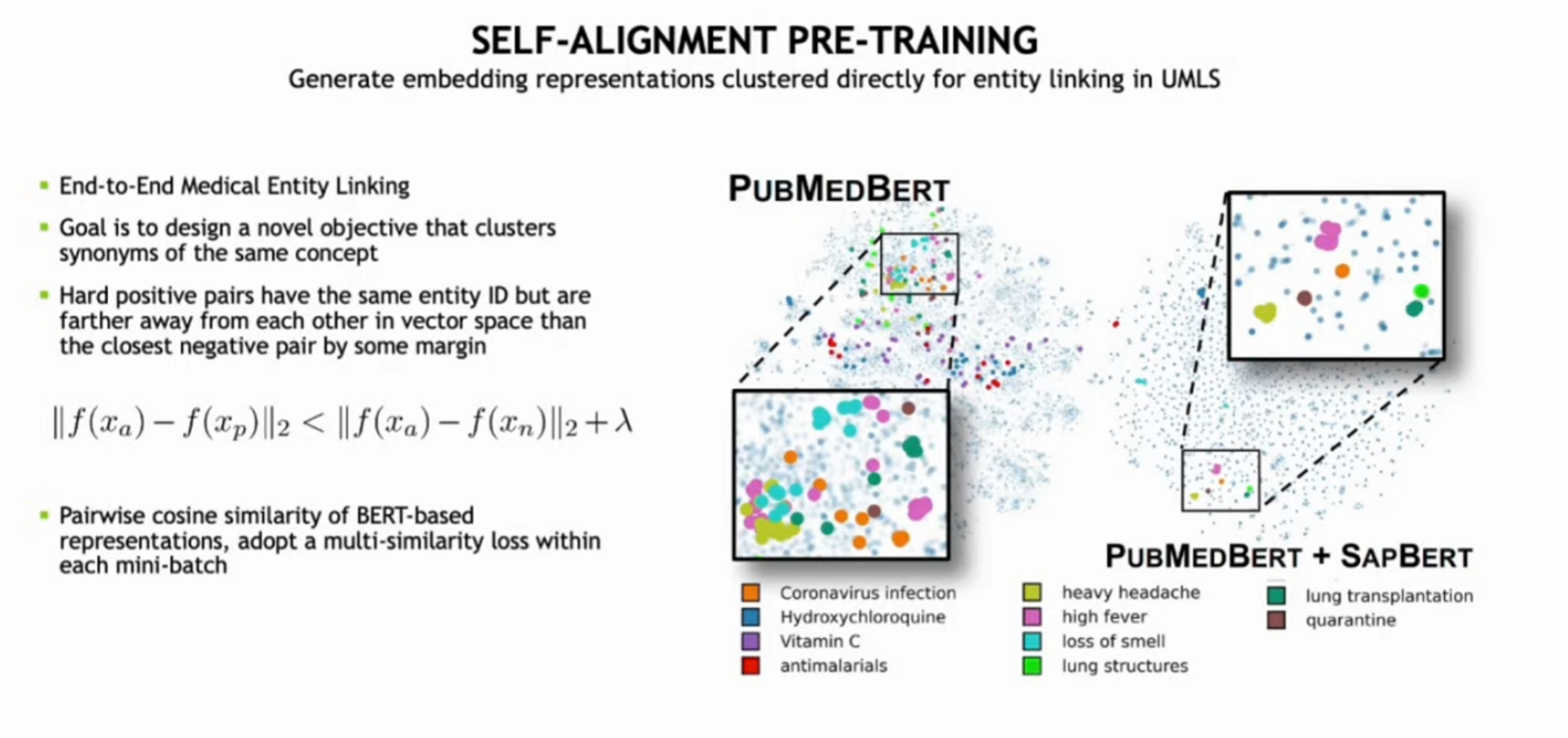
세션 2(바이오메디컬 및 임상 분야의 지식 추출 및 검색):NVIDIA가 지원한 고유한 임상 음성 및 텍스트를 위한 도메인별 트랜스포머 NLP 모델 아키텍처 프로젝트를 공유하고, 지식 추출 파이프라인을 통해 약물 대상 식별 및 우선순위 지정, 임상 시험의 구조화, 의료 코딩 및 엔터프라이즈 서치와 같은 다양한 사용 사례를 어떻게 지원하는지 보여줍니다.
세션 3(SNUH 연구발표 #3 – Bio 관련 ML/DL 연구 사례):정상인과 코로나 확진자들의 생명자원을 분양 받아 생성한 7개 종류의 멀티오믹스 데이터(scRNA-seq(BCR/TCR), Cytokine Profiling, Bulk TCR/BCR-seq, SNP array, WGS, HLA-typing, COVID-seq)를 통합 분석하고 정상인, 경증 및 중증환자 분류모델을 개발하고자 합니다. 코로나19 세포 반응(COVID-19 cellular response) 네트워크를 통해 중증도 예측 그래프 신경망(GNN) 모델을 구축하고, GNN 결과에 대해 설명가능한 인공지능(explainable artificial intelligence, XAI)을 활용하여 바이오마커 후보를 발굴하고 생물학적 의미를 도출하고자 합니다.
해당 강연의 모든 세션이 제가 관심있는 부분이어서 강연을 듣게 되었습니다.
강연 신청을 조금 늦게해서 별도의 참여 링크 없이 NVIDIA korea 유투브로 들을 수 있었고, 오전 10시부터 오후 5시까지 다양한 주제로 강연이 진행되었습니다.
강연이 자막 없이 영어로 스피디하게 진행되어서 내용을 완벽히 이해하기 힘들었기에, 최대한 내용을 기록해두고 나중에도 차근차근 다시 읽어볼 목적으로 글을 남깁니다.
각 강연의 내용(PPT)과 함께 해당 세션의 사전 질문 내용과 답변을 기록해두었습니다. 모든 내용이 기록되어있는것은 아니며, 일단은 PPT만 기록해두었는데 추후에 시간이 되면 간략한 보충글도 적어볼 예정입니다.
개회사
Part 1. 헬스케어 및 생명과학 분야의 AI
1-1. AI 와 생명과학의 융합/ 르네 야오
[사전질문 및 답변]
(사전질문 1) Cloud 방식으로 활용 가능한 서비스가 있는가요?
(사전질문1 답변) 예, Clara, Monai, Rapids와 같이 클라우드에서 사용할 수 있는 SDK/서비스가 많이 있습니다. (Colleen)
(사전질문 2) 인공지능 관점에서 NVIDIA가 가장 유망하다고 보는 의료 관련분야는 무엇이고 관련해 개발 중인 유망 기술들은 어떤게 있을까요?
(사전질문2 답변) Radiologists의 행동으로서 의료 이미지 분류, 세분화 및 감지 기능을 제공합니다.
(사전질문3) 임상에는 아직 AI가 도입되지 못하는 것으로 알고 있습니다만, 향후에는 AI가 직접 임상에도 사용이 되려면 어떤 부분이 중요할까요? 그리고 의료에서의 AI 정확도는 꽤나 높지만 적용까지는 더디게 진행되고 있다고 생각하는데 어떤 부분이 가장 해결되어야 할 부분이라고 생각되시는지 궁금합니다.
(사전질문 4 답변) 기존의 기계 학습 방법 외에도, NLP 및 VAE 모델과 같은 많은 DL 모델이 신약 개발 과정에 사용되었습니다 (Colleen)
(사전질문5) NVIDIA가 보유하고 있는 의료관련 플랫폼의 활용 사례가 궁금합니다.
(사전질문5 답변) NVIDIA Clara는 AI 기반 이미징, 유전체학, 스마트 센서 개발 및 배치를 위한 의료 애플리케이션 프레임워크입니다. 여기에는 개발자, 데이터 과학자 및 연구자를 위한 풀 스택 GPU 가속 라이브러리, SDK 및 참조 애플리케이션이 포함되어 있으며, 실시간, 보안 및 확장 가능한 솔루션을 만들 수 있습니다.
(사전질문 6) 저희는 반려동물의 건강과 관련한 AI Service를 준비하고 있습니다. 인간보다 신체의 크기가 작은 반려동물의 경우에도 NVIDIA의 기술을 어떻게 활용할 수 있는 지 알고 싶습니다.
(사전질문6 답변) NVIDIA의 기술은 사람과 애완동물 모두에게 사용될 수 있습니다. 이 두 가지 차이는 데이터 정의와 작업 정의이지만 사용되는 기술은 동일할 수 있습니다.
