인간의 내면을 음악으로 듣기 위한 시도는 오래전부터 이루어져 왔다. 1930년대 초기에는 뇌파 알파파의 진폭이나 뇌파 신호의 단순하고 직접적인 특징을 통해 ‘소리’를 만들어 왔고, 1990년대에 이 르러서는 디지털 필터링 및 뇌파 데이터의 분석을 통해 다양하고 새로운 ‘음악’ 생성 규칙을 만들어 왔다.
본 연구에서는 기존의 ‘뇌파를 통해 음악을 생성한다’는 목적에서 더 나아가, 뇌파를 통해 사용자 친화적인 음악을 생성하는 것, 즉 ‘사용자의 감정을 잘 표현해주는 음악’을 만드는 것을 목표로 한다. 사용자는 이로써 나를 잘 표현해주는, 진정한 ‘나만의 음악’을 갖게 될 수 있다. 또, 긍정적인 감정을 보여주는 뇌파를 알고리즘에 넣어 만들어진 음악과, 부정적인 감정을 보여주는 뇌파를 이용해 만들어 진 음악의 비교를 통해 우리는 인간의 내면을 한층 더 알아볼 수 있을 것이다.
개발 목표
EEG 데이터를 통해 감정에 맞는 음악을 작곡하는 알고리즘 모델 개발
1에서 구현된 알고리즘을 통해 사용자가 원하는 악기를 사용하여 음악 작곡
개발 과정
0. 뇌파란?
뇌의 전기적인 활동을 머리 표면에 부착한 전극에서 측정한 전기 신호
주파수 범위에 따라서 델타(0.2Hz ~ 4Hz), 세타(4Hz ~ 8Hz), 알파(8Hz ~ 13Hz), 베타(13Hz ~ 30Hz), 감마(30Hz ~ 45Hz)파로 구분
EEG Data Sample
1. EEG DEAP Dataset
32명의 참가자 → 총 40개의 1분 길이의 영상을 3초 정도의 준비시간을 가지고 시청
Sampling rate를 128Hz로 하여 32개 Channel에서 나오는 뇌파 측정
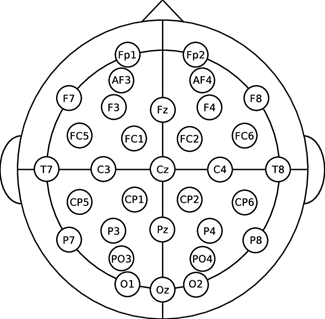
32 Channel
영상 시청 후, 자신이 느낀 감정에 대해 각각의 Label 별로 수치를 결정
Label: 1~9 사이의 실수값으로 정해짐
Arousal: 감정의 격함의 정도 → 높을 수록 감정이 격해짐
Valence: 감정의 긍/부정 정도 → 높을 수록 감정의 긍정의 정도가 커짐
Arousal and Valence Label
2. Preprocessing (전처리)
첫 3초는 감정 분석에 중요하지 않을 것이라 판단하여제거
비교적 감정이 뚜렷한 데이터만을 사용하여 정확도를 높이고자3과 7을 기준으로 Arousal Low /High, Valence Low/High의 네가지 카테고리로 Grouping.
4가지 Category로 Grouping
기존 선행 연구 결과를 참고해감정 분석에 주로 사용되는 12개의 채널 선정.
긍정적인 감정은 주로 좌측 전두엽, 부정적인 감정은 주로 우측 전두엽과 연관되어 있다는 연구 결과에 따라 pair로 선택
뇌파 데이터를 각각Time doamin, Frequency domain, Time-Frequency domain의 영역에서 14개의 Feature 추출.
Time domain
Statistical feature: Mean, Standard deviation, Kurtosis, Skewness
Hjorth parameters (Mobility, Complexity)
Fractal Dimension (Higuchi, Petrosian)
Detrended Fluctuation Analysis
Hurst Exponent
Frequency domain
Power Spectral Density
Maximum Power Spectral Frequency
Root Mean Square
Time-Frequency Domain
STFT (Short-Time Fourier Transform)
Time domain과 Frequency domain에서 추출한 총 13개의 Feature는 모델 학습 시에 사용하였고, Time-Frequency domain 영역에서의 Feature는 음악 작곡 알고리즘의 주요 데이터로 사용.
데이터 전처리 및 Feature Extraction 과정
4. Modeling
앞서 추출한 Time domain과 Frequency domain의 Feature를 이용해,Arousal/Valence 마다 High/Low를 분류하는 이진 분류 모델 생성
전체 데이터를 shuffling 한 뒤train과 test를 8:2로 분리
Data가 biased되어 있어oversampling을 통해 train data의 레이블 값(High: 1, Low: 0)의 비율을 맞춰줌
모델링 과정
13개의 기계학습 모델에 대해 Train data를 이용하여10-fold 교차 검증시행해 정확도 비교
가장 높은 성능을 보인3개의 모델(ExtraTreeClassifier, RandomForestClassifier, LGBMClassifier)을 ensemble
최종 결과 Test data에 대해 각 모델 모두 80%의 정확도를 보임.
5. Music Composition Algorithm
1. 훈련된 모델을 통해 예측한Valence를 통해 Major/Minor 결정
12개의 Channel에서 예측된 Label 중 많이 선택된 Label을 선택
High: Positive → Major
Low: Negative → Minor
Major/Minor 결정
2. 훈련된 모델을 통해 예측한Arousal를 통해 Tempo 결정.
12개의 Channel에서 예측된 Label의 비율을 통해 Tempo 결정
High: Excited → Fast Tempo
Low: Relax → Slow Tempo
Temop 결정
3. frequency domain의Maximum Power Spectral Frequency (MPSF)로 Key Chord결정
감정을 더 잘 나타낼 수 있도록 beta-gamma 대역대에서 MPSF 추출
기본 오른손 주파수 대역대로 Scaling
가장 가까운 Chord를 통해 Key chord와 scale 결정
Valence model로 예측한 결과가 High, MPSF Scaling 결과 C chord에 가장 가깝다면, "C Major Scale"을 이용해 작곡
4. Time-frequency domain의STFT로 Melody 결정
1초 단위로 분할
각 구간 별 최댓값을 가지는 주파수를 3번의 방법으로 Scaling하여 Key Chord의 Scale에 가장 가까운 음을 결정
Melody 간격이 너무 넓은 경우, 기존의 박자보다 더 작은 박자로 Interpolation하여 자연스러운 Melody 구성
좀 더 풍부한 음악을 위해, 왼손은 오른손에서 Octave를 2단계 내린 1도 화음을 치게 해 반주 구성
GUI (Graphic User Interface)
박스 안에 EEG Signal Drag and drop
"1. Extract Feature" 버튼을 눌러 12개의 Channel에 대해 총 14개의 Feature를 추출
"2. Emotion Analysis" 버튼을 눌러 Arousal과 Valence 예측
사용자가 원하는 악기를 선택하고, "3. Convert Signal to Music"버튼을 눌러 2와 3에서 추출한 feature와 예측된 결과를 이용해 음악 작곡
작곡된 음악은 어플리케이션이 저장된 경로의 music 폴더에 저장됨
"4. Reset" 버튼을 눌러 초기화 한 뒤, 다른 EEG Signal에 대해 1~5번 순서를 반복하여 또 다른 음악을 작곡할 수 있음.
