
| 요 약 본 |
| 작품 정보 | ||
| 프로젝트명 | 국문 | 빅데이터를 이용한 주식 가격 예측 시스템 만들기 |
| 영문 | Stock prediction program using big data | |
| 작품 소개 | - 빅데이터 처리기술과 인공지능 기술을 이용하여 주가를 예측 및 분석하는 시스템 대신증권 open API 데이터를 이용하여 시가총액, 영업이익률, 환산 주가, 외국인 보유 비율, 오늘의 유망주(거래량, PER) 상위 10위를 출력한다. 종목의 이름 혹은 코드를 입력하면 미리 구현된 모델에 input되어 주가를 예측해 출력한다. 해당 종목의 시가총액, 영업이익률 등 투자정보와 종가그래프를 출력한다. |
|
| 작품 구성도 |
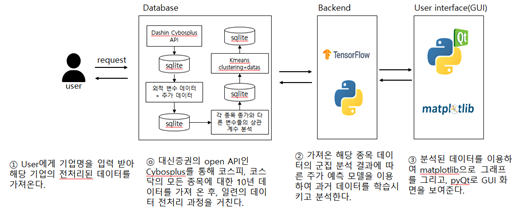 |
|
| 작품의 개발배경 및 필요성 |
기술적 분석, 기본적 분석, 데이터 분석, 통계 기반 분석 등 주식 가격을 예측하려는 움직임은 꾸준히 있었지만 예측의 정확도는 크게 높지 않았다. 최근의 인공지능 기술은 알고리즘의 개선, 빅데이터 처리기술의 발달, 하드웨어의 발달로 매우 빠른 속도로 발전하고 있다. 이에 본 프로젝트에서는 발전한 인공신경망 알고리즘과 최신 ICT 기술을 이용하여 주가를 예측하고, 최적의 수익 창출 알고리즘을 찾아 예측의 정확도를 보다 높이려 한다. | |
| 작품의 특장점 |
오늘의 유망주, 시가총액 등의 다양한 지표에 대한 상위 종목을 참고할 수 있어 매매/매도시 더 신중할 수 있다. 전 종목의 상관 관계분석 및 군집분석을 적용한 종가 데이터의 세분화, 각 군집에 최적화되어있는 각 모델, 체계적인 알고리즘으로 더 정확한 예측값을 출력할 수 있다. | |
| 작품 기능 |
- 최적의 주식 매매, 매도 시점 포착을 위한 데이터 분석 결과 출력 - 항목별 상위 10위 종목을 제시하여 희망하는 항목에 대한 직관적인 지표 제공 원하는 종목의 기대 주가 및 추가 투자정보 제공 - 실제 주가 데이터와 예측 데이터 간의 차이 분석 및 제시 |
|
| 작품의 기대효과 및 활용분야 | - 사용자가 가장 집중적으로 보는 상위 기업 지표, 각 종목의 투자정보와 더불어 주가예측 서비스를 도입하여 매매전략 수립에 여러 시각의 도움을 줄 수 있다. 종목을 군집화하고 각 군집에 최적화된 예측모델을 만들어, 타 주가 예측 프로그램보다 더 높은 예측 정확성을 기대할 수 있다. - 주식 매매 서비스 : 객관적 지표 외에 사용자가 선택적으로 열람할 수 있는 추가적인 정보로 주가예측 결과를 보여줄 수 있다. |
|
| 본 문 |
I. 작품 개요
1. 작품 소개
1) 기획의도
- 주식 시장의 수치화된 정보, 지표를 분석하는 알고리즘을 설계, 구현하고 정보를 빅데이터 처리기술과 인공지능 기술을 이용해 주식가격 예측시스템을 구현한다.
- 지표들을 분석할 수 있게 설계한 알고리즘들을 실제로 테스트하고 성능을 비교 하여 최적의 알고리즘을 채택하여 적용한다.
- 분석한 주식가격정보를 쉽게 알아볼 수 있는 서버를 구축하여 사용자의 접근성 을 높인다.
2) 작품 내용
- 대신증권 open API를 통해 전 종목의 10년치 시가, 고가, 저가, 종가, 거래량, 시가총액, 외국인보유비율, 기관거래량, 코스피지수, 코스닥지수, MSCI, 다우존스지수, 나스닥, 항셍지수 데이터를 수집하고, SQLite를 이용해 DB를 구축한다.
- 종가 데이터에 대한 각 항목의 데이터를 상관관계 분석하고, 군집분석을 통해 종 가에 영향을 끼치는 요소가 비슷한 종목끼리 묶어 학습 데이터로 넣는다.
나눠진 5개의 군집에 대한 5개의 모델을 수립한다. 각 모델의 input data로는 군집 내 모든 종목에 대한 항목별 상관계수 평균이 일정값 이상인 항목만을 input 데이터로 선택한다.
군집 별 input데이터를 선정하고, 데이터 전처리 – Tensorflow를 이용한 예측 모델 구현을 거쳐 주식 가격을 예측한다. 각 군집 별 최적의 알고리즘을 찾아 정확도를 높인다.
