

Transformer 는 Attention all you is need 논문에서 제안된 모델 구조로, RNN 의 long-term-dependency 의 한계점을 극복하기위해 제안된 아키텍처입니다. (은닉 상태를 통해 과거 정보를 저장할때, 문장 길이ㅏ 길어지면 과거 정보가 마지막시점까지 전달되지 못하는 현상)트랜스포머가 출현함으로써 자연어 처리 분야는 획기적으로 발전되었으며, BERT, GPT3, T5등과 같은 혁명적인 아키텍처가 발전하는 기반이 되었습니다.
트랜스포머는 RNN에서 사용한 순환 방식을 사용하지 않고, 순수하게 어텐션만 사용한 모델이며,셀프 어텐션이라는 특수한 형태의 어텐션을 사용합니다.

트랜스포머는 다음과 같이 인코더와 디코더가 결합된 형태를 가진 모델입니다. 먼저 인코더에 입력 문장(원문)을 입력하면 인코더는 입력문장의 표현을 학습시키고, 그 결과를 디코더로 보냅니다. 디코더는 인코더에서 학습한 표현결과를 입력받아 사용자가 원하는 문장을 생성합니다.
가령 영어를 프랑스어로 번역하는 과제가 있다고 하면, 다음의 그림은 영어 문장을 입력받은 인코더를 나타낸 것입니다. 인코더는 영어 문장을 표현하는 방법을 학습한 다음, 그 결과를 디코더에 보냅니다. 인코더에서 학습한 표현을 입력받은 디코더는, 최종적으로 프렁스러오 번역한 문장을 생성합니다.
트랜스포머는 N개의 인코더가 쌓인 형태입니다. 인코더에 결괏값은 그 다음 인코더의 입력값으로 들어갑니다. 가장 마지막에 있는 인코더의 결괏값이, 입력값의 최종 표현 결과가 됩니다. 입력값으로 입력 문장을 넣게되고, 최종 인코더의 결과값으로 입력 문장에 따른 표현 결과를 얻게됩니다. N=6 이라는 말은 인코더 6개를 누적해 쌓아올린 형태를 표현한 것입니다.

인코더의 세부 구성요소를 표현하면 다음과 같습니다. 모든 인코더 블록은 형태가 동일하며, 그림에 나와있는 두 가지 요소로 구성됩니다. 멀티헤드 어텐션 이해하기 전에, 셀프 어텐션의 작동원래를 살펴보면,
이 문장에서 it 은 dog 나 food 를 의미할 수 있습니다. 그러나 문장을 자세히 살펴보면 it은 dog 를 의미한다는걸 알 수 있죠. 위의 문장이 주어질 때, 모델은 it이 dog 인것을 어떻게 알 수 있을까요? 이때 셀프어텐션이 필요합니다.
이 문장이 입력되었을 때, 모델은 가장 먼저 단어 ‘A’의 표현을, 그다음으로 단어 ‘dog’의 표현을 계산한다음, ‘ate’라는 단어의 표현을 계산합니다. 각 단어를 계산하는 동안, 각 단어의 표현들은 문장안에 있는 다른모든단어의 표현과 연결해 단어가문장내에서 갖는 의미를 이해하게 되는 것입니다. 어텐션을 사용할 때 헤드 한 개만 사용한 형태가 아닌, 헤드 여러 개를 사용한 어텐션 구조를 멀티헤드어텐션이라 부릅니다.
트랜스포머는 RNN과 같이 순환 구조를 따르지않고, 단어 단위로 문장을 입력하는 대신에 문장 안에 있는 모든 단어를 병렬 형태로 입력하게 됩니다. 그러나 병렬로 연결하기 때문에 한가지 문제가 발생하는데, 단어의 순서 정보가 유지되지 않은 상태에서 문장의 의미를 어떻게 이해할 수 있냐는 점입니다. 문장의 의미를 이해하기 위해서는 단어의 순서가 중요하기 때문에, 트랜스포머에 단어의 순서 정보또한 제공하게 됩니다.