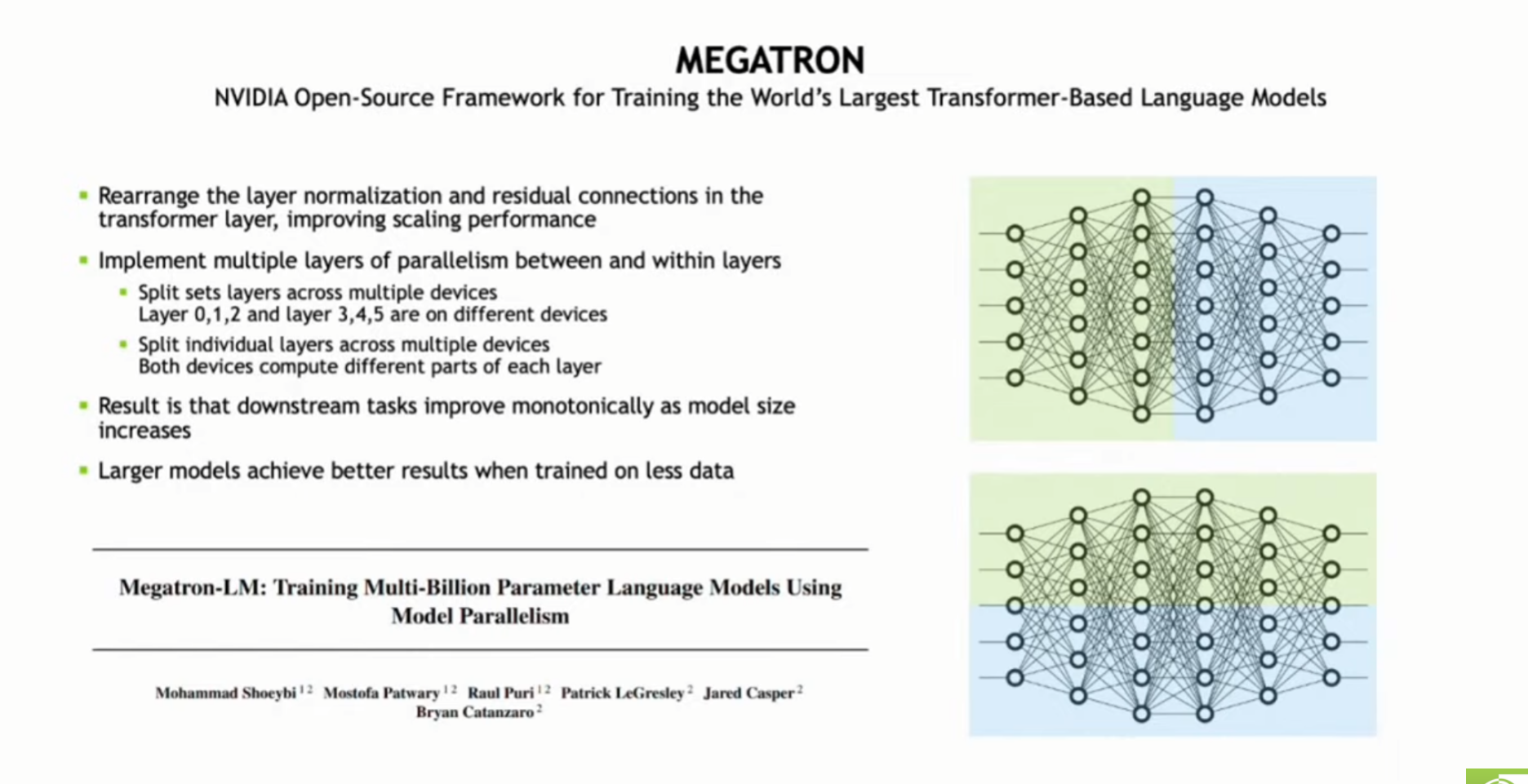
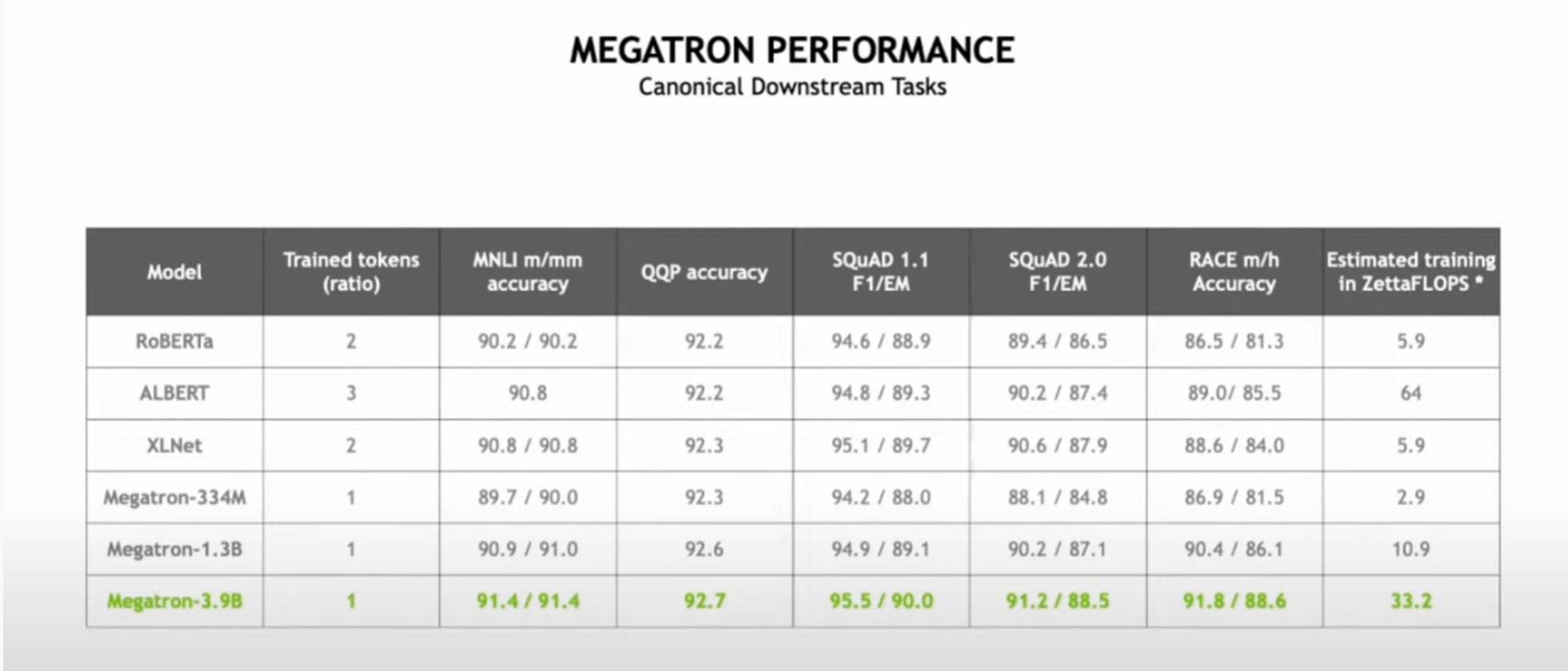
(사전질문7) 유전자 염기서열을 분석하고 특정 약물과의 투약에 대한 상관관계를 알아내고자 할 때, Transformer를 사용할 수 있습니다. 이 때, Megatron-LM과 같이 거대 모델과 이를 위한 학습 방법을 도입하는 것이 항상 유효한지 궁금합니다.
(사전질문7 답변) 데이터 집합 규모에 따라 다를 수 있습니다. 대규모 데이터가 있는 경우 거대 모델이 정확도에 더 많은 이점을 가져다 줍니다.
1-2. 딥 러닝과 영상 의학/ 싯다르트 코트발
DNN(feed-forward), CNN, RNN, Transformers. Graph Neural Networks, GAN
[사전질문 및 답변]
(사전질문1) 대부분의 인공지능은 설명할 수 없습니다. 의학 영상에서 가장 중요한 것을 설명할 수 있는 가능성입니다. 인공지능의 신뢰성을 어떻게 극복해야 하는지 조언해주시면 감사하겠습니다.
(사전질문1 답변) AI 모델의 설명에 대한 연구가 있는데, 이것은 사람들이 모델이 정말로 그들이 기대했던 대로 학습하는지 이해할 수 있도록 도와줍니다. 또한 트레이닝에 다양한 데이터를 사용하면 모델의 신뢰성이 향상될 수 있습니다.
사전질문2) 디지털 X선, CT 및 MR과 비교했을 때, 높은 실시간/낮은 지연 요구 사항이 있는 초음파 영상은 딥 러닝의 적용이 제한적일 수 있습니다. 특히 고성능 HW를 장착할 수 없는 핸드헬드 초음파 영상 장비의 적용 가능성은 얼마나 됩니까?
(사전질문2 답변) NVIDIA에는 휴대용 기기에 사용할 수 있는 HW 플랫폼이 내장되어 있습니다. 또한 TRT 및 Triton과 같은 몇 가지 SW 최적화 도구를 사용하여 고성능 없이 DL 애플리케이션을 HW에 적합하게 만들 수 있습니다.
(사전질문3) 딥 러닝의 문제는 계산하는데 오랜 시간이 걸린다는 것입니다. 우리는 현재 NVIDIA의 고급 GPU를 사용하는 것을 선호하지만, 앞으로는 더 빠른 양자 컴퓨터를 보게 될 것입니다. NVIDIA의 양자 컴퓨팅 계획은 무엇입니까?
(사전질문3 답변) NVIDIA는 양자 컴퓨팅에 관한 몇 가지 작업을 가지고 있습니다. 우리는 방금 GPU에서 양자 시뮬레이션을 하는 데 사용할 수 있는 cuQuantum이라는 SDK를 발표했습니다.
1-3. 연구개발혁신을 위한 오픈소스 개발 / 프레나 도그발
[사전질문 및 답변]
(사전질문 1) 한국에서 FLARE 적용사례가 있는지 궁금하고, 의료 분야에서 federated learning 적용시 기술과 제도적인 관점에서 이슈가 되는 사항들이 어떤게 있는지 궁금합니다
뇌영상 -> 정성적이 아닌, 정량적인 objective signature score -> 다양한 기능 수행 가능
- rethink Data features.
Image is not image.
의료 영상들은 모두 connection이 되어 있다.
한 사람에게도 다양한 data 존재
레이블 작업 없이 만들기
서로다른종류 multimodal 합쳐서, 유용한 insight를 찾음으로써 유용성..
사람이 레이블링 X 다양한 데이터를 합쳐서 레이블링해서 self-supervise learning. (단순 supervise learning X)
[사전질문 및 답변]
(사전질문 1) 희귀병 등에 대한 원인 추적 등은 위험이 따를 수 있고 데이터가 부족할 수 있습니다. 또, 바이러스 변이와 백신 연구는 곧 특허전쟁부터 무기의 개발로까지 변질될 수 있습니다. 새로운 정보를 얻어낼 때, 정보에 대한 증명과 연구과정에서 부작용을 최소화할 방안은 무엇이 있나요? 어떤 방식으로 학습시키고 어떤 정보를 추출할 지 궁금합니다.
(사전질문 1 답변) Rare disorder 등에 대한 AI 는 여러모로 고민이 될 수 밖에 없는 부분입니다. 대규모 데이터기반으로 만들어지는 현 시점의 AI모델을 고려할 때, Rare disorder를 model이 알아내는 것도 어려운 문제일 뿐더러,
이를 위한 최선의 management를 위한 여러 형태의 AI , Data-driven method를 만들기에 어려움이 있습니다. 우선 Rare disorder에 대한 identification 부분은 강의에서 다루겠지만,
단순한 supervised learning이 아닌 data에 집중하는 unsupervised learning과 data distribution에서 접근함으로서 해결할 부분이 있습니다.
Rare disorder를 치료하고 타겟찾는 등의 일은 적은 수의 data를 극복할 수 있는 여러 technical한 부분이 적재적소에 들어가야할 듯 합니다. 예를들면 Zero-shot, few-shot learning등이겠습니다.
(사전질문 2) 딥러닝이 기존에 전공의나 임상의가 하던 일을 대신하면 사람은 어떤 일에 집중하게 되나요? 또 지금 딥러닝이 대신 해주는 분야에 대한 지식이나 인사이트는 어떻게 얻게 될까요? 요즘 혈압 측정 기기가 있어, 간호사도 수동 혈압측정기를 잘 못쓰시더라고요. 그러나 그런 기기가 없거나 딥러닝 제품을 사용하기 어려운 곳에서도 환자는 있게 마련이어서요.
