
| PLM data를 활용한 질병 예측 시스템 연구 |
| 질병 예측을 위해 사용할 data set에 대한 이해 및 분석을 위한 준비 |
◆ Proposal 변경 사안
1) 기존 : PLM 환자의 질병 이력 데이터를 동시발생그룹화 기법을 통해 분석해 질병 간 연관성을 파악하고, 이를 바탕으로 분류와 계층확률추정기법을 통해 환자의 데이터를 입력하면 그에 따른 질병 발생 확률을 예측하고자 하였다.
2) 구체화 : 1. 모든 질병을 분석하기엔 어려움이 있어 연관성 분석 및 질병예측의 분석 대상을 전 세계 사망원인 1위인 '심장병'으로 특정하였다. 또한 심장 질환과 관련이 깊은 '고혈압' 과 '당뇨병' 을 추가적으로 특정하였다. 2. 질병 예측을 위해 제시한 '분류 기법'을 '의사결정나무'로 구체화 하였다.
구체화에 따라, 소주제 1. '의사결정 나무를 통한 질병예측의 data set으로 '심장병 환자 data set' 을, 소주제 2. 동시 발생 그룹화를 통한 질병간 연관성 분석의 data set으로 '질병코드 data set' 을 준비하였다.
Summary
Ⅰ. Data set에 대한 설명 미국의 환자들의 개인정보와 건강정보, 10년 뒤 심장병 발병 여부에 대한 data set인 ‘Heart Patients’와 2002년부터 2013년까지의 국민건강보험 가입자 중 요양기관으로부터의 진료 이력이 있는 100만 명의 개인정보와 진료내역에 대한 data set인 ‘진료내역정보’를 사용한다.
Ⅱ. Cost & Benefit 두 data set 모두 누구나 이용이 가능한 사이트에서 데이터를 구했으며, 용량이 작으므로, 구입과 저장에 대한 비용이 없고, 얻게 될 benefit은 새로운 서비스 제공이다.
Ⅲ. 데이터 분석을 위해 필요한 형태 Data Preparation 단계에서 해야 할 작업중 하나는 raw data를 우리의 분석 기법 및 목적에 맞게 손질하는 것이다. Attribute header나 데이터의 값이 이해하기 어려운 형태로 되어있거나 데이터의 구성이 사용할 분석기법에 적합하지 않은 경우가 있을 수 있기 때문에 이러한 요소들을 고려해봐야 한다. 여기서 우리의 두 data set에 대해 그러한 점검을 진행해본다.
Ⅳ. Missing value 처리 심장병환자 data set에서 결측값 처리는 범주형 변수인 ‘education’, ’BPMeds’의 결측값은 각각 최빈값으로 대체하고, 연속형변수인 ‘cigsPerDay’, ‘totChol’, ‘sysBP’, ‘diaBP’, ‘BMI’, ‘heartrate’, ‘glucose’의 결측값은 각각 자체 연산에 따라 평균값으로 대체한다. 질병코드 data set의 결측값 처리는 주상병, 부상병 코드가 둘 다 결측 값일 경우, 가입자 일련코드가 결측 값일 경우 해당 record를 삭제한다.