다음으로 디코더에 대해서는 간략히 설명하도록 하겠습니다.
디코더는 인코더의 결과값을 입력값으로 사용하게 되는데요.
디코더역시 인코더처럼 N개를 누적해 쌓을 수 있습니다. 디코더 출력값은 그 위에 있는 디코더의 입력값으로 전송되며, 인코더의 출력값은 모든 디코더에 전송이 되게 됩니다. 즉, 디코더는 이전 디코더의 입력값과 인코더의 출력값(표현) 이렇게 2가지를 입력데이터로 받습니다.
원하는 문장을 생성하는 과정을 들여다보면, 시간 스텝 1에 시작을 알리는 <sos>가 입력되며 첫번째 단어인 je을 생성합니다. 이후 je 와 표현 정보 넣고 다음 문장을 생성합니다. 이 과정을 반복합니다.
이후 인코더와 마찬가지로 디코더 입력값에 위치 인코딩값을 더해 디코더의 입력값으로 사용합니다.

하나의 디코더 블록은 다음과 같은 요소들로 구성됩니다. 디코더 블록은 인코더 블록과 유사하게 서브레이어에 멀티헤드~와 피트포워드 네트워크를 포함합니다. 그러나 인코더와 다르게 두가지 형태의 멀티헤드어텐션을 사용합니다. 그 중 하나는 어텐션 부분이 마스크된 형태입니다.
앞서 언급했던 셀프 어텐션은 각 단어의 의미를 이해하기 위해 각 단어와 문장 내 전체 단어를 연결했었던것과 다르게, 디코더에서는 문장을 생성할 때 이전 단계에서 생성한 단어만을 입력문장으로 넣는다는 점이 중요합니다. 즉, 이런 데이터의 특성을 살려 모델학습을 진행해야하는 것입니다. 모델이 아직 예측하지않은 오른쪽의 모든 단어를 마스킹하고, 학습을 진행하게 됩니다.
이러한 마스킹 작업은 셀프 어텐션에서 입력되는 단어에만 집중해, 단어를 정확하게 생성하는 긍정적인 효과를 가져옵니다. 디코더는 vocab 에 대한 확률 분포를 예측하고, 확률이 가장 큰 단어를 선택하는 방식입니다.

최종적으로 인코더와 디코더를 결합한 형태는 다음과 같습니다.
다시 정리하면, 입력 문장을 입력하면 인코더에서는 해당 문장에 대한표현을 학습하고, 그 결과값을 디코더에 보내면 디코더에서 타깃 문장을 생성합니다. 또한 우리는 손실 함수를 최소화하는 방향으로 트랜스포머 네트워크를 학습시킬 수 있겠습니다.
지금까지 Transformer 모델이 무엇인지에 대해 간략히 살펴보았습니다.
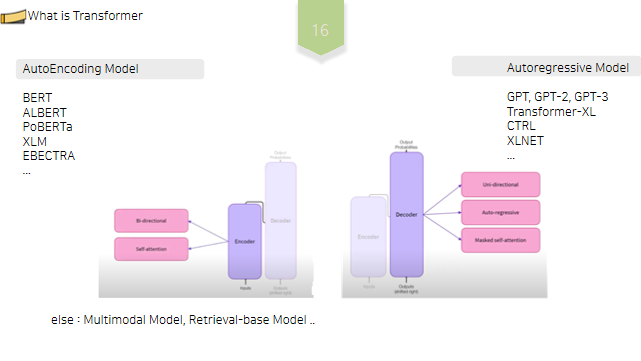
Encoder 만을 사용한 모델은 AutoEncoding Model, decoder 만을 사용한 모델을 Auto regessive Model, Encoder 및 Decoder 를 모두 사용한 모델은 Sequence to Seqence model 이라고 부릅니다. 그 외에도 Multimodal Model, Retrieval-base model 등 다양한 종류가 존재합니다.
Decoder 에 기반한 모델, 즉 Auto regressive 모델에는 GPT, GPT2, Transformer-XL, CTRL, XLNet 등이 있고, Encoding 에 기반한 모델에는 BERT, ALBERT, RoBERTa, XLM, EBECTRA 등이 있습니다.
이 중에서 저희가 오늘 집중해 살펴볼 모델은 transformer-Encoding based 모델인 BERT 와 XLM 입니다.

BERT 는 가장 널리 사용되는 고성능 텍스트 임베딩 모델로, Bidirectional Encoder Representations from Transformers 의 약자입니다. 다양한 자연어 처리 태스크 분야에서 가장 성능이 뛰어나며, 자연어 처리가 전반적으로 한걸음 나아가는데 이바지 한 모델입니다. BERT는 18년에 논문이 공개된 구글의 최신 Language Representation Model 이며, 말씀드렸듯이 인코더 구조만을 활용한 언어 모델입니다.
BERT가 성공한 주된 이유는 문맥을 고려한 임베딩 모델이기 때문입니다. 그렇다면 문맥을 고려했다는 의미가 무엇일까요? 다음 두 문장을 통해 문맥 기반 임베딩 모델과문맥 독립 임베딩 모델의 차이를 이해해보도록 하겠습니다.