기대 효과 및 활용 방안
뇌파 데이터를 통해 ‘나만의 음악’을 만드는 접근 방식은 마음의 세계를 음악으로 표현하려는 시도이다. 본 연구는 특히 사용자의 ‘감정 상태와 유사한’ 음악을 만드는 것이 목적이기에 기존의 연구보다도 내면을 음악으로 표현하는데 더 큰 의의를 가질 것으로 보인다. 사용자는 자신의 내면과 감정이 담긴 음악을 통해 자신의 상태를 피드백 할 수 있게 되며, 나아가 본인이 선호하는 악기 뿐만 아니라 음악의 장르를 선택하여 내면의 감정을 해당 장르의 음악으로 표현함으로써 사용자 내면의 익숙하지 않은 감정에 더 쉽게 다가갈 수 있다.
안녕하세요! 시험기간이기도 하고, 이래저래 진행되는 프로젝트나 일정이 많아 오랜만에 인사드리게 되었네요. 오늘의 소식은 전국구 데이터톤!Artificial Intelligence Diabetes Datathon, AIDD -인공지능 당뇨병예측 모델개발에 참여하여 최종2위의 성적으로 최우수상을 수상하게 되었다는 것입니다! 짝짝짝🎉
주제는 당뇨병 및 합병증 추적 관찰 데이터를 활용한 당뇨병 발병 예측 인공지능 모델 개발로, 인공지능 학습용 데이터 구축 사업 중 ‘당뇨병 및 합병증 추적관찰 임상데이터’ 과제의 일환으로 진행되었다고 해요.
제가 이 블로그에 예에에에전에 업로드 한 글 중 '의사결정나무를 이용한 당뇨병 진단 모델개발'프로젝트가 있었는데, 그때 '교수님께서 모델로는 의사결정나무 단일모델을 사용해야하며 엑셀로 직접 Entropy 등을 계산해 풀어야한다'고 제한을 두셔서 정확도가 높은 모델을 개발하지 못해 아쉬움이 남는다고, 후에 좀 더 자유로은 환경에서 정확도 높은 모델을 개발해보겠다고 말을 꺼냈었는데, 그 다짐을 이렇게 지키게 되네요.
AIDD 데이터톤의 참가대상은 국내 AI, 빅데이터 관련 기업 및 연구기관 종사자, 대학/대학원생이 1~5명 단위의 팀을 구성해 누구나 참여할 수 있었고, 저희는 같은 랩실의 학부연구생 및 석사연구원이 팀을 이뤄 참여하였습니다. (AIMS) 누구나 참여할 수 있다보니 참가자분들도 다양하더라구요. 카이스트, 포항공대 재학생을 포함해 서연고서성한 등의 학생들, 석사생들, 교수님들, 인공지능 관련 책을 쓰신분들까지...
듣기로는 총 참가신청한 팀은 132 팀이었고,
그 중에서 서류 전형으로 예선에 참가할 40팀을 선정하고, 예선에서 본선에 참가할 20팀을 선정하고,
본선에서는 상위 4위까지를 선정하는 방식이었는데요!
이때 NSML 리더보드를 통해 모든 팀의 실시간 score와 순위를 확인할 수 있어서 더 승부욕이 돋고 재미가 있던 것 같습니다. (NSML 리더보드 사용법은 추가적인 글로 간단히 게시해둘 예정입니다)
예선이 딱 3일, 본선도 딱 3일이고, 1시간 당 최대 1번씩 Submit해야한다는 제한이 걸려있어서 적은시간, 적은기회 안에 타임어택으로 높은 점수를 노려봐야했었는데, 그러다보니 다들 합숙을 하시는건지.... 정말 꾸준히 submit 을 하시더라구요... 대회 진행 기간인 총 72시간, 그러니까 즉 72번의 submit 기회중에서 69번을 submit 한 팀도 있었습니다. (-> 이분들이 1등) 물론 저희 팀도 분석하느라/논의하느라 자주 밤을 샜습니다...^^,,,,, (기진맥진) 그런데......... AIDD 에서 분석시 사용되는 데이터가 의료 데이터다보니, 개인정보가 중요하다며 주최측에서 데이터셋을 주지 않아서, 참가자들은 데이터셋의 Feature 종류만 알고 데이터의 분포 등을 확인하지 못한채로 오직 서버에서 데이터를 사용하여 훈련시켜야하고, 테스트셋에는 아예 접근 자체(보는 등)를 할 수 없어서 로컬PC에서는 모델의 score값을 볼 수 없는 구조였습니다. (score=AUC값) 즉, 우리 팀의 score를 확인할 수 있는 유일한 기회는 1시간에 1번있는 submit 을 통해서 였던거죠... 그나마 Validation set을 이용해서는 score를 확인할 수 있었으나, Test set 과는 또 차이가 있으니.. 사실상 스스로 모델을 평가할 수 있는 지표가 거의 없었다고 볼 수 있습니다. 1시간에 1번씩 성능을 확인할 수 있다면 모델이 개선되는 속도가 느릴 수 밖에요.. 이 점이 진짜 진짜 불편했습니다. -_-
왜 이렇게 한거에요.....!!!! 분석할 데이터셋에 대해 아무것도 알 수 없으면 그게 분석일까요? 최적 모델/파라미터 찾는 노가다지....!!!! ㅠㅠ
교수님께서도 데이터분석 공모전을 진행하는데 데이터셋을 안주는건 아닌것같다고 하셨습니다.
이게 본선 리더보드인데요~ 2 위에 랭킹되어있는 AIMS 가 저희 팀입니다! 수상팀의 최종 Score는 1등팀 0.903932, 2등팀(우리) 0.887426, 3등팀 0.866463, 4등팀 0.859686 으로 마무리가 되었습니다. 모델 평가시 사용된 'Score'는 ROC-Curve 하단 영역의 넓이, 즉 AUC 값 이었습니다. 그런데 저는 이해가 안됐던게, ROC-curve를 그릴때 당연히 True Label과 Predict 'Probability' 를 input 하여 구해야하는데, 이 데이터톤에서는 Predict Probability가 아니라 Predict Label을 넣어 구한다는 것입니다. 그러면 ROC-curve 그래프에는 대각선의 끝과 끝을 잇는 점과, 그 중간의 하나의 점만(Threshold=1개) 찍히게 되고 결과적으로 삼각형의 형태를 가지게 되죠. ROC-curve는 보통 그렇게 안그릴텐데 왜 이렇게한건지 잘 모르겠습니다. 모델 개발을 하다 느낀것은.... score = 0.90 과 0.88 사이에는 엄청난 벽이 있고, 0.88 과 0.86 사이에는 엄청난 벽이 있다는 것입니다.. 물론 0.86 언저리까지 오는데도 벽은 있지만요..
아무튼! 이번 데이터톤이 제 인생에서 처음으로 참가한 인공지능 개발 챌린지였는데, 좋은 성과를 얻어 기쁩니다 :> 대회가 진행되던 6일동안 랩실 선배님들과 함께 이런저런 논의를 하며 공부한것도, 학습에 큰 도움이 되었습니다. 선배님들이 진짜 캐리하셨어요.. 다들 고생하셨어요 TT
곧이어 부정맥 진단 모델 개발 인공지능 데이터톤도 참가할 예정인데, 이건 주최측의 사정으로 일정이 미뤄지는바람에 시험기간과 겹쳐서........ 할지 말지 살짝 고민중입니다. -> 미참가로 결정 저는 밀린 과제/수업/일정 등등이 많아서.. 나중에 글을 또 쓰도록 하고 이만 줄이겠습니다. 안뇽
+12.08 추가) 내일(12.09) 시상식 및 모델 발표가 오프라인/온라인으로 있습니다!