Ⅴ. 정규화 'Z-score normalization'과 'Min-max Scaling' 정규화 방법 중, Min-max Scaling을 이용하기로 하며, 정규화의 전 단계로서 Outlier Detection & Removal - Carling Method을 진행해 Min-max Scaling 기법의 단점을 보완할 수 있도록 한다. 이상치를 제거한 data set에 Replace Missing Number 함수를 이용해 결측치를 채운 후 정규화한다. 정규화는 [ cigsPerDay, totChoi, sysBP, diaBP, BMI, heartrate, glucose ] 총 7 개의 연속형 attribute에 대해 진행한다. 덧붙여, 연관성 분석에 사용되는 data set의 attribute는 대부분 범주형 데이터로, 정규화를 생략한다
Ⅰ. Data Set 에 대한 설명
의사결정나무에는 Kaggle에서 찾은 Heart Patients라는 data set을 사용한다. 이 data set은 미국 환자들의 성(male), 나이(age), 교육 수준(education)의 개인정보와 현재 흡연 여부(currentSmoker), 일일 흡연량(cigsPerDay), 혈압약 복용 여부(BPMeds), 과거 뇌졸중 여부(prevalentStroke), 과거 고혈압 여부(prevalentHyp), 당뇨병 유무(diabetes), 총 콜레스테롤 수치(totChol), 수축기 혈압(sysBP), 이완기 혈압(diaBP), 체질량지수(BMI), 심박수(heartrate), 글루코스 수치(glucose)의 건강정보, 10년 뒤 심장병 발병 여부(TenYearCHD)로 구성되어 있다. 이중 나이와 일일 흡연량, 총 콜레스테롤 수치, 혈압, 체질량, 심박수, 글루코스 수치는 연속형 데이터이고 나머지는 범주형 데이터에 해당한다. PLM에서 얻은 데이터는 아니지만 이 data set의 attribute 중 일일 흡연량을 제외한 다른 것은 모두 수집할 수 있고 10년 뒤 심장병이 발병했는지를 알 수 있기 때문에 심장병 예측 모델을 만드는 데 적합한 data set이라고 할 수 있으며 약간의 결측 치는 있으나 4238명의 데이터를 가지고 있기 때문에 record의 수도 충분하다고 판단했다.
연관성 분석에는 공공데이터 포털에서 찾은 진료내역정보라는 data set을 사용한다. 진료내역정보는 2002년부터 2013년까지의 국민건강보험 가입자 중 요양병원이나 요양 의원과 같은 요양기관으로부터의 진료 이력이 있는 각 연도별 수진자 100만 명에 대한 기본정보(가입자일련번호, 성별코드, 연령대코드 등)와 진료내역(주상병코드, 부상병코드 등)으로 구성된 개방 데이터로 요양기관에서 얻은 자료이기 때문에, 연령층이 높다는 단점이 있으나 우리나라의 경우 의료보험 당연지정제로 출생신고와 함께 의료보험에 가입하게 되므로 많은 사람들의 데이터가 있다는 장점이 있어 해당 data set을 선택하였다.
Ⅱ. Cost & Benefit
데이터에 따라 데이터 ‘비용’은 달라진다. 먼저, 프로젝트를 위한 data set은 Kaggle이라는 데이터 사이트에서 구했다. Kaggle은 기업 및 단체에서 데이터와 해결과제를 등록하면, 데이터 과학자들이 이를 해결하는 모델을 개발하고 경쟁하는 플랫폼이며, 누구나 무료로 데이터를 자유롭게 활용할 수 있도록 제공하고 있다. 따라서 데이터 구입을 위해 지불한 비용은 없다. 다음으로, 이 데이터셋을 저장하기 위해서 비용이 발생할 수 있다. 데이터 저장을 위해선 구글 클라우드나 네이버 클라우드와 같은 서비스를 이용한다. 구글 클라우드인 드라이브는 사진, 동영상, 파일 등을 안전하게 보관하고 공유할 수 있으며, 한 계정 당 15GB 까지는 무료로 이용 가능하다. 하지만, 우리가 가지고 있는 data set은 188KB 밖에 되지 않기 때문에 데이터 보유에도 비용이 들지 않는다. 또한, 모두에게 공개되어 있는 데이터 셋이므로, 유출되었을 때 책임져야 할 비용도 없다.
데이터를 응용했을 때 얻을 수 있는 benefit은 새로운 서비스를 제공할 수 있다는 것이다. 이 데이터셋에는 환자가 입력한 성별, 교육수준, 하루에 피는 담배의 양, BMI지수 등의 정보가 담겨 있다. 이를 이용해 PatientsLikeMe는 심장병의 발병을 예측할 수 있는 새로운 플랫폼을 만들 수 있다. 기존의 단순히 치료법과 증상을 공유하는 사이트에서, 더 나아가 발병의 가능성을 예측해주는 서비스는 분명 PLM에 도움이 될 것이다.