A 문장과 B 문장을 보면, 두 문장에서 “파이썬” 단어의 의미가 서로 다르다는 것을 알 수 있습니다. A 문장에서 파이썬이라는 단어는 뱀의 한 종류를의미하고, B 문장에서 파이썬이라는 단어는 프로그래밍 언어를 의미합니다. 워드투벡터와 같은 임베딩모델을 사용해 두 문장에서 파이썬이라는단어에 대한 임베딩을 얻는경우, 두 문장에서 동일한 단어가 쓰였으므로 동일표현. 반면 BERT는 문맥기반. 문맥이해후 다음문맥에따라 임베딩생성. 따라서 서로다른임베딩 제공.
그렇다면 BERT는 어떻게 작동하는것일까요?
먼저 A 문장 살펴봅시다.
BERT는 모든 단어의 문맥상 의미를 파악하기 위해 문장의 각 단어를 문장의 다른 모든 단어와 연결시켜 이해합니다.“파이썬” 문맥상 의미를, BERT는 파이썬이라는 단어를 가져와서 문장의 다른 모든 언어와의 관계 기반 이해를 시도합니다. 따라서 BERT는 파이썬이라는 단어와물었다라는 단어의 강한 연결관계 파악후 뱀의 한 종류 의미 파악이 가능하게 되는 것입니다.
B 문장또한 마찬가지로 모든 단어를 연결합니다. 이를 통해 B 문장의 파이썬이, 프로그래밍이라는 단어와 관련있음을 인지.
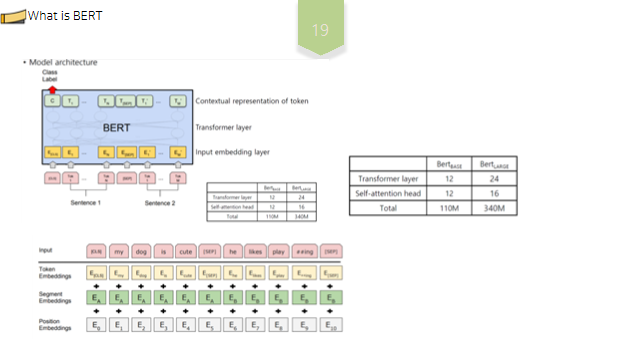
BERT는 L, H, A 파라미터에 따라 성능 및 버전이 달라지게 되는데, 여기서 Layer 는 Transformer 블록의 숫자이고, H는 hidden size, A는 Transformer의 Attention block 숫자입니다. 즉, L, H, A 가 크다는 것은 블록을 많이 쌓았고, 표현하는 은닉층이 크며, Attention 개수를 많이 사용하였다는 뜻입니다. 블록을 n번 쌓았다는 의미는 즉 입력 시퀀스 전체의 의미를 n번만큼 반복적으로 구축하는 것을 의미합니다.
또, 앞서 잠시 언급드렸듯 생성된 Token Emdedding 과 함께, 각 토큰의 위치정보를 임베딩하는 Positional Embedding 과, 문장을 구분하는 segment embedding 까지 총 3개의 임베딩을 결합하여 임베딩을 표현합니다.
BERT를 각 Task에 쓰기위한 예시는 다음의 그림과 같습니다.
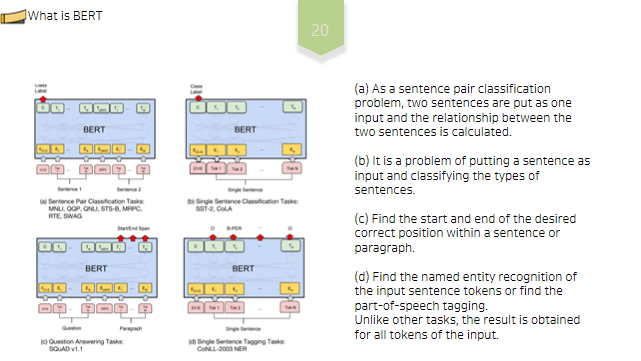
(a)는 문장 쌍 분류 문제로 두 문장을 하나의 입력으로 넣고 두 문장간 관계를 구한다.
(b)는 한 문장을 입력으로 넣고 문장의 종류를 분류하는 문제이다.
(c)는 문장이나 문단 내에서 원하는 정답 위치의 시작과 끝을 구한다.
(d)는 입력 문장 Token들의 개체명(Named entity recognigion)을 구하거나 품사(Part-of-speech tagging) 를 구하는 문제이다. 다른 Task들과 다르게 입력의 모든 Token들에 대해 결과를 구한다.