코로나때문에 발표자 1명만 오프라인으로 참석할 수 있고, 남은 팀원은 온라인으로 참석해야한다고 하더라구요. (아쉽)
시상식 후기는 내일 이 글에 추가적으로 남기기로 하고,
저희가 구현한 모델을 설명하는 글을 따로 올릴까는 생각중에 있습니다.
아마 시험이 끝나고 업로드하게되지않을까싶네요!
+12.09 추가) 시상식이 끝난후, 짧은 후기!!
시상식은 말씀드린대로 온/오프라인 혼합 형태로 이루어졌고, 랩장님이자 팀장님께서 오프라인으로 발표를 하러 가셨습니다!
저는 온라인으로 시상식을 봤는데, 1등팀하고 4등팀이 포항공대 학생들, 3등팀이 모 대학의 교수님들이셨습니다! ㄷ.ㄷ,,
시상과 함께 각 팀의 모델 설명(발표)을 들을 수 있어서 유익한 시간이었던것같습니다. (대체 1등팀 무슨짓을한것인가 했는데!)
바빴던 2021년! 2021년의 절반의 시간을 들여 진행한 댓글분석 웹페이지 제작 프로젝트가 상위 8팀 안에 들어 은상을 수상하게 되었습니다! (짝짝짝) -> 300만원... 흐흐
저번주 주말에 저와 또 다른 팀원 둘이서, 팀을 대표하여 서울의 코엑스로 발표를 하러 갔었는데요.
발표 + 완성된 작품시연을 해야해서 혹시나 시연중에 오류가 뜨면 어떡하지 긴장이 되었었는데, 무사히 잘 넘어갔습니다. 질문도 어느정도 예상하던 질문이 나와 잘 대처할 수 있었어요.
사실 발표 아침까지도 웹페이지에 넣을 추가적인 코딩을 하느라 바빴었습니다. 뉴스 분석 페이지에 들어간 감성분석 모듈이, 기존에는 감성사전을 이용해 하는것으로 만들었다가 논의끝에 딥러닝 모델을 이용해 감성분석을 하는것으로 발표 1주전에 결정났거든요.. 쇼핑몰 페이지나 뉴스페이지의 감성분석 파트는 제가 전담했었기때문에, 후반부부터 딥러닝 모델로 변경하느라 혼자 마음이 급했던 기억이 납니다.
다행히 발표 전날까지는 완성을 했지만... 완성된 감성분석 모듈을 페이지에 넣고 보니, 사용자가 입력한 URL을 댓글을 긁어오고 댓글을 하나하나 분석해 Label을 붙이는데 생각보다 시간이 너무 오래걸려서 웹페이지에 못넣겠다는 판단이 되어서, 댓글 하나하나가 아니라 한꺼번에 예측할 수 있도록 하고, 더 모델 복잡도가 작으면서 정확도는 유지할 수 있도록 하는걸 발표날 아침까지 수정하고 또 수정했었습니다. 무사히 작동해서 다행이에요.
다음에는 12.3일에 일산 킨텍스로 시상 및 전시를 하러 갑니다. 전시를 대비하여 저희 웹사이트도 로딩페이지 추가, UI의 대대적인개편 등의 버전 업그레이드를 하였습니다. 다음에는 전시 및 시상식 후기를 남기도록 할게요.
뇌파 기반 사용자 친화 음악 작곡 알고리즘 구현 (User-friendly music composition based on EEG)
1. 과제 개요
가. 과제 선정 배경 및 필요성 인간의 내면을 음악으로 듣기 위한 시도는 오래전부터 이루어져 왔다. 1930년대 초기에는 뇌파 알파파의 진폭이나 뇌파 신호의 단순하고 직접적인 특징을 통해 ‘소리’를 만들어 왔고, 1990년대에 이 르러서는 디지털 필터링 및 뇌파 데이터의 분석을 통해 다양하고 새로운 ‘음악’ 생성 규칙을 만들어 왔다. 본 연구에서는 기존의 ‘뇌파를 통해 음악을 생성한다’는 목적에서 더 나아가, 뇌파를 통해 사용자 친화적인 음악을 생성하는 것, 즉 ‘사용자의 감정을 잘 표현해주는 음악’을 만드는 것을 목표로 한다. 사용자는 이로써 나를 잘 표현해주는, 진정한 ‘나만의 음악’을 갖게 될 수 있다. 또, 긍정적인 감정을 보여주는 뇌파를 알고리즘에 넣어 만들어진 음악과, 부정적인 감정을 보여주는 뇌파를 이용해 만들어 진 음악의 비교를 통해 우리는 인간의 내면을 한층 더 알아볼 수 있을 것이다. 나. 과제 주요 내용 1) EEG Dataset( DEAP, AMIGOS, SEED 등 )을 수집한다. 2) EEG Data의 각 신호의 특징을 분석 및 추출한다. 3) 파악한 특징에 맞춰, 각 신호와 음의 높낮이, 단조, 템포 등을 매핑하여 음악을 작곡한다. 4) 작곡된 음악을 여러 장르로 변환하여 사용자에게 제공한다. (팝, 재즈, 클래식 등)
2. 과제의 목표
가. 최종결과물의 목표 1) EEG 데이터를 통해 감정에 맞는 음악을 작곡하는 알고리즘 모델 개발 2) 1)을 통해 작곡한 음악과, 실험자들의 감정이 가지는 상관관계 평가 3) 1)의 음악을 사용자가 원하는 장르(클래식, 재즈, 팝 등)로 변환하는 모델
나. 최종결과물의 세부 내용 및 구성 1) 뇌파 데이터를 통해 사용자의 감정이 잘 드러나는 음악을 작곡하는 알고리즘 2) 실험자(기존 EEG 데이터 사용)의 뇌파를 통해 작곡된 음악 3) 작곡된 음악과 실제 감정과의 상관관계 분석 4) 긍정적인 감정의 뇌파 데이터를 이용해 만든 음악과, 부정적인 감정에서 만든 음악의 비교 5) 원하는 장르로 변경한 2)의 음악
3. 기대효과 및 활용방안 뇌파 데이터를 통해 ‘나만의 음악’을 만드는 접근 방식은 마음의 세계를 음악으로 표현하려는 시도이다. 본 연구는 특히 사용자의 ‘감정 상태와 유사한’ 음악을 만드는 것이 목적이기에 기존의 연구보다도 내면을 음악으로 표현하는데 더 큰 의의를 가질 것으로 보인다. 사용자는 자신의 내면과 감정이 담긴 음악을 통해 자신의 상태를 피드백 할 수 있게 되며, 나아가 본인이 선호하는 음악의 장르를 선택하여 내면의 감정을 해당 장르의 음악으로 표현함으로써 사용자 내면의 익숙하지 않은 감정에 더 쉽게 다가갈 수 있다.