연관성 분석을 위한 질병코드 data set은 마찬가지로 모든 사람이 자유롭게 데이터를 활용할 수 있는 공공데이터 포털 사이트에서 구했다. 또한, 크기는 402,623KB이기 때문에 데이터 구입 및 보유 비용 모두 들지 않는다. 이 데이터에는 한 개인의 성별, 연령, 앓았던 질병 등을 알 수 있다. 이를 통해 각 질병 간의 연관성을 분석해 합병증을 찾을 수 있을 것이다.
Ⅲ. 데이터 분석을 위해 필요한 형태
1. 의사결정 나무 기법_ 심장병 환자 data set
Raw data는 분석 기법과 목적에 따라 다소 다르게 수집될 수 있기 때문에, 우리가 이를 그대로 사용할 경우 분석 도중 오류가 발생하거나, 분석작업이 매우 복잡해 지거나, 오류가 많이 발생하는 모델이 수립되는 등의 문제가 야기될 수 있다. 따라서 다음과 같은 점검의 필요성을 인지하고 점검을 수행해보았다.
점검사항 1) Attribute 이름이 불명확하여 어떤 것을 의미하는지 한눈에 안보이는 것이 있는가?[1]
-> 몇 개의 attribute header가 information-rich하지 못하다.[1] 따라서 우리는 이들의 이름을 다시 붙여줄 필요가 있다.[1] 이때 Camal 표기법을 쓰기로 하자. [1]
prevalentStroke -> PastStroke , prevalentHyp -> PastHyp, diabetes -> PastDiab, heartrate -> HeartPerMin
점검 사항 2) 의사결정 나무의 특성상 통합할 데이터는 없는가?
-> 우리가 사용할 의사결정 나무 기법은 데이터를 분류할 때 교육수준 “2 이하”, “2 초과”와 같이 두 갈래로 나누게 되기 때문에 그 안에서 1과 2가 나눠져 있는 것은 무의미 하며 오히려 복잡성만 증가시킬 수 있다. 1,2,3,4 는 숫자의 크기에 따라 교육수준이 순차적으로 증가하는 특징이 있기 때문에 교육수준을 질병 예측의 요소로서 고려함에 있어서 (1,3), (2,4)와 같이 묶는 것은 바람직하지 못하다. 따라서 1과 2를 0으로, 3과 4를 1로 묶는 것을 고려해볼 수 있다.
2. 연관성 분석 기법_ 질병코드 data set
점검사항 1) 데이터의 규모가 우리의 분석 능력을 벗어나지 않는가?
-> 데이터의 개수가 100만 줄 이상이고 attribute의 수도 많아서 우리의 분석 능력을 벗어난다고 생각했고 이에 따라 다음과 같은 절차를 수행할 필요성을 인지했다.
1. Attribute를 성별, 나이, 일련번호, 질병코드(주상병, 부상병) 등으로 한정
2. 타겟 질병의 코드를 파악 -> 전체 data set 중 target 질병만을 필터링
3. 그 질병을 앓았던 환자들의 일련번호를 필터링 -> 그 환자들의 질병 목록만을 필터링
점검사항 2) 데이터 값들이 이해하기 쉬운가?
-> Attribute는 보고 바로 이해하기에 문제가 없었지만, 질병 코드 attribute의 데이터가 모두 코드 형식으로 되어있어서 알아보기 어려웠다. 이에 따라 질병 코드 검색 결과를 바탕으로 ‘코드’를 모두 ‘질병명’ 으로 바꿀 필요성을 인지했다.
Ⅳ. Missing value 처리
응답자가 의도적으로 응답을 누락하거나 의도하지 않았지만 단순 누락이 되는 경우 결측값이 발생한다. 결측값이 발생한 행을 제거하고 데이터 분석을 진행할 경우 정보에 편향 될 수 있는 가능성을 가지게 된다. 또한 중요한 정보를 담고 있을 수도 있는 그 행의 다른 변수 값도 사라지기 때문에 모델 생성 과정에서 중요한 정보를 놓칠 수 있는 위험이 생긴다.
1) 결측 데이터의 종류
- 완전 무작위 결측 : 어떤 변수 상에 결측 데이터가 다른 변수와 연관이 없다면 이 데이터는 완전 무작위 결측 이라고 한다. 이러한 경우 단순 무작위 표본추출을 통해 결측값을 채울 수 있다.