다음으로 BERT의 사전학습에 대해 설명드리겠습니다. 사전학습이란 무엇일까요.
모델을 하나 학습시켜야한다고 가정해봅시다. 일단 특정 태스크에 대한 방대한 데이터셋으로 모델을 학습시키고 학습된 모델을 저장합니다. 그 다음, 새 태스크가 주어지면 임의 가중치로 모델을 초기화하는대신, 이미 학습된 모델의 가중치로 모델을 초기화합니다. 즉, 모델이 이미 대규모 데이터셋에서 학습되었으므로 새 태스크를 위해 새로운 모델로 처음부터 학습시키는 대신 사전학습된 모델을 사용하고, 새로운 태스크에 따라 파인튜닝하는 것입니다.
BERT 에서는 MLM과 NSP 라는 두 가지 태스크를 이용해 거대한 말뭉치를 기반으로 사전학습, 자가 지도 학습이 이루어집니다. MLM은 Masked Language Model, NSP는 Next-sentence Prediction , 의 약자입니다.
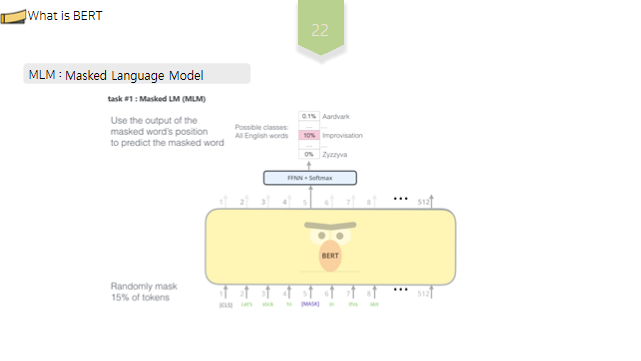
간략히 설명하면, MLM 이란, 문장을 고의로 훼손시킨 후 이를 소스 문장으로 복원하는 방법론으로, 해당 과정에서는 입력문장의 15%에 해당하는 토큰을 임의로 선택하여, 선택한 토큰 중 80% 는 MASK 토큰으로, 10%는 임의의 다른 토큰으로, 그리고 10%는 기존 토큰 그대로 두는 방식으로 훼손시킵니다. 즉 레이블이 없는 단일 언어 말뭉치에서, 기존 문장을 고의로 훼손시키고, 소스 문장으로 복원함으로써, 언어에 대한 양방향적 문맥을 파악할 수 있게됩니다.
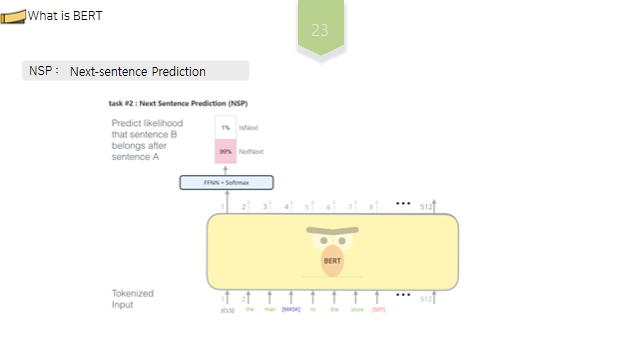
NSP란 입력문장을 구성할 때, 50%는 기존의 순서대로 ㅇㄴ속된 문장을, 50%는 임의로 선택된문장을 연결함으로써 두 문장간의 문맥적 의미를 파악하는 작업을 의미합니다. 두 문장이 연속된문장일때는 1을, 연속되지않은 문장일때는 0을 도출하게함으로써 문장간 연관성이 타당한지를 판별하는 작업을 학습합니다.
이렇게 사전학습을 마친 단어 임베딩은 말뭉치의 의미적, 문법적 정보를 충분히 담고있어, 훈련되지 않은 언어에 대해서도 우수한 수행능력을 보이며, 다운 스트림 테스크를 수행하기위한 파인튜닝 추가학습을 통해 임베팅을 다운스트림 태스크에 맞게 업데이트 하는 방식으로 이루어집니다. BERT가 등장한 이후로는 특정 자연어 처리 관련 문제를 풀기 위한 연구의 방향성이 사전 학습된 모델을 어떻게 활용할 것인가”로 바뀌고 있다고 합니다.