4. 수행 방법 가. 과제수행을 위한 도구적 방법 1) EEG Data Processing TEAP 등을 이용해 EEG Data를 전처리하고, 감정별 신호의 특징을 파악한다. 2) 인공지능 기반 음악 작곡 1) 의 결과를 바탕으로, 각 신호에 대해 음악의 구성 요소들을 매핑하는 알고리즘 모델을 구현한 다.(속도, 멜로디, 음량 등) EEG 데이터가 입력됨에 따라 각 신호 및 채널을 구분하고, 구현된 음악 매핑 알고리즘에 넣어 음악의 멜로디, 음량, 템포 등을 시시각각 결정하며 하나의 악보를 완성한 다. 이후, 악보를 음악으로 구현해주는 툴을 사용하여 음악으로 변환한다. 3) 작곡된 음악의 장르 변환 JukeBox나 CycleGAN-Music-Style-Transfer 등의 음악 장르 변환 알고리즘을 활용하여 작곡된 음악 을 클래식, 재즈, 팝 등의 장르로 변환한다.
나. 과제수행 계획 1) EEG Data Analysis 가) EEG Data Set(DEAP, AMIGOSM, SEED 등)을 수집 나) EEG Data 전처리를 통해서 감정에 따라 변화하는 유의미한 특징을 추출한다. 2) 뇌파를 통한 작곡 가) EEG 데이터의 각 채널이 음악의 어떤 요소를 결정지을 수 있을지 매핑하는 알고리즘을 구현 한다. 나) 해당 알고리즘에 EEG 데이터를 입력해 악보를 완성하고, 곡을 음악으로 변환시킨다. 3) 2)에서 작곡한 음악을 음악 장르 변환 알고리즘을 사용하여 다양한 장르의 음악을 작곡한다.
최근 인터넷이 발달하고 사용자가 급증함에 따라, 인터넷을 통한 정보 교환이 활발하게 이루어지고 있습니다. 네이버 뉴스의 댓글을 읽으며 여론을 파악하신 적이 있으신가요? 네이버 쇼핑에서 원하는 상품을 찾을때 리뷰를 확인해보신적이 있으신가요? 네이버 영화의 리뷰를 확인하며 어떤 영화를 볼지 의사결정을 한 적이 있으신가요? 이미 댓글을 읽고 정보를 파악하는 행위는 우리의 일상이 된 것 같습니다.
이처럼 댓글을 통한 정보 공유 및 파악은 일상적인 삶의 행위가 되었으나, 최근의 댓글 양상을 보면 댓글이 몇 백개, 몇 천개가 넘는 글이 다수룩하고, 댓글 중에는 중요한 정보가 아닌 스팸 혹은 여론조작성 정보 등이 포함되어 있기도 합니다. 많은 양의 댓글 중 사용자가 자체적으로 선별하여 필요한 정보를 파악하는 것이 쉽지 않은 것이지요.
저는 이러한 상황에 도움이 되고자 본 프로젝트를 진행하게되었습니다.
웹페이지소개
- 네이버 뉴스, 쇼핑몰, 영화의 url을 입력받아 해당 기사의 댓글, 쇼핑몰 후기, 영화 리뷰 정보를 다양한 기법을 토대로 분석하고 결과를 시각화하여 보여주는 웹페이지
- 뉴스 댓글, 영화와 쇼핑몰의 리뷰를 여러 시각으로 한 눈에 볼 수 있도록 함.
각 분석페이지의 일부분 캡쳐화면 첨부
기획 의도
- 인터넷상에서 많은 정보를 주고받는 현대사회에서 특히 ‘댓글’로 의견을 표출하거나 정보를 얻는 경우가 다분함. 하지만 그 양이 방대하여 모든 댓글을 읽고 적절한 정보를 취하기 쉽지 않음
- 본 프로젝트에서는 그러한 댓글 정보를 모아 분석 후, 시각화해 출력해줌으로써 편향되지 않은 적절한 정보 수용에 도움을 줄 수 있음
- 더불어 뉴스에 대한 여론, 상품에 대한 장단점 등을 한눈에 볼 수 있도록 함
작품 내용
- 인터넷 웹 서비스를 기본으로 함
- 입력받은 url의 기사, 영화, 쇼핑몰에 대하여 해당 댓글, 리뷰 정보를 수집하여 분석 결과를 웹 화면에 출력
- 악성 댓글 필터링 여부, 영화 스포일러 필터링 여부 설정
작품의 개발 배경 및 필요성
- 오늘날 대다수의 정보전달 및 소통이 인터넷을 통해 이루어지고 있고, 특히 커 뮤니티나 인터넷 기사 혹은 블로그의 댓글의 형태로 활발한 소통이 이루어진다. 이러한 댓글의 양이 급속도로 증가하면서 소통의 질도 높아졌지만, 악의적 댓글 이나 허위정보 유포, 스팸 댓글이 새로운 사회적 문제로 대두되기 시작하였다.
- 댓글 혹은 리뷰는 보통 인기 댓글(리뷰), 최신 댓글(리뷰)의 순대로 나열되기 때 문에 많은 수의 댓글 중 사용자가 선별적으로 자신에게 필요한 정보를 가지고 있는 댓글을 찾기 힘들다.
- 악의적 댓글, 스팸 댓글, 허위사실을 유포하는 댓글은 네티즌이 자체적으로 선별하여 정보를 수용하기 어렵다.
- 뉴스, 영화, 쇼핑몰의 댓글을 분석하고 분류함으로써 악의적 댓글을 예방하여 건강한 인터넷 문화를 만들 수 있으며 올바른 정보 수용에 도움을 주고자 한다.
웹페이지특장점
1) 다양한 분야에 대해 댓글, 리뷰 분석 기능 제공
- 본 프로젝트에서는 뉴스, 영화 그리고 쇼핑몰의 댓글 및 리뷰에 대해 분석을 진행한다. 뉴스 분야에서는 사회 현상이나 사건에 대한 여론을 파악할 수 있도록 분석을 진행·제공하며, 쇼핑몰 분야에서는 상품 구매에 있어 합리적인 소비를 할 수 있도록 분석하고, 영화 분야에서는 단순 별점 리뷰에서 벗어나 여러 리뷰들과 그에 따라 취향에 맞는 영화인지를 파악할 수 있도록 정보를 제공한다. 각기 다른 분야에 대해서는 사용자의 니즈(각 리뷰나 댓글에서 얻고 자 하는 정보) 를 파악하여 각기 다른 분석 기법과 시각화 기법을 사용하여 결 과를 출력한다.
2) 분석 결과 시각화
- 분석 결과를 텍스트로 단순히 보여주는 것이 아닌 다양한 차트와 그래프를 통해 한눈에 알아볼 수 있도록 시각화하여 결과를 제공한다.
3) 필터링 여부 설정을 통한 자유로운 정보 접근 기회
- 악플에 대한 필터링 여부 혹은 스포일러 포함에 대한 필터링 여부를 사용자의 설정으로 결정할 수 있도록 한다. 따라서 사용자가 수용할 정보의 범위를 자유 롭게 설정할 수 있다.