심장병 환자 data set에서의 완전 무작위 결측 : education, BMI, HeartPerMin, glucose
- 무작위 결측 : 어떤 변수 상에 결측 데이터가 관측된 다른 변수와 연관되어 있지만 그 자체의 비 관측된 값들과는 연관되어 있지 않은 값
심장병 환자 data set에서의 무작위 결측 : currentSmoker – cigsPerDay / BPMeds - PastHyp, PastStroke / PastDiab – totChol / sysBP – diaBP
- 비 무작위 결측 : 완전 무작위 결측 또는 무작위 결측이 아닌 값
2) 결측값 처리 방법
- 예측 모델 : 채우고자 하는 변수와 다른 변수들 간의 관계를 이용한다. 소규모 데이터에는 변수들 간의 관계를 알아내고 다른 외부데이터를 들여와서 관계를 파악해 결측값을 채울 수 있지만 크기가 큰 빅데이터에서는 힘들다.
- 삭제 : 한 개 이상의 결측값을 가진 record를 제거하는 방법. 하지만 표본의 크기를 축소시켜 통계적 유의성을 감소시킨다. 또한 통계적 편향이 생기게 된다.
- 대치 : 결측값을 최빈값, 중앙값, 평균값 등을 이용해 채우는 방법. 주로 연속형 변수 형태의 결측 값은 평균값으로, 범주형 변수 결측값은 최빈값으로 채우기도 한다.
3) 심장병 환자 data set에서의 적용
각 attribute를 대치 방법을 통해 연속형 변수 결측 값은 평균값으로, 범주형 변수의 결측 값은 최빈값으로 채우기로 한다.
- education : 범주형 변수로, 최빈값인 ‘1’로 대체한다. 이 경우에 전체 data의 1~4까지의 비율을 고려하여 결측값을 대체하는 방법도 고안했으나, 각각 입력해야 하고, 어느 row에 어떤 수를 입력해야 하는 지에 대한 어려움이 있어 최빈값으로 대체한다.
- BPMeds : 범주형 변수로 최빈값인 ‘0’으로 대체한다.
- 다음은 연속형 변수의 평균값과 대체값이다
| Attribute | cigsPerDay | totChol | sysBP | diaBP | BMI | HeartPermin | glucose |
| 평균값 | 1.979 | 236.699 | 132.354 | 82.897 | 25.800 | 75.878 | 81.963 |
| 대체값 | 2 | 237 | 132.4 | 82.9 | 25.8 | 76 | 82 |
4) 질병코드 data set에서의 적용
주상병, 부상병 코드가 둘 다 결측 값일 경우, 가입자 일련코드가 결측값일 경우 해당 record를 삭제한다. record가 100만개 이상으로 충분하기도 하고, 가입자 일련번호는 대체할 수 있는 값이 없기 때문이다.
Ⅴ. Normalization_ 정규화
1) Standard Scaling(Z-score) VS Min-Max Scaling
정규화란 normalized or scaled so that they are comparable, 즉 데이터를 비교하기 위해 동등한 속성(척도)를 가지게 하여 의미하는 바를 같게 하는 단계이다. 정규화는 일반적으로 'Z-score Normalization'과 'Min-max Scaling'을 사용하는데, 이를 간략히 설명하면 다음과 같다.
- Z-score Normalization : Sample data가 정규분포를 따른다고 가정하고, 표준 정규분포 식을 이용하여 평균을 0, 표준편차를 1로 정규화하는 방법이다. 이 기법의 downside는 data point 간의 scale이 일정하지 않다는 점과, sample data가 꼭 정규분포를 따를 것이라는 보장이 없다는 데에 있다. 함부로 가정하기는 위험하기에 Z-score 기법을 사용할 때는 먼저 분포의 검정이 필요하다.
- Min-max Scaling : 데이터 범위가 크게 다를 때 유용한 방법으로, sample data가 어떤 분포를 따를 것이란 가정 없이 데이터의 왜곡을 최소화하여 0~1 사이의 값으로 표현하는 방법이다. 이 기법의 downside는 outlier(이상치)에 너무 취약하다는 점이다. 즉, 데이터 하나가 눈에 띄는 이상치를 갖고 있다면 정보의 편향이 발생할 수 있어 위험하다.