XLM 또한 transformer-인코더 베이스의 모델입니다. 이때 BERT에서 활용된 MLM 뿐 아니라, CLM, TLM 을 추가적으로 활용하여 단일 언어 표현을 완화하고 다양한 언어, 즉 다국어에 대해 모든 문장을 공유 임베딩 공간으로 인코딩 할 수 있는 범용 교차언어 모델을 구축할 수 있게되었습니다. XLM 은 다양한 언어에 대해 공일한 공유 어휘를 사용합니다. 이는 모든 언어의 토큰에 대한 공통된 임베딩 공간을 설정하는데 도움을 줍니다.
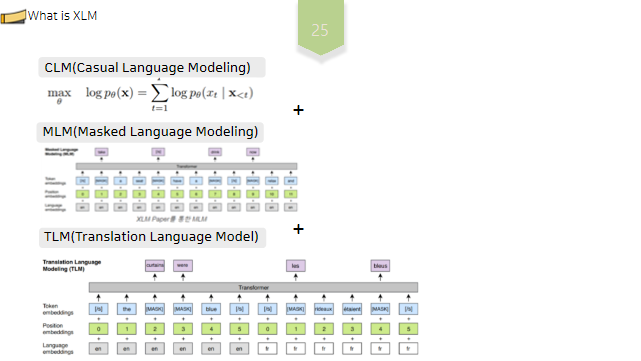
CLM이란 이전 토큰들을 기반으로 다음 토큰을 예측하는 작업을 의미하며, 모델은 훈련과정에서 확률 p를 모델링 합니다. 즉, XLM 모델은CLM 을 학습하는 과정에서, 이전토큰을 통해 다음 토큰을 예측함으로써 문장 구조에 대한 이해를 얻게됩니다.
TLM이란 병렬 말뭉치에 존재하는 소스 문장과 타겟문장을 하나의 입력으로 연결한 후, LML과 같이 문장 일부를 MASK로 치환하고 이를 소스문장으로 복원하는 작업을 의미합니다. 이를 통해 모델은 서로 다른 언어간의 연관성을 더 잘 파악하게 됩니다.
즉, XLM은 여러 언어데이터를 활용한 MLM과 CLM, TLM 학습을 통해 여러 언어에 대한 교차언어 정보를 학습하게 됩니다.
이러한 XLM 을 이용한 다국어 언어 모델은 일반적인 다운스트림 작업에서 더 나은 결과를 얻는데 도움이 되고, 유사한 높은 리소스에 대한 학습을 통해, 낮은 리소스 언어에 대한 모델의 품질을 개선할 수 있습니다.

감사합니다.
이 모델링을 활용한 연구를 확인하고 싶다면 아래 링크로 가주세요.
https://checherry.tistory.com/109
[NAACL] Transformer model을 이용한 자연어처리 최신 논문 / Multilingual Language Models Predict Human Reading Behavi
2021년도 동계 저널클럽 활동을 하며, 발표한 자료입니다. 제가 오늘 함께 공유하고자 하는 논문은 NAACL 저널에 기고된 Multilingual Language Models Predict Human Reading Behavior 입니다. https://aclantho..
checherry.tistory.com
사실 제가 자연어 분야를 제 주요 연구주제로 하고싶은것은 아닌데... 자연어 분야를 계속 찾아보게 되네요.
다양한 분야를 알게되는것이니, 좋죠 뭐!!
다음에는 뇌종양 segmentation 과 관련한 논문을 리뷰해볼 예정입니다!!
(저는 뇌종양에 관한 연구를 하고싶습니다. )
'활동·스터디 > 컴퓨터공학' 카테고리의 다른 글
| [3Dexperience_Part Design(CATIA)] 처음으로 만들어본 3D모델 Lim, Tire (=Wheel) 각종 에러를 딛고 어떻게든 구현했다 (1) | 2022.05.15 |
|---|---|
| [NVIDIA] HCLS Summit Korea 2022 내용 일부 정리 및 후기 (0) | 2022.04.29 |
| Fundamentals of C++ Programming/ Richard L. Halterman/ 17.33-17.34 code review (0) | 2021.12.07 |
| Adaboost Algorithm 파이썬으로 구현하기 (단순사용X!) (0) | 2021.12.07 |
| 내가 보려고 쓰는 유용한 리눅스 명령어 (0) | 2021.11.18 |