(사전질문 2 답변) 딥러닝으로 일부의 일이 줄어드는 부분은 있겠으나, 현 단계에서는 많은 일을 대신해주어 업무가 완전히 재배치될 만큼의 모습은 보기 어려울 듯 합니다. 진단 support system의 일부에서 업무량이 줄어드는 정도이고,
결국은 오히려 AI가 생산하는 새로운 정보가 또다른 해석과 진료에 활용되는 방향으로 흘러가기 때문에, 사람이 처리해야하는 정보량이나 일의 양이 줄어들지는 않을 듯 합니다. 물론 먼 미래에 사람의 행동과 사고판단까지 모사하는 기술들, 즉 강인공지능이만들어진다면 모르겠습니다만, 이부분은 현재 논의할 단계는 아닌 것 같습니다.
딥러닝이 대신해주는 분야에 대해 우리가 지식을 꼭 가져야하는가로 질문이 귀결될 수 있을 듯 합니다. 우리에겐 원리가 필요하지 작동원리를 다시 설계해갈 필요는 없습니다. 기술의 발전으로 인해 과거의 행위들에 대한 숙련도가 떨어지는 현상은 자연스러울 수 있습니다. 또한, 이런 기술발전이 사회적 격차를 만들 수 있다는 것도 잘 알려져있습니다.
하지만, 이 역시도 기술이 극복할 수 있는 영역이 있습니다. 오히려 더 많은 부분에서 기술로서 극복하는 사례가 더 많습니다. 예를들어, 안저검사의 경우 미국의 rural area에서는 DL 기반의 장비가 안과전문의를 만나기 어려운 지역에서 screening역할을 할 수 있도록 만들어지고 있습니다.
(사전 질문 4) AI의 설명 가능한 정도와 임상 의사의 AI에 대한 신뢰 수준의 관계가 궁금합니다.
(사전 질문 4 답변) explainability가 의미하는 바는 매우매우 넓습니다. 짧게는 CAM 과 같이 어느 영역을 보고 판단했는지를 의미하는 것 부터, 어떻게 추론했는지를 파악하는 것 등 매우 넓은영역입니다. 임상에서 중요한 것은 그런데, '합목적성' 입니다.
예를들어, CT영상을 보고 특정항암제에 잘 들을 수 있을지 예측하는 모델을 만들었다고 할 때, 이는 explainability가 없습니다. 그런데 기존에 잘 알려진, 해당항암제의 치료반응을 결정하는 PD-L1이라는 마커가 존재하고, CT영상을 통해 이를 예측할 수 있다고 하면 중간연결고리가 생기면서 설명가능성이 발생합니다.
즉, AI가 추구하는 방향은 이러한 detail한 합리적인 추론으로 만들어갈 수 있느냐에 있습니다. 또한, 의사는 환자를 살리기위해서 어떠한 설명가능한 이유보다, 근거가 중요합니다. 즉 어떤 약제가 효과적인지를 판단할 때 물론 기전도 중요하지만, 최종적으로는 기존 약제보다 더 낫다라는 임상적 근거, 즉 임상시험에 의한 근거가 1순위 입니다.
Part 2. 딥 러닝으로의 의료 연구 가속화
2-1. HCLS 워크로드를 위한 가속화 컴퓨팅/ 콜린 컴퍼스
[사전질문 및 답변]
(사전 질문 1) 클라우드 접근 방식 인가요?
(사전 질문 1 답변) NVIDIA 헬스케어 플랫폼은 온프레미스 및 클라우드 두가지 방식으로 활용 가능합니다.
(사전 질문 2) 어느정도 규모의 컴퓨팅 시스템을 활용하시나요?
(사전 질문 2 답변) 워크로드의 크기에 따라 다릅니다.
(사전 질문 3) 가속 컴퓨팅을 효과적으로 활용하는 데 NVIDIA의 컴퓨팅 플랫폼을 적용하는 방법에 대해서 질문드립니다.
(사전 질문 3 답변) NVIDIA 컴퓨팅 플랫폼에는 세 가지 계층이 있습니다. 하드웨어, GPU에 최적화된 범용 가속 소프트웨어 및 특정 도메인용 소프트웨어가 함께 작동하여 컴퓨팅을 효과적으로 가속합니다.
(사전 질문 4) HCLS 워크로드의 속도는 어느정도이며, 구축시 소모되는 비용이나 필요 사항들은 무엇이 있을까요?
(사전 질문 4 답변) 상황에 따라 다르지만 일반적으로 HCLS 워크로드가 몇 배, 수십 배 또는 심지어 더 빠릅니다. 비용은 하드웨어 부분일 뿐이며 99%의 소프트웨어는 되어오픈 되어있으며 무료로 사용할 수 있습니다
(사전 질문 5) 가속화컴퓨팅을 위해서는 컴퓨터의 성능이 하이엔드급의 사양을 요구하게될텐데 엔비디아에선 이부분에 대해 특정 플랫폼이나 기존 그래픽이 아닌 맞는 제품을 별도로 개발하고 있나요?
(사전 질문 5 답변) 아니요. 개발자와 연구자가 작업을 가속화하기 위해 그래픽, 플랫폼, 사전 교육된 모델 및 데모 스크립트를 개발하지만 최종 제품이나 애플리케이션은 제공하지 않습니다.
사전 질문 6) 수백만 개의 분자를 처리하고 수백 가지의 잠재적인 약물을 선별하기 위해 컴퓨팅을 어떻게 가속화할 수 있습니까?
(사전 질문 6 답변) AI 및 HPC 도구를 사용하여 약물 발견을 수행할 수 있으며, NAMD, AMBER 및 AutoDock과 같은 많은 도구를 통해 GPU에서 가속할 수 있습니다.
2-2. 연합 학습을 통한 의료 AI 및 연구 혁신 / 크리스토퍼 커스텐
[사전질문 및 답변]
(사전 질문 1) 대표적인 데이터 관리 기법은 무엇인가요?
(사전 질문 1 답변) 기존 데이터 및 새로운 데이터에 대한 액세스를 단순화합니다.SPARK와 도커를 잘 활용하고 있습니다.
(기타 질문 )Flare 는 Platform independent 한가요? Nvidia machine 이 아니어도 동작 하나요? Mobile 이 client 인 경우도 고려되고 있나요? /NVIDIA의 Flare는 Flare 안에 구현되어있는 ML/DL 알고리즘 등만 사용할수있는게아니라 제가 원하는 모델들을 제한없이 이용할 수 있는 건가요?
(사전 질문 2) Federated Learning과 중앙집중형 처리의 모델 성능을 대규모 데이터에서 비교해 본 사례가 있는지, 또한 작업의 배분, Workflow Monitoring이 플랫폼 상에서 어떻게 이루어 지는지 궁금합니다.
사전 질문 2 답변) 예, FL과 데이터 중앙 집중화의 성능을 비교했습니다. 초기에는 FL이 사이트의 일부 매개 변수만 집계했기 때문에 성능이 떨어졌으나 수백 번의 에포크 후 데이터 중앙 집중화 케이스와 거의 동일한 성능을 달성했습니다. 우리는 ADMIN API를 가지고 있으며,수석 연구원이 이를 사용하여 플랫폼의 작업을 모니터링할 수 있습니다.
사전 질문 3) API 기반 연동외에 사전 개발적용된 도구나 툴킷도 제공되는지 궁금합니다.
사전 질문 4) 1) 의료 태스크는 개인정보에 민감하기에 로컬 디바이스의 데이터를 중앙으로 공유하지않는 federated learning이 적합한 어플리케이션이라는 생각이 들지만, FL을 사용함으로써 생기는 performance degradation에도 불구하고 FL을 사용해야하는 장점이 궁금합니다.2) 의료데이터는 인종마다 특징이 다른데, semantic하게 유사한 이미지 외에 시퀀스 데이터 등은 인코딩했을 때 피처 레벨에서도 인종 간 유의미한 차이가 있을 수도 있다고 생각합니다. 이 경우 FL을 사용하면 클라이언트 간의 data distribution의 차이가 커서 학습이 제대로 안 될 수 있는 문제가 생길수 있을 것 같은데 어떻게 생각하시나요?
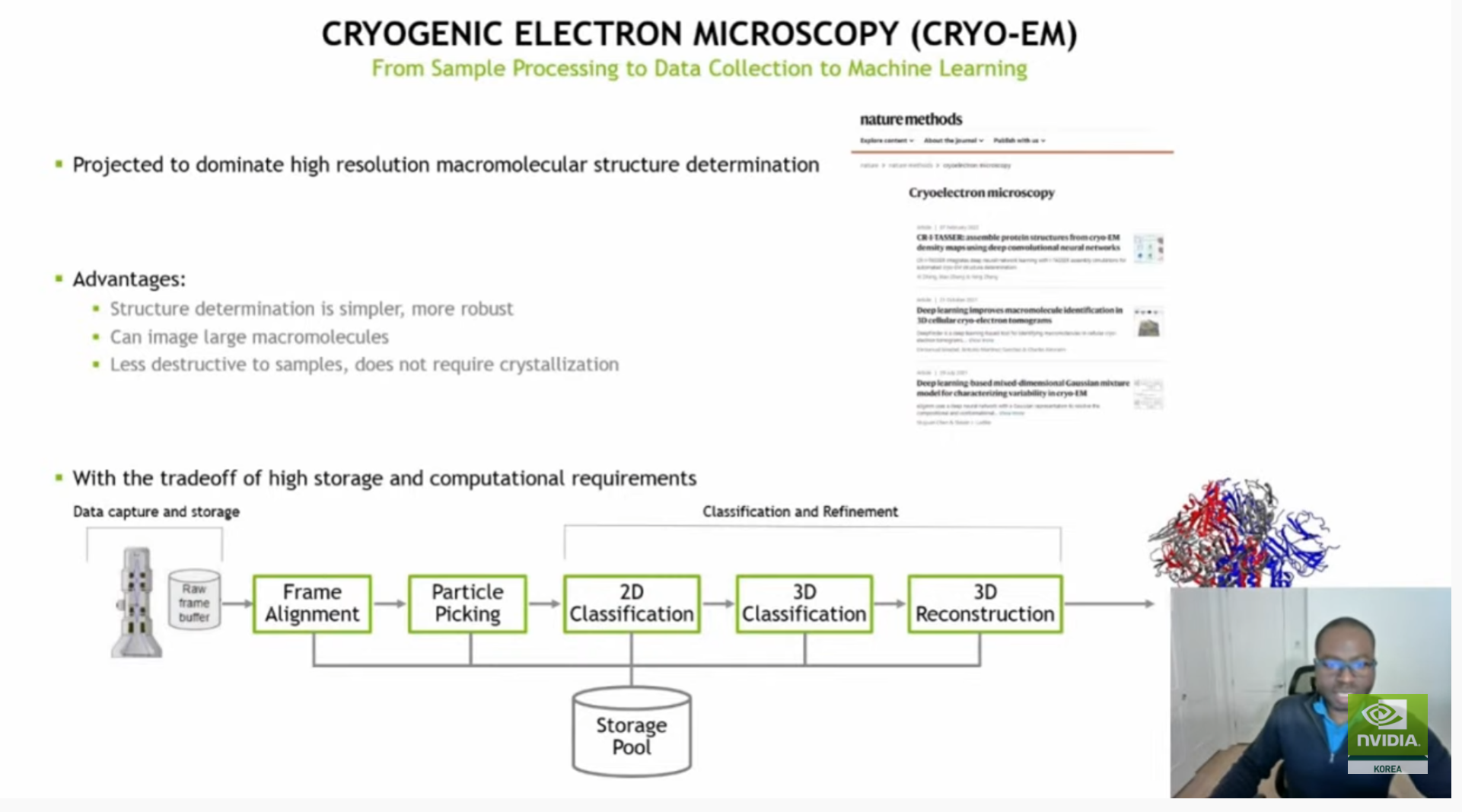
(사전 질문 1) 현재까지 crystallography를 통해 밝혀진 구조들은 생체내 존재하는 단백질중 극히 일부입니다. 대부분의 단백질은 세포막에서 발현되거나 crystalization이 힘든 단백질들이 대부분이며 이들이 질병에 굉장히 밀접한 단백질이지만, 구조를 밝히지 못하여 데이터 또한 존재하지 않습니다.