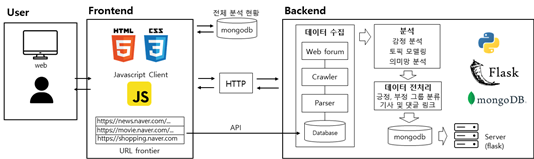
작품구성도
① 웹 초기 페이지가 실행되면 flask framework를 사용하는 backend에서 자동으 로 네이버 뉴스 전체 기사 중 댓글이 가장 많은 기사 상위 5개를 스크래이핑을 통해 기사 제목과 URL 링크를 가져오도록 request를 보내고, 그 request에 대한 response를 받아 frontend에 출력한다.
② 사용자가 분석을 원하는 URL을 입력했을 경우
②-1. 입력된 URL이 유효하지 않은 URL이거나 분석기능을 제공하지 않는 사이 트의 URL일 경우, alert 창을 띄워 오류 메시지를 출력해준다.
②-2. 입력된 URL이 유효한 url일 경우
입력된 URL을 mongodb의 url.db에 저장한다. 이때 과거에 저장되어있던 URL 정보는 drop 한다.
③ Rest API로 수집 모듈을 실행 시켜 데이터를 수집한다.
④ 수집된 데이터에 대한 분석 모듈(기술통계, 추론통계 모듈)을 실행시킨 후 실행 결과를 mongodb에 저장하며 워드클라우드의 경우 시각화 모듈을 실행시켜 데 이터를 임시 저장한다..
⑤ frontend에서 mongodb에 저장된 분석 결과 html, CSS, chart.js 등을 이용하여 시각화하며 이때 효율적인 자원관리와 편리하고 빠른 시각화를 위해 frontend는 jquery framework를 기반으로 한다.
전체 기능 목록
구분
기능
설명
현재진척도(%)
S/W
유효 URL 확인 기능
사용자가 입력한 URL이 유효한 URL인지 체크하는 기능
100%
데이터 수집 기능
유효한 URL인 경우 해당 URL을 분석하여 뉴스, 쇼핑몰, 영화인지 알아보고 각 분류에 따라 필요한 데이터 (댓글, 성별 분포, 나이 분포 등)를 수집하여 데이터베이스에 저장하는 기능
100%
주요 뉴스 랭킹 기능
실시간으로 댓글이 많은 기사 상위 5개를 출력하여 보여주는 기능
100%
데이터 분석 기능
수집된 데이터를 기준으로 논란이 많은 댓글 분석, 댓글 주요 토픽 분석, 댓글 리스트의 감성 분석 등 댓글을 분석하는 기능
100%
분석 결과 시각화 기능
분석된 정보를 서버에 보내고, 웹에서 각각 최적화된 그래프, 차트로 시각화하여 보여주는 기능
100%
악성 댓글 / 스포일러 필터링 기능
악성 댓글 / 스포일러 필터링을 설정 혹은 해제하는 기능
100%
H/W
S/W 주요 기능
기능
설명
유효 URL 확인 기능
사용자가 입력한 URL이 유효한 URL인지 혹은 분석 서비스를 지원하는 URL인지 체크한다.
데이터 수집 기능
유효한 URL인 경우 해당 URL을 분석하여 뉴스, 쇼핑몰, 영화인지 알아보고 각 분류에 따라 필요한 데이터 (댓글, 성별 분포, 나이 분포 등)를 수집하여 데이터베이스에 저장한다.
주요 뉴스 랭킹 기능
사이트를 새로 들어가거나, 새로 고침을 할 경우 실시간으로 댓글이 많은 기사 상위 5개를 가져와서 출력한다. 각 기사 제목을 클릭 시 해당 기사로 이동한다.
데이터 분석 기능
수집한 데이터를 분석한다. -뉴스 : 댓글 토픽 모델링을 통한 관련단어 분석, 댓글의 감성 분석을 통한 긍⦁부정 척도, 기술통계 (성별 분포, 나이 분포, 작성 시간분포) -영화 : 리뷰 토픽 모델링, 기술 통계 (작성 시간 분포, 리뷰 평점, 감상 포인트 등) -쇼핑몰 : 상품 주제별 리뷰 토픽 분석, 옵션 제품별 평점, 기술통계 (사용자 총 평점, 재구매율, 옵션별 구매 순위, 작성 시간 분포 등)
분석 결과 시각화 기능
분석 결과를 받아 프론트엔드에서 바차트, 파이 차트, 라인 그래프, 워드 클라우드 등의 형식으로 분석 결과를 시각화한다.
악성 댓글 필터링 기능
뉴스의 경우 악성댓글 필터링 여부를, 영화의 경우 스포일러 필터링 여부를 사용자가 설정한다.
- 분석한 전체 글, 분석한 전체 댓글을 표현해줌으로써 사용자에게 시각적 즐거움 그리고 결과 파악의 편의성을 제공해줄 수 있도록 한다.
- 실시간으로 화제인 기사들을 출력하고 해당 기사 댓글들을 모아 파악하여 실시 간 주요 토픽을 파악할 수 있도록 돕는다. 이는 사라진 실시간 검색어를 뉴스 댓글의 관점에서 일부 대체하는 기능이 될 수 있을 것으로 보인다.
주요 적용 기술
1) 웹 동작에 대한 주요 적용 기술
- Frontend
- html, CSS, javascript를 이용하여 기본 화면을 구성하였고, 깔끔한 디자인을 위해 bootstrap을 사용하였으며 시각화를 위해 html5의 오픈 소스인 chart.js와 jqbar.css를 사용하여 디자인하였다. 주요 프레임워크는 javascript와 jquery를 사 용한다
- Backend
- frontend와의 통신을 위해 googleapi인 ajax를 사용하였으며 backend framework는 flask를 이용하여 get과 post를 컴포넌트화하기 쉽게 하였다.
- Database
- 수집 데이터의 범위가 분야에 따라 상이하므로 다양한 형태의 데이터베이스 구축을 위해 nonsql 데이터베이스를 사용하였고 주요 툴로 mongodb를 이용하였 다. 또한 R코드와 파이썬 코드 간의 데이터 직접 통신이 어려운 경우 데이터베 이스를 이용하여 상호 데이터 전달이 가능하도록 한다.
- 댓글 내용, 작성 시간, 공감수, 비공감수에 대해서는 네이버에서 제공하는 뉴스 api를 사용하여 스크래이핑하였다.
- 악성댓글 필터링 해제를 설정할 경우 selenium을 사용하여 동적 크롤링을 진행하였으며, 이 경우 댓글 내용 및 다른 요소에 대한 데이터를 모두 selenium으로 수집하였다.
- 영화
- 스포일러 필터링을 해제할 경우 selenium을 사용하여 동적 크롤링을 진행하였으며, 필터링 여부와 관계없이 selenium과 beautifulsoup4를 이용하여 데이터를 수집하였다.
- 쇼핑몰
- selenium과 beautifulsoup4를 이용하여 데이터를 수집하였다.
3) 데이터 분석에 대한 주요 적용 기술
- 수집된 텍스트에 대해 텍스트 토큰화와 형태소 분석은 파이썬 모듈인 konlpy를 이용하였으며 이 데이터를 바탕으로 단어빈도 분석, 감성사전 기반 감성분석 등 의 분석 전반은 R을 사용하였다. 또한 python과 R언어를 연동하여 사용하기 위 해 rpy2 모듈을 이용하였다.