본 연구에서는 sample data가 정규 분포를 따른다고 섣불리 가정하지 않고 Min-max Scaling을 이용하기로 하며, 정규화의 전 단계로서 Outlier Detection & Removal을 통해 Min-max Scaling 기법의 단점을 보완할 수 있도록 한다. 전 과정은 삼성 SDS가 제공하는 [Brightics]를 활용한다.
2) Outlier Detection & Removal
이상치 탐지 및 제거는 Tukey VS Carling Method 중, 중앙값을 기준으로 이상치를 탐지하는 방법으로, 변수의 분포를 정규 분포 형태로 가정하지 않을 때 비교적 사용하기 적절한 Carling Method를 선택해 제거하였다. 또한 multipler는 기본 설정값인 2.3을 사용하였다.

범주형 변수인 '나이'를 x축, 연속형 변수인 '이완기 혈압'을 y축으로 놓고 outlier removal 전후를 비교한 그래프이다. 눈에 띄던 outlier data가 제거되었음을 확인할 수 있다. 이완기 혈압의 이상치 뿐 아니라 15개의 모든 attribute에 대해 진행하였다.
3) Min-Max Scaling
이상치를 제거한 data set에 Replace Missing Number 함수를 이용해 연속형/범주형 data의 결측치를 채운 후 정규화한다. Min-max Scaling은 범주형 데이터와 연속형 데이터의 일부(정규화가 크게 의미 없는 경우)를 제외한 [cigsPerDay, totChoi, sysBP, diaBP, BMI, HeartPerMin, glucose] 총 7 개의 attribute에 대해 진행했다.
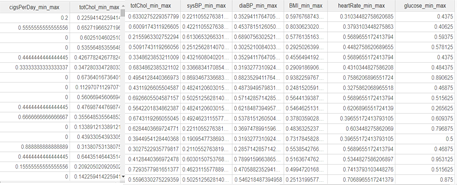

덧붙여, 연관성 분석에 사용되는 data set의 attribute는 대부분 범주형 데이터로, 정규화가 불가능하여 생략한다.
해당 과정은 수업때 교수님께서 Entropy를 엑셀로 직접 계산해 풀 것, 그리고 모델은 의사결정나무로 할 것이라는 제한을 두셔서 Accuracy가 높게 나오진 못한 것 같습니다.
다음번에는 같은 주제에 대해 이러한 제한을 두지 않고 더 많은 방법으로, 다양한 모델을 비교해가며 Accuracy를 높이는것만을 위해서도 프로젝트를 진행해보도록 해보겠습니다.
+ 내용추가)
아래 링크는 본문의 내용과 같은 주제로 진행한 프로젝트 결과인데요, (=만성질환 =>당뇨병)
* 주제만 같을뿐 사용한 툴, 데이터의 전처리방식, 사용된 모델 등 프로젝트의 내용은 전혀 다릅니다!
제약이 많았던 2학년때의 프로젝트 이후, 제약 없이 진행한 3학년때의 프로젝트 결과입니다!
✨A.I.D.D, 최우수상 수상! 2021, AI 당뇨병 발병 예측 데이터톤 참여, 시상식 후기 <전국구 132팀중 최종 2등>✨
'프로젝트·연구 > 프로젝트·연구' 카테고리의 다른 글
| 빅데이터를 이용한 주식가격 예측 시스템 만들기 (1. 개발설계) (0) | 2021.07.27 |
|---|---|
| 빅데이터를 이용한 주식가격 예측 시스템 만들기 (0. 글을 올리기 전에) (0) | 2021.07.27 |
| Brightics Studio를 이용한 심장병 발병 예측모델 구현 (3. Final) (0) | 2021.07.15 |
| Brightics Studio를 이용한 심장병 발병 예측모델 구현 (1. Proposal) (0) | 2021.07.15 |
| Brightics Studio를 이용한 심장병 발병 예측모델 구현 (0. 글을 올리기전에..) (0) | 2021.07.15 |