현재의 Alphafold와 같이 기존 데이터를 사용한 기계학습에서는 앞선 구조를 밝혀내지 못한 단백질의 특이적 feature들을 반영한 단백질 구조 예측 모델이 없는데, 이를 타계하기 위해서는 기존의 물리화학적 지식 및 생물학적 발생원리규명등 다양한 추가정보가 필요할 것으로 생각이 됩니다.
어떤 정보를 추가적으로 쓴다면 이러한 한계점을 넘을수 있을거 같으며, 이러한 한계점을 넘기 위한 새로운 모델 Architecture에 대한 생각이 궁금합니다.
(사전 질문 1 답변) 좋은 지적이에요. Dry lab과 Wet lab이 AI 약물 발견의 트렌드인 이유입니다. 생명공학은 DL 모델의 예측을 정확하게 검증하기 위해서는 둘 다에 의존해야 합니다.
(사전 질문 2) 자연어처리 모델은 기본적으로 방대한 언어 데이터 속의 규칙성을 파악하고, 추론하고자 하는 언어학적 시도를 전산적으로 구현한 것으로 배웠습니다. 아직 언어의 변화를 주도하는 원동력에 관해선 많은 부분이 안개 속에 있다고 언어학자들은 이야기합니다. 비록 자연어 처리 모델이 언어의 변화를 사용자에 앞서 예측할 수는 없지만,
현재 사용하는 언어의 컴퓨터적 구현을 통해 HCI적 이점이 크다고 알고 있습니다. 하지만 nvidia 단백질 구조 예측 시스템은 관련 문서상으로 보았을 때 아직 발견되지 않은 바이러스의 단백질 특성 등에 대한 예측을 목표로 하는 것으로 보입니다.
그렇기 위해선 기존의 자연어 처리 시스템보다 더 나아가, 변화의 원동력을 찾아낼 수 있는 시스템이 필요하다고 생각되는데, 아직까지는 이를 위한 이론적, 기술적 구현을 확인하지 못했습니다. 혹시 nvidia에서 위와 같은 내용에 대한 시도가 이루어지고 있는지 궁금합니다.
(사전 질문 2 답변) 질문자님께서 매우 정확히 이해하고 계십니다. 우리는 아직 이를 위해 노력하지 않고 있지만, 현재 주로 개발자와 연구자의 워크플로우를 가속화하기 위해 매우 큰 컴퓨팅 능력을 필요로 하는 최적화된 사전 교육 모델을 제공하는 SOTA 자연어 처리 모델을 학습하고 있습니다. 이론적 및 기술적 구현을 확인하는 데는 아직 시간이 필요합니다.
(사전 질문 3) 작년에 ALPHAFOLD로 상당히 깊은 인상을 받았다. 이것이 더 발전하여 물리/화학 작용으로 인한 변성까지 예측하는 것은 얼마나 시간이 걸릴 거 같은가
(사전 질문 3 답변) 알파폴드는 구글 딥마인드가 개발한 제품이라 정확한 답변을 드릴 수는 없지만 시간이 오래 걸리지는 않을 것으로 생각합니다.
(사전 질문 4) 자연어 처리 모델을 통해 크고 복잡한 단백질 구조를 이해, 예측할 수 있었던 방식이 궁금합니다 !
(사전 질문 4 답변) Openfold을 계속 활용해 주세요. 새로운 가중치로 AF2 모델을 재교육하여 보다 복잡한 구조를 예측할 수 있습니다.
(사전 질문 5) 단백질 구조를 이해하고 예측하는 데 자연어 처리 모델을 효율적으로 활용할 수 있는 방법에 대해서 문의드립니다
(사전 질문 5 답변) AlphaFold2와 RosettaFold의 다운스트림 응용에 이어 항체 설계, 표적 추출 등과 같은 많은 연구 논문들이 진행 중입니다.
(사전 질문 6) 그래프 신경망 단백질 구조 예측을 사용할 수 있는 것은 무엇일까요?
NVIDIA Korea(사전 질문 6 답변) 네, GNN은 단백질 구조 예측에 사용될 수 있습니다, 많은 논문에서 GNN이 해당 영역에서 잘 작동한다는 것을 보여주었습니다.
NVIDIA Korea(사전 질문 7) 예를 들어 AI상담센터를 운영하고자 할때 고객의 음성을 텍스트로 변환하고 고객의 요구에 맞는 답안을 도출한뒤 이를 다시 음성으로 변환하는데 있어서 가장 중요한 부분은 학습과 AI 엔진의 고도화일텐데요. NVIDIA 에서 이러한 비즈니스 모델에 적합한 솔루션을 소개해 주신다면 어떤 구성이 적절할지 문의드립니다.
(사전 질문 7 답변) 3가지 제안을 드립니다.
a. 고객이 AI에 대해 잘 알지는 못하지만 컴퓨팅 화학 분야의 적용법이 필요한 경우입니다. NVIDIA는 로코드 또는 코드가 없는 AIDD 솔루션을 사용하는 Schrodinger, AMBER, CyroSPARC와 같은 일부 ISV를 추천할 수 있습니다.
b. 고객이 HPC 및 AI에 익숙하다면 Linux 커맨드 라인을 통해 또는 DL 도커를 통해 활용할 수 있습니다. 그런 다음 고객이 NGC에서 Clara Discovery를 AF2, Rosetta, RF-design, molecularnet, openfold와 같은 인기 있는 도구와 함께 사용할 것을 권장합니다.
c. Customer가 HPC와 AI에 매우 강하다면 NVIDIA는 고객이 DL 모델을 공동으로 파인튜닝하거나 CUDA 커널을 최적화하도록 도울 수 있습니다.
(사전 질문 8) 주제가 신선합니다. 자연어 처리 모델의 어느 부분이 단백질 구조 이해/예측에 적용되었는지와 이 로직을 다른 어떤 분야에 활용가능할지 궁금합니다.
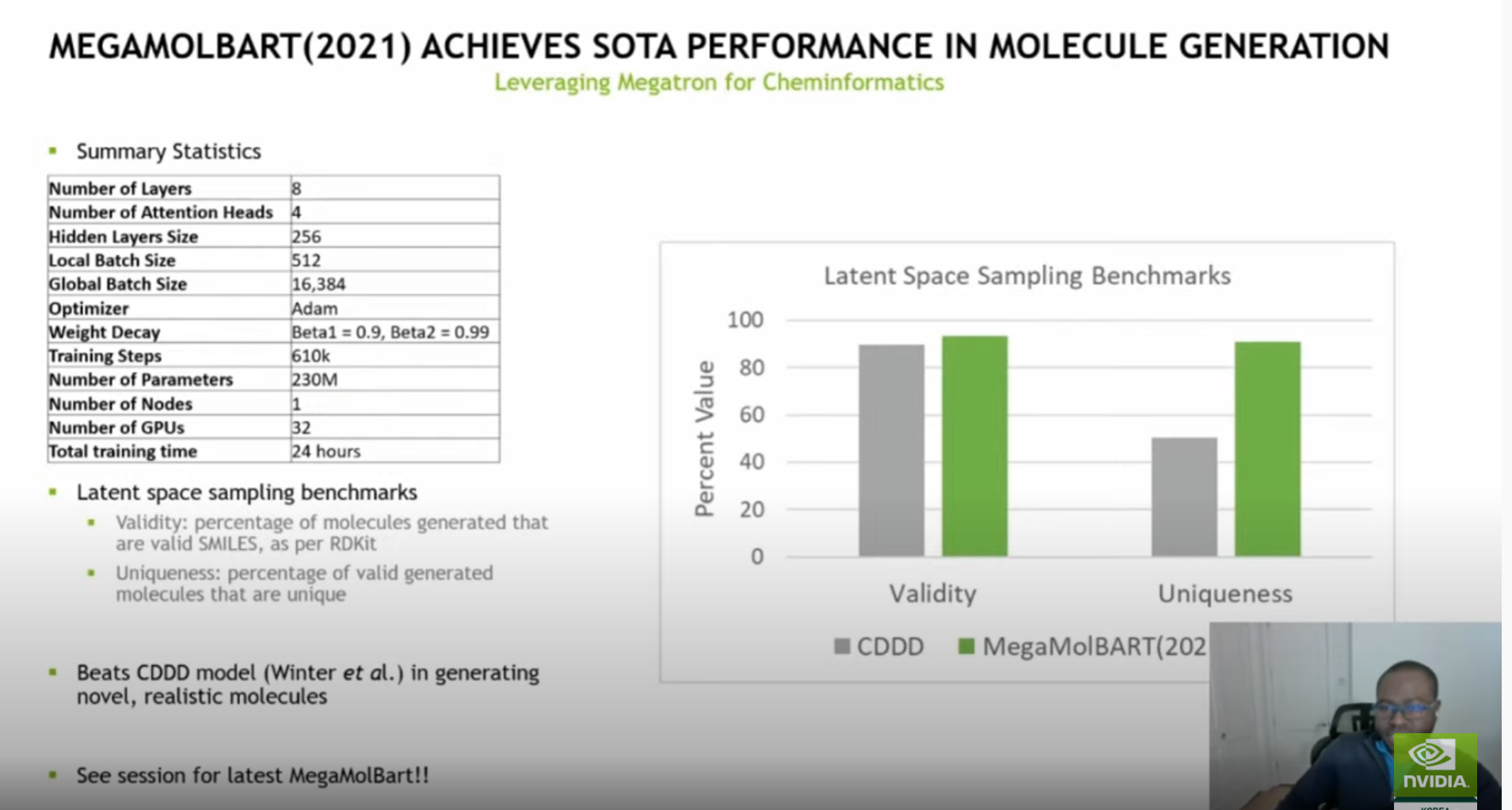
(사전 질문 8 답변) Clara Discovery부터 시작할 수 있습니다. 많은 CUDA 라이브러리는 HTS, Audodock, FEC, 분자 역학에 유용합니다. 그런 다음 트랜스포머에 크게 의존하는 알파폴드2의 논문과 코드를 주의 깊게 읽어 보십시오. 알파폴드2와 로제타폴드는 단백질 구조 예측에 가장 인기 있는 프레임워크입니다. RF-Design은 약물 발견의 Denovo 설계에서 가장 널리 활용되고 있습니다. 분자 생성 분야에서는 NVIDIA에 MegaMolBart가 있으며, moleculenet을 확인할 수도 있습니다.