- 토픽모델링 알고리즘 중 하나인 LDA 모델을 이용하여 토픽 모델링을 하였으며 LDA 모델은 DTM (문서 단어 행렬)을 이용하여 만들었다. 사용 LDA 모델은 샘 플링 방식을 gibbs 방식을 차용하였으며 토픽은 5개로 나누었다. 토픽의 개수는 여러 뉴스에 대한 댓글 데이터를 반복 학습시켜 가장 토픽을 잘 나눌 수 있는 적정 개수를 채택하였다.
- 긍부정 여론을 분석하기 위해 감성 사전을 이용한 감정 분석을 진행하였으며 감정을 긍정, 부정, 중립으로 나눠 감정 점수를 부여하여 긍부정 여부를 판단하 였다. 이와 더불어 LSTM, Convolution을 이용하여 긍부정 단어를 학습시키고 분 석 텍스트를 predict 하여 나온 결과를 가중치로 더하여 결과를 도출하였다.
- 본 프로젝트에서는 실제 사용자가 웹서비스를 사용할 때, 어떻게 하면 보다 유 익한 정보를 서비스할 수 있을지에 대한 많이 고민하였다. 이에 초기에 계획하 였던 네이버 뉴스 URL에서 확장해, 네이버 쇼핑/네이버 뉴스/네이버 영화 후기 URL까지 포괄하는 프로그램을 개발하였으며, 각 분류 (뉴스, 쇼핑몰, 영화)에 따라 다른 분석결과를 제공하며 따라서 각각의 분석결과를 보기 쉽게 출력하기 위해 다른 디자인의 ui를 만들었다.
- 각 URL의 입력 시, 모두 동일한 분석이 진행되는 것이 아니라 각 주제에 적합 한 분석 기법이 적용되도록 하였고, 제공되는 기본 통계 정보 또한 각 페이지에 최적화된 통계를 제공할 수 있도록 세분화하였다. 사용자의 본 프로그램 사용 의도 에 따라 네이버 영화에서는 스포일러 차단 후 분석, 뉴스에서는 악성 댓글 차단 후 분석 기능을 제공함으로써 사용자로 하여금 선택의 폭을 넓혔다.
- 간단하고 깔끔한 UI와 인터페이스로 누구든 쉽게 사용할 수 있게 만들었으며, 추후 주기적으로 기존 분석 기능의 보완 및 분석 기능의 추가가 이루어질 예정 이다.
페이지소개-메인페이지
메인페이지에서는 사용자가 분석하고자하는 글의 url을 입력받습니다. 입력된 url의 플랫폼을 확인하여, 각 플랫폼 전용 분석 페이지로 이동합니다.
또한 메인페이지에서는 실시간화제토픽, 핫이슈기사, 제 웹페이지가 지금까지 분석한 전체 글, 전체 댓글의 정보를 제공합니다. 그 외에 오류 신고나 도움말을 볼 수 있으며, 설정창에서 클린봇을 활성화할지 스포일러를 포함할지 등의 여부를 on/off 할 수 있습니다.
페이지소개-뉴스페이지[분석]
뉴스 전용 페이지는 성별분포, 나이분포그래프, 평점 기반이 아닌 내용 기반의 모든 댓글의 감정 분석, 긍정과 부정의 각 감정을 나타낼때의 주요한 토픽 추출, 모든 댓글의 주요 토픽 분석,
논란이 일어나는 댓글, 댓글 작성시간분포 그래프, 워드 클라우드를 보여줍니다.
논란이 일어나는 댓글의 경우 댓글의 공감과 비공감수를 크롤링하여 그 비율을 보는것으로 판단하며, 논란 댓글이라 판단된 것 중 대댓글이 많은 순으로 화면에 출력됩니다.
페이지소개-쇼핑페이지[분석]
쇼핑몰 페이지의 경우 총 리뷰 갯수, 사용자 총 평점, 재구매율, 각 토픽별 평점, 각 제품/옵션별 평점 등을 제공합니다. 이때 재구매율은 네이버가 인증한 '재구매' 팻말이 붙은 댓글의 수를 기준으로 합니다.
각 토픽별 평점이란 상품 구매시 영향을 끼친 주요 '토픽'을 확인하고, 해당 토픽에 대한 평점을 재계산하는것이며, 토픽 분석시에는 각 토픽의 사용자 반응을 형용사형으로 추출해 주요 반응을 보여줍니다.
예를들어 화장품 제품의 댓글을 분석한 본 예시에서의 토픽은 트러블개선, 만족도, 가격, 분사력, 등이며 사용자의 반응은 좋다, 만족하다, 작다, 촉촉하다 등으로 분석이 되었습니다. 그 외에도 제품/옵션별 구매순위, 댓글작성시간 분포그래프, 워드클라우드 등을 제공합니다.
페이지소개-영화페이지[분석]
네티즌평점, 성별/나이별관람추이, 만족도 등을 제공합니다. 시간관계상 생략하도록 하겠습니다.
이하 분석 기법에 대한 설명은 영상에서 확인부탁드립니다.
활용방안
1) 사용자들이 필요한 정보만을 선별적으로 수용하여 정보 과다 사회에서 효율적인 정보 접근이 가능
2-1) 뉴스 댓글 분석 : 주요 이슈에 대한 여론을 다양한 측면에서 빠르게 확인 가능
2-2) 쇼핑 댓글 분석 : 구매자는 상품에 대한 다양한 토픽별 반응(착용감, 등) 등을 확인할 수 있으며,
판매자는 고객 반응을 확인해 마케팅에 활용
2-3) 영화 댓글 분석 : 해당 영화에 대한 여론을 파악하여 시청 결정에 도움을 줌
3) 특정 분야에 대한 소비자의 감성 변화에 따른 마케팅 등 다른 데이터와 연계하여 다양한 분석 수행 가능
뇌파 감정분석 기반 인공지능 음악 치료 (AI music therapy based on EEG Emotional Analysis)
1. 과제 개요 가. 과제 선정 배경 및 필요성 1) 정신 재활은 정신 질환을 앓고 있는 환자들이 치료를 받고 사회로 복귀하는 데 있어 필수 적인 과정이며, 암 환자 등 정신 질환과 직접적인 관련이 없는 환자들에게도 삶에 대한 의지를 찾고, 치료에 적극적으로 참여하도록 격려하는 매우 중요한 과정이다. 정신 재활의 방법 중, 음악 치료는 단순한 음악 감상이 아니라 음악을 매개로 하는 적극적인 심리 치료로서 음악 치료사가 치료 대상자의 상태를 확인하고, 심리적, 신체적, 정신적 상태를 향상시킬 목적으로 음악을 사용하는 치료 방법이다. 우리는 이러한 기존의 치료 방법론이 모두 ‘음악 치료사’ 개인의 판단 하에 이루어진다는 것, 한 번의 진단으로 이후의 모든 치료 계획이 결정된다는 점에 주목했다. 2) 우리는 새로운 정신 재활 음악 치료의 방법으로 ‘온전한 사용자 맞춤형 음악치료’를 제안한다. 기존에 타인의 평가에 맡기던 음악 치료의 방법에서 벗어나, 우리는 환자 개개인의 뇌파를 통해 환자의 감정을 실시간으로 분석하고, AI 인공지능 작곡 모듈을 이용해 환자의 감정 및 상황에 맞는 사용자 맞춤형 음악을 제공할 것이다. 이를 통해 환자는 과거 진단에 대한 치료보다 현재 진단에 대한 치료를 받을 수 있게 되며, 온전한 자신의 치료를 받을 수 있게 된다. 나. 과제 주요 내용 1) EEG Dataset( DEAP, AMIGOS, SEED 등 )을 수집한다. 2) 수집한 데이터를 여러 ML, DL 모델을 이용하여 환자의 감정을 분류한다. 3) 특정한 감정 상태에서 어떠한 유형의 음악으로 치료가 가능한 지 조사한다. 4) 기존 음악의 특징 요소(템포, 역동성 등)를 분석하여 감성 유형을 분류하고 3)의 결과를 바탕으로 감정 제어를 위한 음악을 작곡한다.