3-2. 바이오메디컬 및 임상 분야의 지식 추출 및 검색/ 엔서니 코스타
-- future --
[사전질문 및 답변]
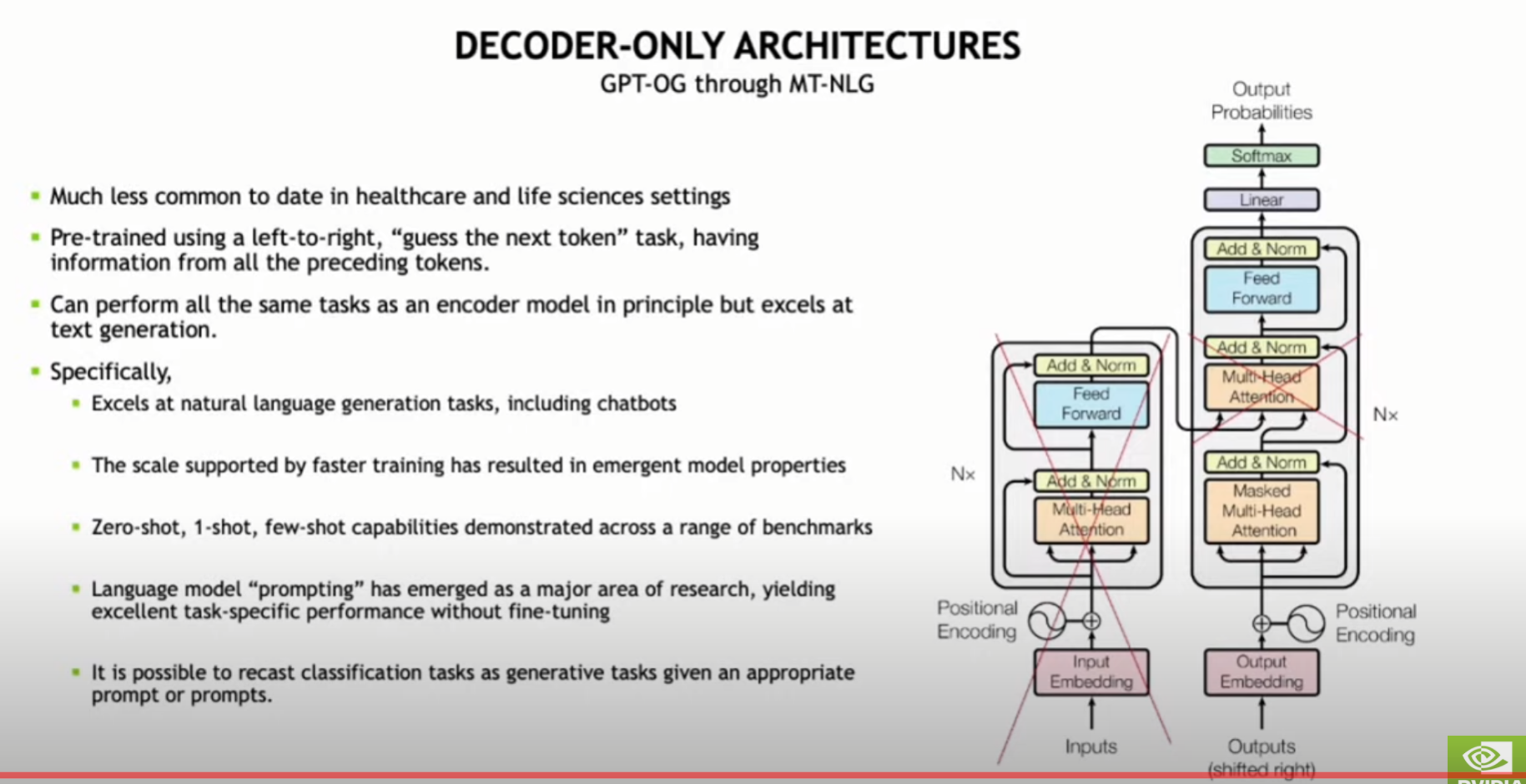
(기타질문) Transformer의 Encoder만 (BERT), Decoder만(GPT) 모델이 유명한데, 왜 둘 다 사용하는 모델이 지양되고, 이런 2가지 모델 형태로 분리되는건가요?
(사전 질문 1) 거대한 언어모델을 이용해야할 것같은데 NVIDIA에서 어떻게 제공해주고 그 비용은 어떠한지 궁금합니다.
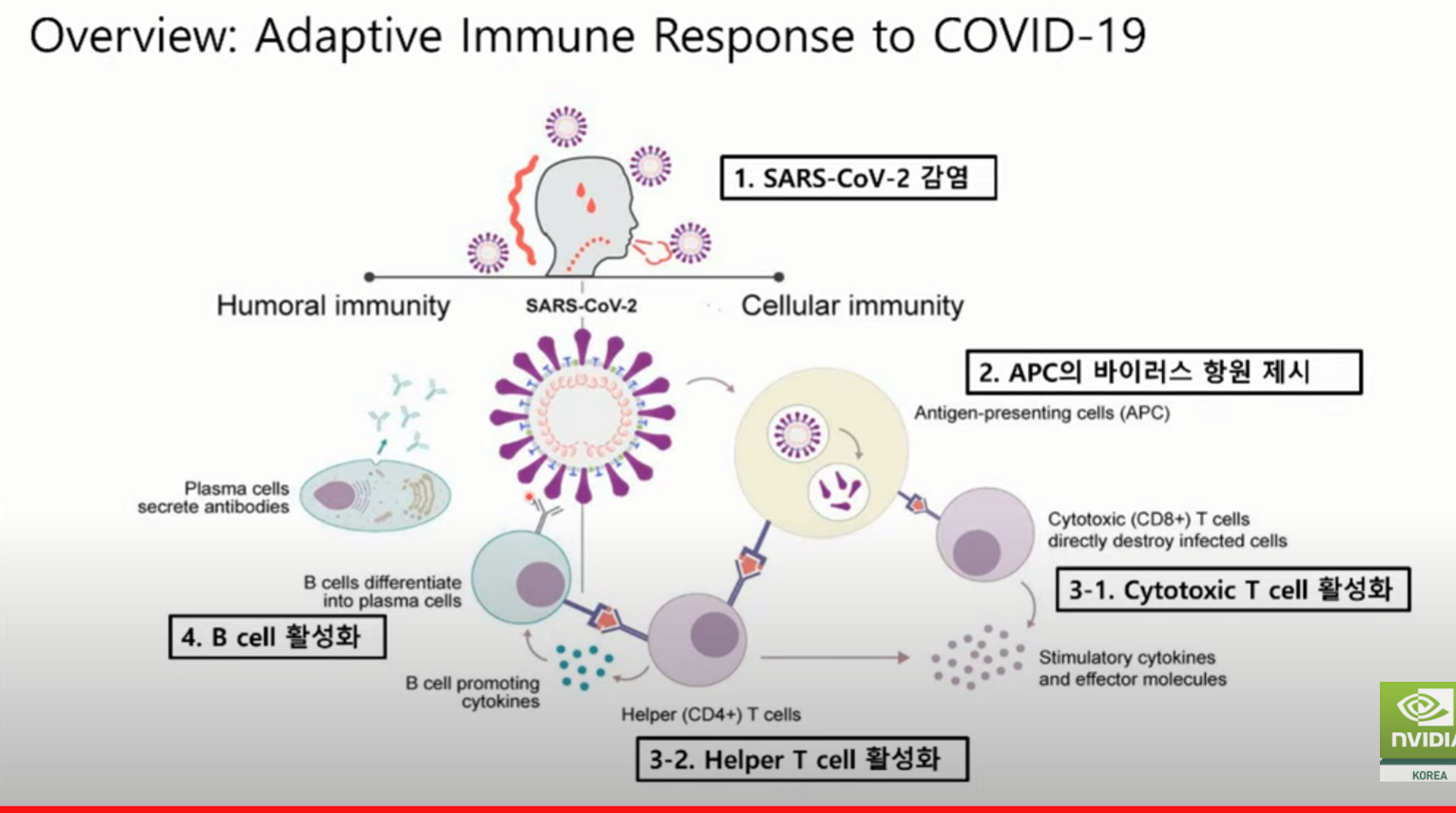
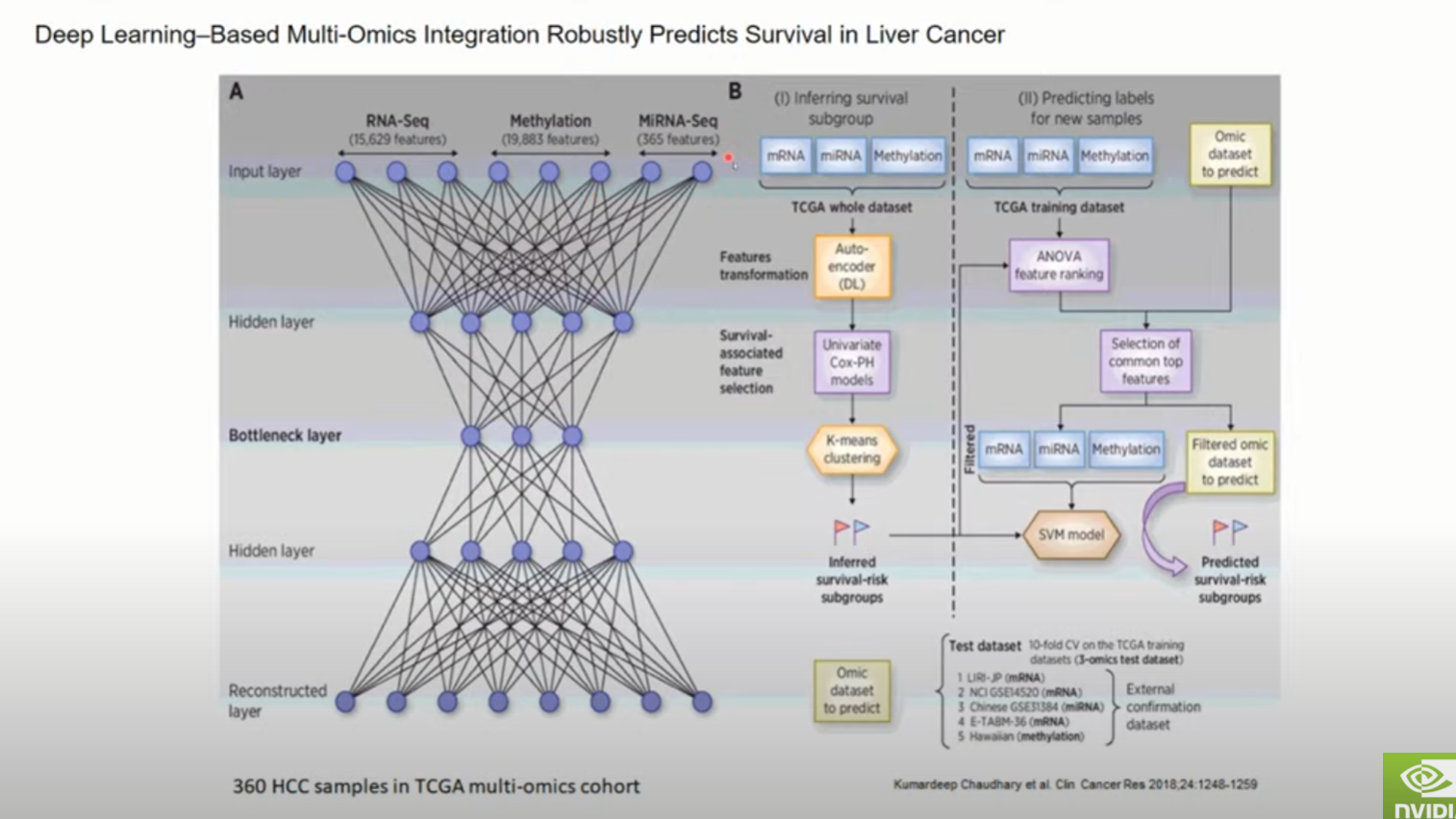
Multi-omics-based severity prediction model for COVID-19 patients.
<BackGround>
감염 -> 바이러스가 세포에 들어감 -> 쪼개져서 세포에 제시 -> 다른 세포들이 활성화되고, B cell 이 항체 만듬.
바인딩이 잘 되어야 중증으로 가지 않게됨. 바인딩 메커니즘에 문제가 생기면 중증 생긴다는 가정..
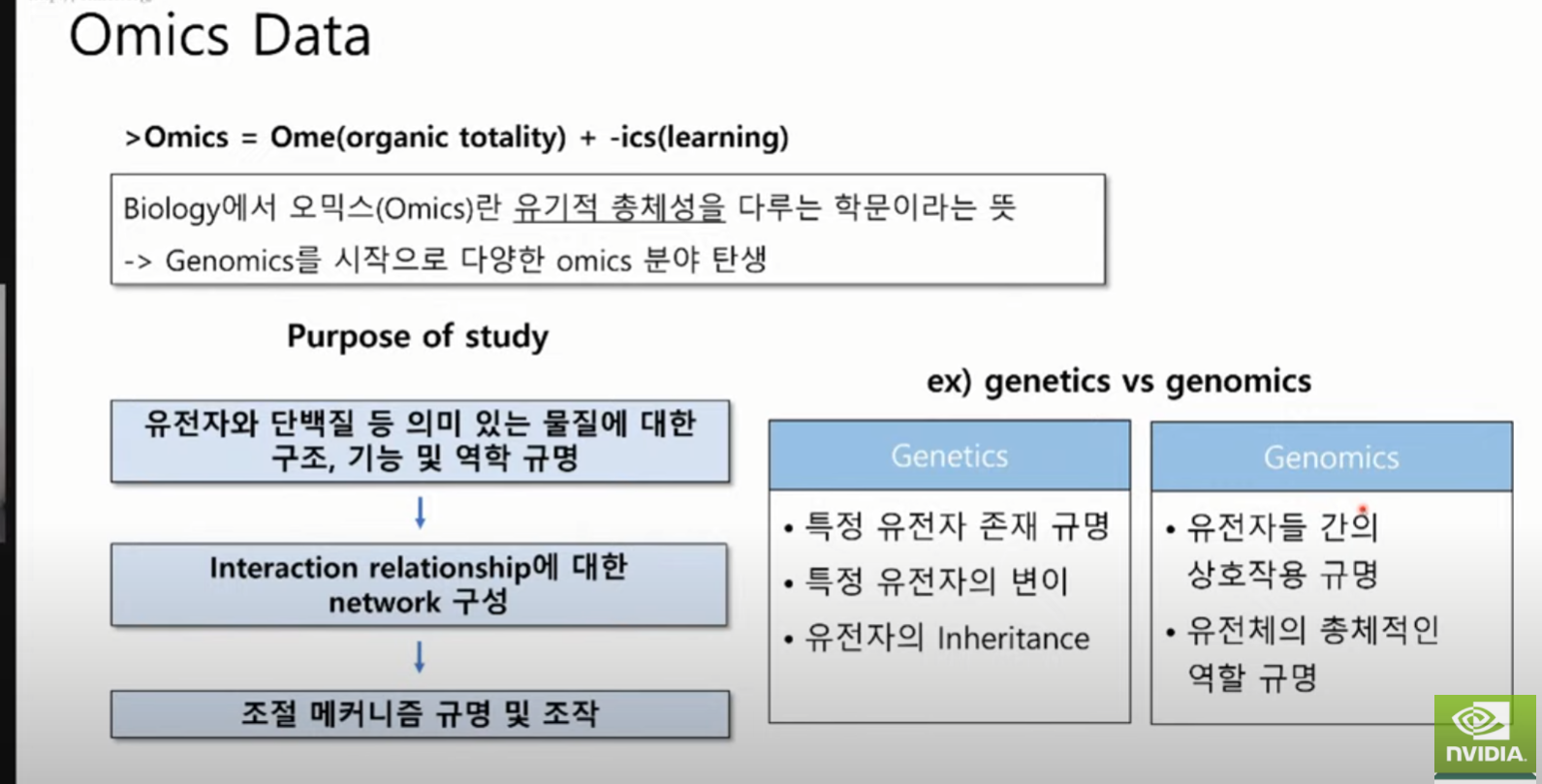
Omics : Total.
-- 선행연구 --
1.
암 전이된사람 vs 암 전이 안된사람 classification.
Gene Expresion + Protein-Protein interaction 정보 --> Graph 로 이용
2.
3.
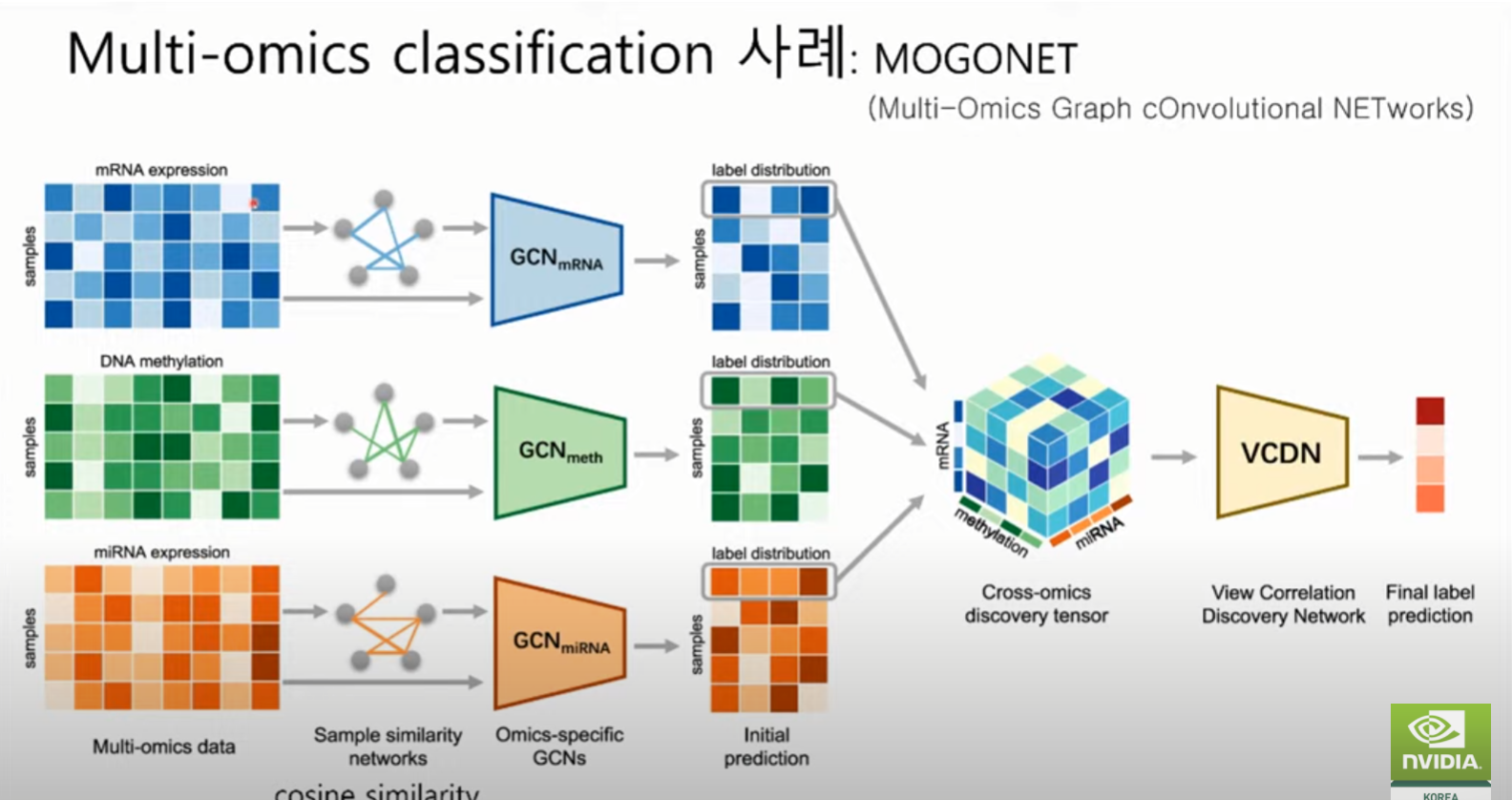
Omics 유사도 구해서, 네트워크 생성 (각각의 Omics 따로 구축한다는 한계)
Protein 유사도 구해서, 네트워크 생성
----> fusion, 하나의 네트워크로 통합 -> classification model & 유사 증상 환자 그룹화
4.