2. 과제의 목표 가. 최종결과물의 목표 (정량적/정성적 목표를 정하되, 가능한한 정량적 목표로 설정) 1) Data set에 있는 subject들의 감정을 75% 이상의 정확도로 구분. 2) 환자의 감정을 효과적으로 치료할 수 있는 음악 작곡 모델 개발. 3) 2)의 결과로 작곡한 음악이 실제 환자에게 도움이 되는지 판단.
나. 최종결과물의 세부 내용 및 구성 1) EEG Data Set으로 학습한 감정 분류 모델 2) EEG Data Set으로 학습한 감정 분류 모델의 정확도 3) 환자의 감정 치료에 사용되는 음악 작곡 모델 4) 환자의 감정 치료 목적으로 작곡된 음악 5) 작곡한 음악을 들은 후의 EEG 데이터
3. 기대효과 및 활용방안 뇌파 측정기를 통해 환자의 뇌파를 분석하고, 환자의 감정을 판단하여 환자의 상태에 최적화된 음악을 제공한다. 환자는 실시간 진단을 통한 개인 맞춤형 음악 치료 활동에 참여하여 성공적인 음악 경험을 하게 되고, 자신의 감정을 확인하고 표현하며 자신의 행동을 조정하고 변형할 수 있게 된다. 또한, 정신 질환을 가지지 않은 환자들에게도 심리적 안정감을 제공하여 환자가 치료 및 삶의 의지를 가질 수 있도록 도움을 줄 수 있다. 이 외에도 무의식 환자의 뇌파가 일반인과 유사하며, 청각은 무의식 중 자극을 받아들일 수 있는 감각기관이라는 점을 이용하여, 뇌 손상으로 의식이 없는 환자에게도 청각 자극을 통해 의식 각성에 도움을 주는 것도 기대해 볼 수 있다.
4. 수행 방법 가. 과제수행을 위한 도구적 방법 (활용 장비, 조사 방법론 등) 1) 뇌파를 통한 감정 분석 뇌파를 이용해 감정을 분류한 다양한 논문을 읽고, DEAP, SEED-IV 등의 Data set을 이용해 효율적인 감정분석을 위한 딥러닝 네트워크 개발 2) 인공지능 기반 음악 작곡 시중에 나와 있는 다양한 음악의 감성을 Mirtoolbox, ABC notation 등의 도구를 활용해 분석하고, 뇌파를 이용해 분석한 환자의 감정을 기반으로 이를 효과적으로 제어할 수 있는 감성을 가진 음 악을 JukeBox, pybrain 등의 라이브러리를 활용하여 작곡한다.
나. 과제수행 계획 1) 뇌파를 통한 감정분석 가) EEG 데이터 셋(DEAP, AMIGOSM, SEED 등)을 수집한다. 나) EEG 데이터를 이용한 감정분석 방법을 다양한 논문을 읽으면서 습득한다. 다) EEG 데이터 기반으로 효율적인 감정분석을 위한 딥러닝 네트워크에 대해 연구한다.
2) 음악의 감성 분류 가) 다양한 장르의 음악 데이터 셋(kaggle의 ABCnotation 등)을 수집한다. 나) 각각의 음악의 감성을 분류한다.
3) 1)에서 분석한 환자의 감정을 어떤 음악의 감성으로 제어할 수 있을지에 대해 조사한다. 4) 3)에서 조사한 내용과 2)에서 감성을 기준으로 분류한 음악을 기반으로 인공지능 음악 작곡 모델 을 학습시키고, 학습시킨 모델을 바탕으로 새로운 음악을 작곡한다. 5) 4)에서 작곡한 음악을 바탕으로 정신적 치료에 효과가 있는지 확인한다.
5. 추진일정
순번
추진내용
9월
10월
11월
12월
비고
1
Data Set 수집
O
2
EEG, 인공지능 작곡 알고리즘 관련 논문 리뷰
O
3
EEG Data Set을 통한 감정 분석 및 평가
O
O
4
환자의 정신 재활에 도움이 되는 음악 유형 연구
O
O
O
5
기존 음악의 특징 요소 분석
O
O
6
AI 작곡 알고리즘에 분석 결과 적용
O
O
7
실제 효과 확인 및 평가
O
O
8
보고서 작성
O
---> 그러나, 모델 평가를 위한 과정에서의 IRB 승인문제, 평가용 Dataset 수집을 위한 뇌파 탐지기 구매의 가용한 예산과 성능(채널 수)문제, 조사 결과 기존 주제와 흡사한 최신 논문의 발견 문제, 자신의 뇌파로 만든 음악을 듣고 개개인마다/상황에따라 니즈가 다른데 정말 '치료적인'목적이 달성될 수 있는가, '심리적 안정성'이 목표라면 스스로 노래를 듣거나 아무 클래식 음악을 틀어줘도 괜찮은 것이 아닌가 등등의 고민으로,
본 계획서의 주제와 세부 목표들을 대폭 수정하였다. (위에 올린건 수정 전 주제, 계획서)
최근 뇌의 각종 신호 데이터를 해독해 응용하는데 관심이 많이 생겨서 관련 논문을 3개 정도 찾아보았다. 특히 무의식 환자, 일상적 표현이 불가능한 중환자의 의사표현을 돕는데 관심이 생긴다. (무의식 환자 중 일부 환자는 깨어나지 못할 뿐, 뇌파 반응이 정상인과 유사하게 반응한다고 한다.)
사실 학부연구 주제도 이 분야로 하고싶다.. (내가 생각해둔 주제는 이 분야지만, 교수님께서 다른 분야를 추천해주실 수 있기 때문에 확정이 나지 않았다)
BCI 분야는 IT대기업들이 관심을 갖고 한창 연구가 진행중이며 그 성과가 점차 드러나고 있는 유망한 분야이다. 학부생 개인이 연구할 수 있는 주제는 여러 여건상 제한적이기 때문에 지금은 상대적으로 작은 프로젝트밖에 하지 못하겠지만, 추후 관련 분야를 연구하는 기업에 입사해 나도 연구에 참여할 수 있다면 좋을 것 같다.
(논문1) Real-time decoding of question-and-answer speech dialogue using human cortical activity
간략히 설명 : 사전 녹음된 질문 세트를 피실험자에게 들려주고 피실험자는 구두로 답변한다. 이 모든 과정은 EcoG를 사용해 뇌가 어떻게 활동하는 중인지 기록되고 있다. 이렇게 얻은 데이터셋은 음성 감지 및 디코딩 모델을 훈련하기 위한 입력으로 사용되며, 신경 신호를 사용해 참가자가 듣거나 말할때를 감지하고, 뇌파 속에서 어떤 대화가 진행되고 있는지 개연성을 파악한다. 학습된 모델 및 신경 신호를 통해, 환자가 듣는 내용을 61%까지, 환자가 답변하는 내용을 76%까지 정확히 문장으로 해독해냈다고 한다.