-----------------------
사용 Data
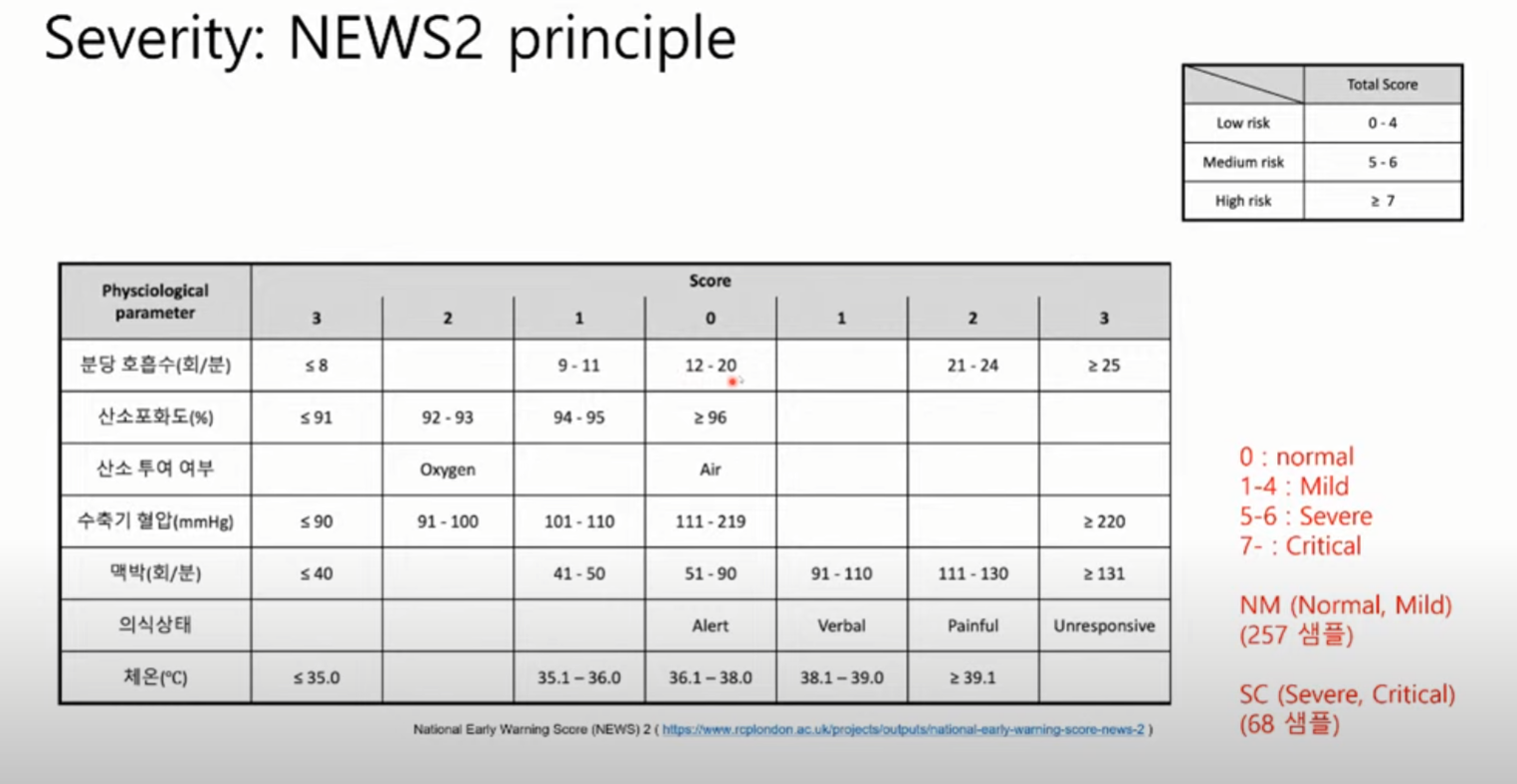
경증 vs 중증 구분 기준
------ 모델 구축
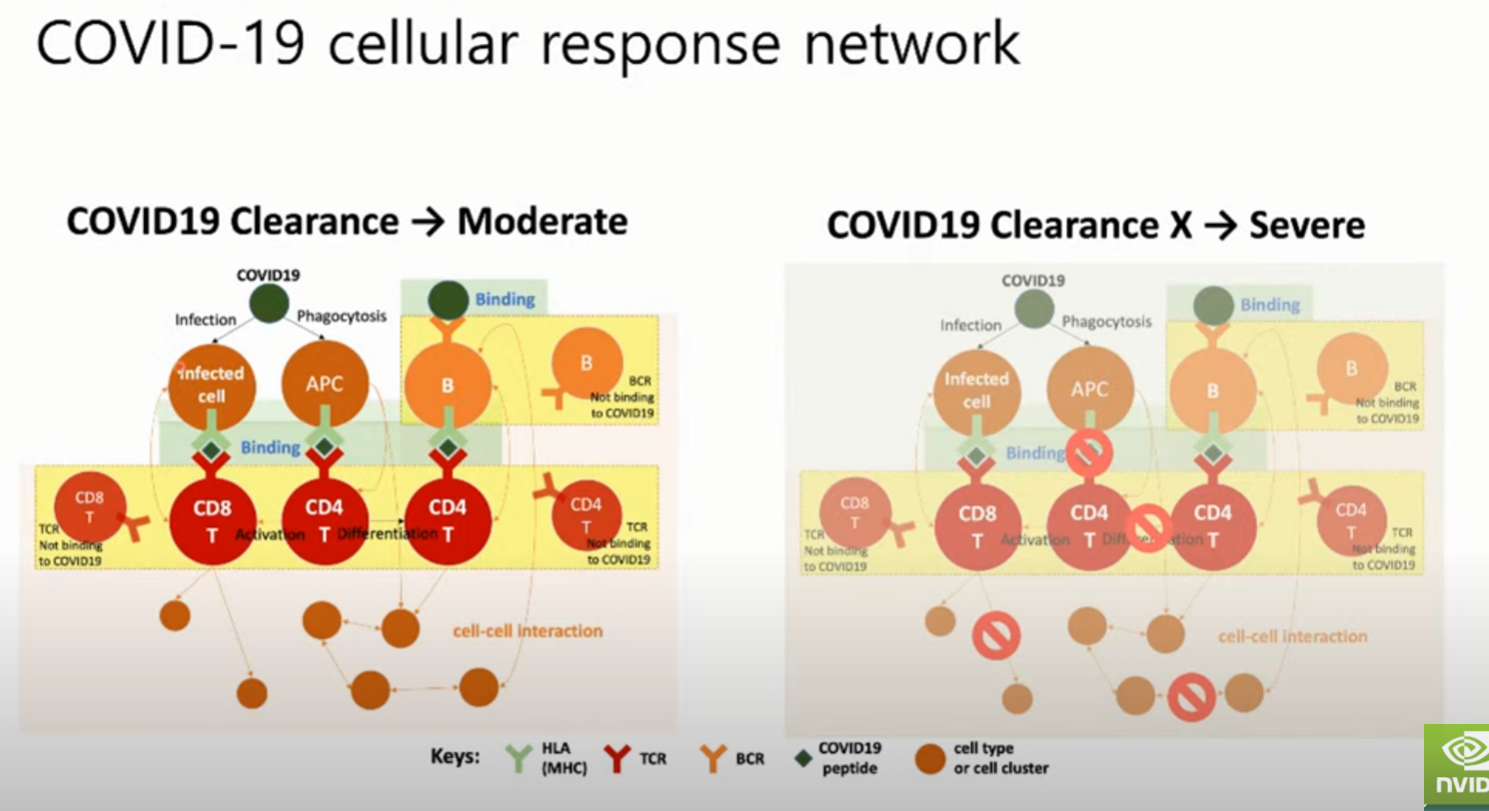
(전제) 바인딩.