(논문2) Towards reconstructing intelligible speech from the human auditory cortex
간략히 설명 : 간질을 앓고있는 환자들의 뇌에 전극을 삽입해, 피험자들이 귀로 듣고있는 내용에 대한 신경 신호를 인공지능 음성인식 소프트웨어가 학습한다. 피험자들은 0부터9의 숫자까지 40차례 들었으며, 인공지능은 청각 피질에서 기록된 신경 반응을 인지해 어떤 숫자인지 알아내 음성으로 재구성한다. 이 모델은75%의 정확도를 보인다.
(논문3) Speech synthesis from neural decoding of spoken sentences
간략히 설명 : 신경 활동에서 음성을 해독하는 것은 어려우니, 가청 음성을 합성하기 위해 인간의 피질 활동에 인코딩된 운동학적 소리표현 신호를 명시적으로 활용하는 신경 디코더를 설계하는 내용이다. 피질 신호를 관절 운동의 표현으로 디코딩한다음, 이러한 표현을 종합하여 음성 음향으로 변환한다.
TEXT 형태의 데이터로 저장이 되면, 전처리 과정에 들어감. (곡에 있는 모든 음은 사전 형태로 매핑됨)
이를 입력 데이터로 사용하기 위해 벡터화함 (원핫인코딩)
LSTM으로 학습 진행, 입력 데이터의 갯수 6개씩. (너무작으면오류,너무길면예측제대로안됨)
6개로 이루어진 하나의 데이터와, 이 데이터의 다음에 오는 하나의 데이터를 타겟으로하여 학습이 진행됨.
한 스텝씩 밀리면서 모든 데이터셋에 대한 학습과정 반복.
ModelSaving에서,생성된 모델을 사용자가 초기에 설정한 임의의 곡 분위기별로 저장.
의의:
본 논문은 ABC Notation을 분위기별로 분류하여 딥러닝으로 학습하고 여기서 만들어진 모델을 통해 기존에 없던 새로운 음악을 사용자가 이용할 수 있다. 이 사용자들은 음악적 지식 없이 작곡할 수 있 고 인공지능으로 작곡을 했기 때문에 기존의 작곡가 가 만드는 곡보다 시간·경제적인 소요를 줄일 수 있 다.
챌린지한 부분이 될 수 있다고 생각하는 부분은 2와 3번. 1번의 경우, 위처럼 EEG 데이터를 통한 감정 분류를 위한 다양한 논문이 이미 나와 있기 때문에 논문을 재현하는 방식으로 공부와 연구를 진행하면 크게 어렵진 않을 것 같음. 다만, 2와 3번의 경우, 의학과 화성학에 대한 전문적인 지식이 없기 때문에 공부와 연구를 진행하면 다소 시간이 많이 걸릴 것으로 예상됨.
DEAP 데이터 세트 : 인간의 감정 상태 분석을 위한 다중 모드 데이터 세트. 32명의 참가자의 뇌파(EEG)와 말초 생리학적 신호는 각각 1분 길이의 뮤직 비디오 발췌문 40개를 시청할 때 기록. 참가자들은 각성, 관심도, 좋아함/싫어함, 지배력 및 친숙도의 측면에서 각 비디오를 평가.
간질 데이터 : 난치성 국소 간질 21명의 환자에 대한 EEG 기록을 포함. 수술 전 간질을 모니터링하는 동안 기록. "ictal" : 간질 발작이 있는 파일과 발작 전 최소 50분 데이터가 포함 "interictal" : 발작 활동이 없는 약 24시간의 EEG 기록을 포함
DEAP Dataset을 활용한 뇌파 데이터 분석 방법에 관한 연구논문 분석
DEAP
이 논문에서는 오픈 감정뇌파데이터인 DEAP Dataset을 활용. DEAP Dataset는 총 23개의 데이터, 32 채널로 구성. 남, 여 각각 16명. 총 32명의 사용자에게서 40편의 비디오를 시청한 뒤 감정상태를 기록. 레코딩 된 신호는 총 32개의 채널과 512Hz로 샘플링
전처리 과정 :
디지털 필터인 IIR(Infinite Impulse Response) Filter를 사용하여 잡음 제거
Artifact인 안구잡파(EOG : Electrooculograms, 눈 깜빡임) 제거 : LMS(the Least Mean Sqaures) 알고리즘을 사용
(LMS → 비정상적인 생체신호를 제거하는 데에 유용)
감정 분류 : Valence-Arousal 평면을 사용하여 4개의 감정으로 구분. 분류 알고리즘으로는 Support Vector Machine을 사용.
LAHV(두려움), HAHV(행복), LALV(슬픔), HALV(고요)
뇌파의 분류
복잡하게 진동하는 형태. 저마다의 전위값이 다르다.
뇌파 관찰 시 → 주파수의 범위와 전압 값에 따라 인위적으로
Delta파 : 0.1 - 3Hz; 20-200uV
Theta파 : 4-7Hz; 20-100uV
Alpha파 : 8-12Hz; 20-60uV
Beta파 : 13-30Hz; 2-20uV
Gamma파 : 30-50Hz
전처리가 끝나 잡음이 제거된 신호는 FFT 분석을 시행하여 주파수대 별로 Power Spectrum 분석을 하여 특징 추출을 하였다.
퓨리에 변환
위의 논문에서는 FFT(Fast Fourier Transform), 빠른 퓨리에 변환 사용. 빠른 Fourier 변환(FFT)은 오디오 및 음향 측정 과학 분야에서 중요한 측정 방법 . 신호를 개별 스펙트럼 구성 요소로 변환하여 신호에 대한 주파수 정보를 제공. FFT는 기계 또는 시스템의 결함 분석, 품질 관리 및 상태 모니터링에 사용. (출처 :https://www.nti-audio.com/ko/지-원/know-how/빠른-fourier-변환-fft)
변환한 주파수 범위에 따라 Theta(4-7Hz), Alpha(8-12Hz), Beta(13-30Hz), Gamma(30-40Hz)로 분석. FFT분석은 Matlba을 사용. FFT를 통한 각각의 주파수 대역별 값은 배열로 저장 분석 (Fourier 변환이 중요한 개념으로 사용되는 듯)
MNE-Python (http://martinos.org) 기능적 신경 영상 데이터(functional neuroimaging data) → EEG, MEG, sEEG, ECoG, and fNIRS 데이터들을 처리, 분석 및 시각화를 위한 오픈소스 Python 모듈.
해당 모듈을 이용하여 EEG 데이터와 MEG데이터를 분석할 수 있다. (MEG 데이터의 경우, EEG는 전기적 신호인 반면, MEG는 자기적 신호로 수집한 뇌파 데이터를 의미한다. 해당 데이터셋이 EEG데이터보다 Noise가 더 적으므로, 만약 두 데이터를 통해서 분석할 수 있는 대상이 비슷하다면, MEG 데이터를 이용하는 것도 좋은 방법일 듯 싶다.)