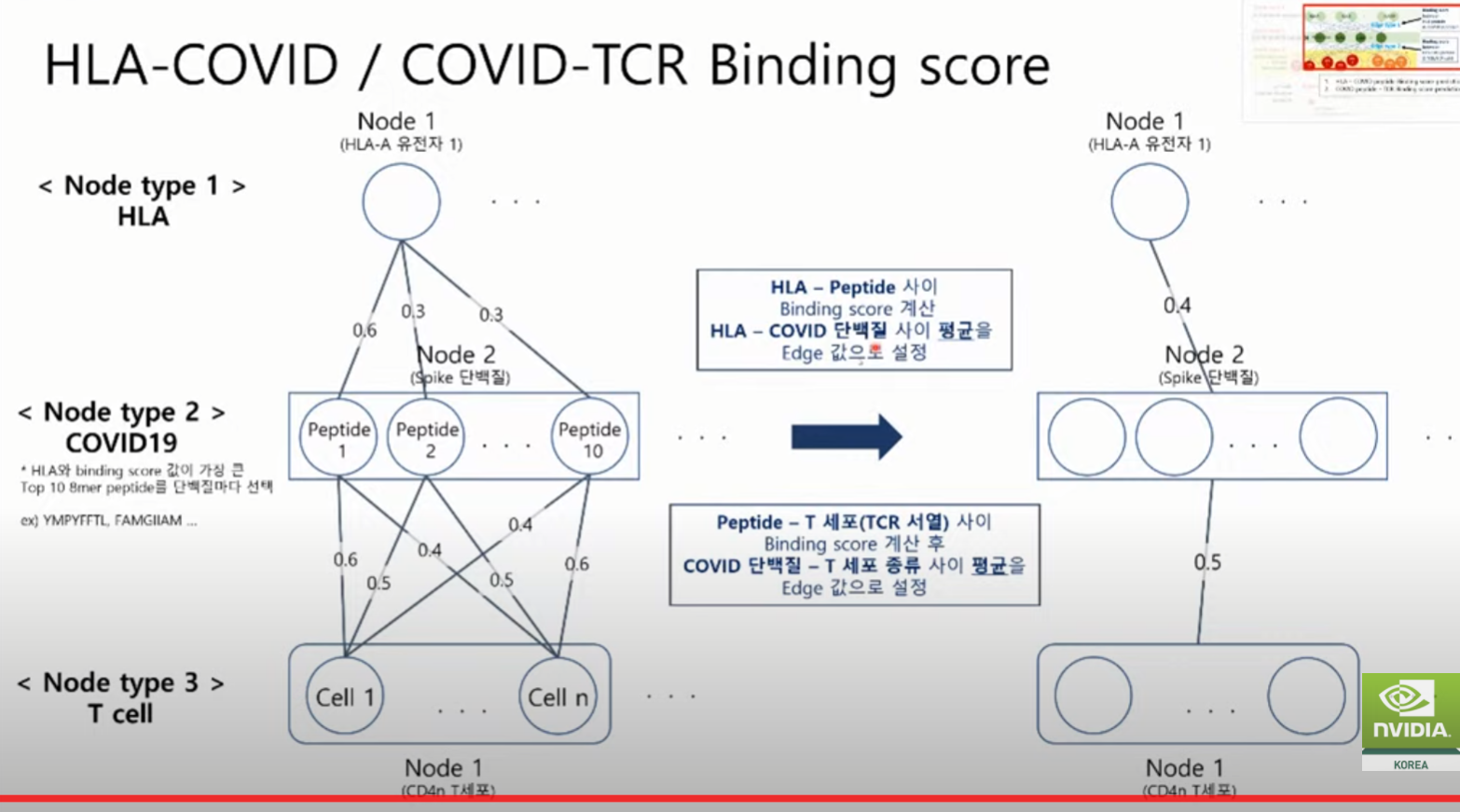
노드타입 : 유전자 정보, 코로나 서열정보, Tcell, Bcell 정보
바인딩 정보 : 노드간의 상호관계
경증과 중증간에 어떤 연결관계가 다른지 확인하고 싶은 것.
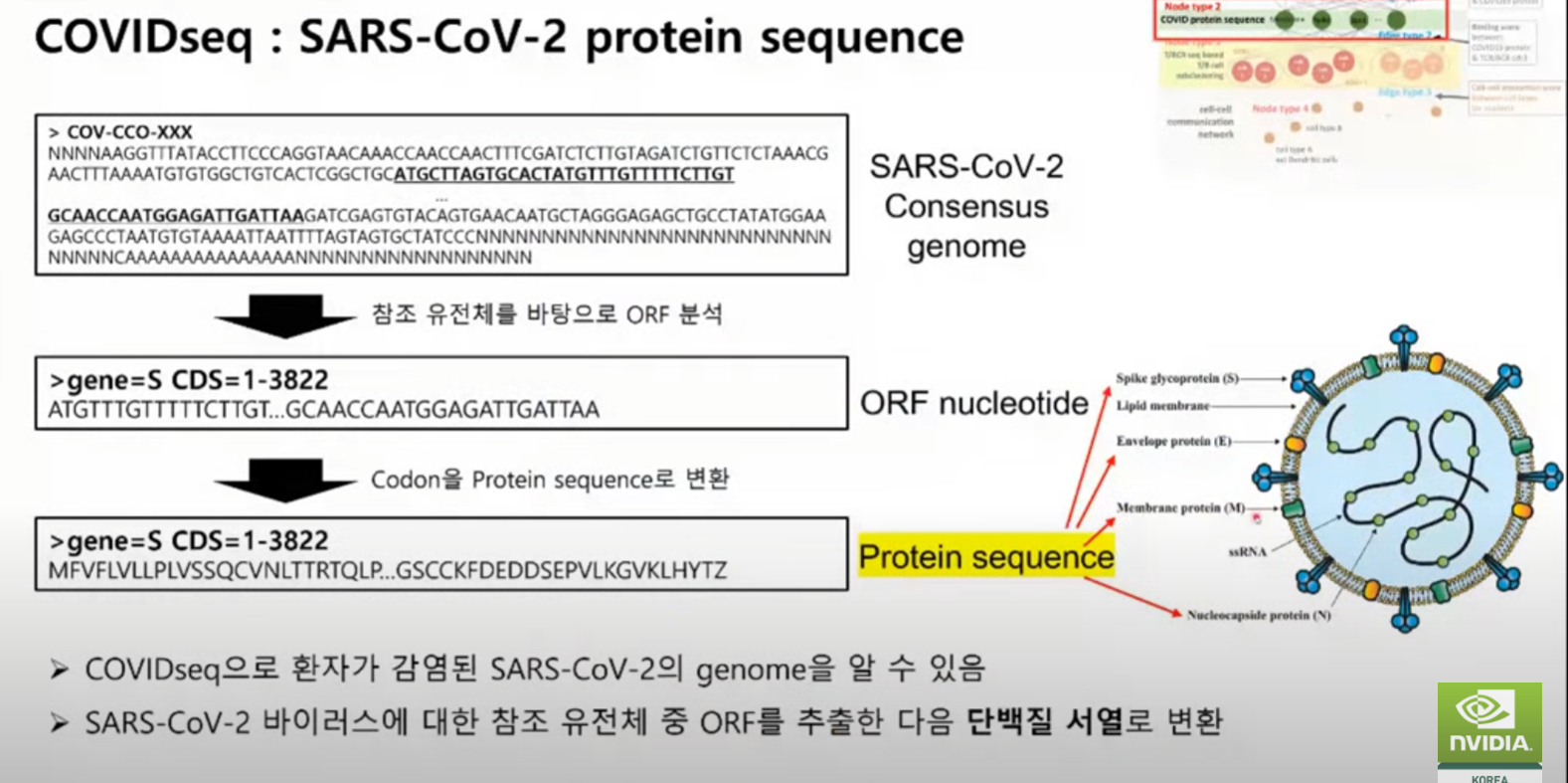
A,U,G,C 중요한 부분 뽑아내서(참조 유전체 바탕 ORF 분석) -> Codon 을 Protein sequence 로 바꿈.
환자마다 각각의 matrix 가 생김.
펩티드 서열 넣으면, HLA-A 값 구하는 Binding 값 내주는 Tool 이 있음.
각각의 바인딩 스코어를 구해서 평균
각각의 서열을 넣고, 바인딩을 구함. 그리고 스코어값이 어떻게 다른지 확인.
바인딩 <- 잘 안되면 항원 제시가 잘 안됨. 혹은 T cell 활성화가 잘 안됨. 높아야 정상 반응
추가적으로..
어떤 Ligand, 어떤 Receptor 가 반응하는지 이미 잘 알려져있음. interaction score 구해서 함.
기존에 있는 것을 이용해 Cell annotation , 이후 Cell-Cell interaction 확인
Cell 안에 어떤 세포,..
-- 결과 --
(아마)교신저자 : kksoo716@gmail.com/ 서울대학교병원 김광수 교수님
마무리 말씀 : Biology -> ML로 계산할 수 있는 문제로 바꾸기까지 Domain knowledge 가 굉장히 많이 필요하다.
[사전질문 및 답변]
질문 1) 멀티 오믹스 데이터를 최적으로 통합하고 분석하기 위해 중점적으로 검토하고 점검해야할 것들?
답변 1) 네트워크 형태로 바꾸는 것이 좋을 것이다. 일단 각각의 데이터셋의 퀄리티를 올리는 것이 중요할 것이다. 모든 feature 를 다 쓰기 보다, 의미있는 feature(약물에 반응하는) 만을 사용하는것이 통합에 도움이 될 것이다.
답변을 얻지 못한 누군가의 질문 >> 코로나 백신도 인체의 면역작용에 기반하는 것으로 보입니다. 어떤 질병은 평생 한번의 백신으로 면역이 유지되는데 반해 코로나는 3~6개월 사이에 부스터샷으로 백신을 추가 접종하였습니다. 질병마다 면역력이 다른 이유를 알고 계시면 설명해주시면 좋겠습니다. 이런 면역력을 길게 더 늘릴 수 있는 방안에 대한 연구도 진행이 되고 있을까요?
폐회사
About 강연 다시보기 :
사전등록하신 분에 한하여 다시보기 링크를 제공할 예정
후기
- NVIDIA 에서 주최하는 만큼 NVIDIA의 MONAI, FLARE 와 같은 TOOL, NVIDIA에서 개발 및 연구한 내용이 주를 이뤘다. 나는 각 주제에서 좀더 General 한 얘기를 들을 수 있을 줄 알았는데, 살짝은 아쉬웠다. 반면 서울대병원 교수진분들은 좀 더 General & Overall 한 내용을 다뤄주셨다.
- 각 세션마다 NVIDIA 연설자가 강연한 이후에 서울대병원 교수진분들이 강연을 해주셨는데, 이 순서를 반대로 바꾸는것이 더 좋을 것 같다는 생각이 든다. 먼저 전반적인 해당 주제에 대한 내용을 다룬 뒤에, NVIDIA의 이를 위한 Tool, 노력으로서의 개발 내용 들을 듣는게 더 유익할 것이라는 생각이 들었다.
- NVIDIA의 MONAI, FLARE 등의 TOOL 및, 데이터 분석을 위한 GPU 등에 관심이 있고, 앞으로 사용해볼 생각이 있는 사람이라면 확실히 도움이 될 것이다. 그게 아니라면 크게 추천하지는 않는다. 개인적으로는 데이터분석을 공부할 사람이라면 앞으로 MONAI, FLARE 등의 툴을 어느정도 이해하고, 경험해봐야 할 것 같아서 듣길 잘했다고 생각한다.
- QnA 시간이 따로 확정적으로 존재하는게 아니어서 아쉽다. 시간이 남으면 그 시간 안에 하고, 시간이 없으면 아예 안하기도 한다. 혹은 강연 중에 실시간으로 질문이 올라오고 답변이 올라오기도 한다. 그렇다보니 본 강연에 집중이 흐트러질때가 종종 있었다.
- 각 세션을 설명해둔 주제와 실제 강연의 내용이 매칭이 안되는 부분이 있는 것 같다. 그리고 녹음된 음성이 명확하게 들리지 않아서 듣기 불편할때가 있었다.
- 가장 아쉬웠던 부분은 자막.. 실시간 강연도 아니고, 시차때문에 녹화된 영상을 틀어주는데 영어/한국어 자막이 없다. 실시간 강연이라면 어쩔 수 없지만 녹화된 영상같은경우는 충분히 달 수 있던 부분이었다고 생각한다.