PyQt를 이용해 GUI 프로그램을 개발해‘내일의 주식’프로그램을 만든다.
‘내일의 주식’프로그램에 다양한 항목에 대한 상위 10위의 항목을 출력하고, 분석을 원하는 종목의 이름/코드를 입력시 예상 주식 가격 및 기본적인 투자정보를 제공한다.
3) 정의
- 시가총액, 영업이익률, 환산주가, 외국인 한도 소진율, 오늘의 유망주(거래량, PER 기준)에 대한 상위 10위 종목을 보여주어 사용자가 쉽게 유용한 정보를 얻을 수 있다.
- 기업명 혹은 기업코드를 입력했을 때 주가(종가) 그래프 및 예측된 주식 가격을 포함해 해당 종목의 거래량, 시가총액, 외국인 소진율, 환산주가, 영업이익률, PER 등의 투자 지표를 출력해주어 원하는 종목에 대한 다양한 투자정보를 얻을 수 있다.
2. 작품의 개발 배경 및 필요성
1) 작품 제작 동기
- 코로나로 인해 주식 시장이 위축되어있는만큼, 지금 우리에게는 다양한 변수 기반 분석과 신뢰할 수 있는 참고 지표가 필요하다.
- 인공지능의 강점은 방대한 데이터 세트 내 상관관계를 파악하는 능력이다. 이러한 상관관계는 시스템적 위험의 모니터링에 유용할 수 있다.
- 현재 4차산업혁명의 핵심기술인 빅데이터와 인공지능기술이 급격히 발전되었기 때문에, 이를 활용해 보다 발전된 알고리즘을 구현할 수 있다.
2) 작품 제작 목적
- 발전된 알고리즘을 이용한 예측 모델링을 통해 보다 정확한 예측결과를 얻을 수 있도록 한다.
- 투자자가 주목하는 여러 항목에 대한 상위 10위 종목 및 사용자가 분석을 원하는 종목에 대한 주가 그래프, 예측 주가, 그 외 여러 투자 정보들을 제공해 사용자가 더욱 쉽게 정보를 얻을 수 있도록 한다.
3. 작품의 특징 및 장점
1) 특징
- 단순히 예측모델만을 만드는 것이 아니라, 상관 관계분석-군집분석-군집별 예측 모델 수립을 통해 학습 데이터와 알고리즘을 최적화 함으로써 정확도를 높일 수 있다.
- CNN, LSTM, DNN 등의 알고리즘을 복합적으로 활용하며 모델을 개선시켜 예측 의 정확도를 높일 수 있다. 데이터 전처리, Early stopping, Model checkpoint 등 의 기법을 활용해 과적합을 피하고 가장 좋은 효과를 내는 모델을 얻을 수 있다.
- 단순하면서 깔끔한 UI의 PyQT 툴을 이용하여 프로그램을 만들고 필요한 정보만을 보여줌으로써 사용자의 접근성을 높여준다
II. 작품 내용
1. 작품 구성도
1) 서비스 구성도

2) 기능 흐름도

2. 작품 기능
1) 전체 기능 목록
| 구분 | 기능 | 설명 | 현재진척도(%) |
| S/W | 데이터 수집 기능 | 대신증권 api(CybosPlus)를 이용해 KOSPI, KOSDAQ 전 종목의 주가 데이터를 수집한다. | 100% |
| 실시간 주가 정보 조회 | 실시간 주식 데이터를 가져와서 시시각각 동향을 출력하여 사용자에게 제공한다. | 100% | |
| 항목별 상위 10위 제공 | 시가총액, 오늘의 유망주(거래량, PER 기준), 영업이익률, 환산주가, 외국인 한도 소진율에 대한 상위 10위 종목들을 한눈에 볼 수 있도록 한다. | 100% | |
| 주식 가격 예측 및 투자정보 제공 | 종목명/종목코드를 사용자에게 입력받은 후 해당 종목의 분류를 확인하여, 각 군집에 해당하는 모델에 input해 주가를 예측한다. 해당 종목의 주가 그래프 및 세부 투자정보를 추가 제공한다. - 완성 가능 시점 : 10월 30일 예상 |
40% | |
| 데이터 업데이트 및 모델 개선/평가 | 수집한 데이터 및 예측한 데이터를 저장해 모델의 정확도를 평가하고, 모델을 개선한다. 완성 가능 시점 : 10월 10일 예상 |
40% |
2) S/W 주요 기능
| 기능 | 설명 | 작품실물사진 |
| 주요 항목에 대한 투자정보 제공 | - 항목별 상위 10위의 종목을 제시하여 희망하는 항목에 대한 직관적인 지표를 제공함. 거레량, PER 지표를 활용 분석해 ‘오늘의 유망주’를 제공하는 등 투자 지표를 활용하여 제공함. |
 |
| 주가 예측 및 세부 투자정보 제공 | - DNN, CNN, LSTM 등 다양한 알고리즘을 이용해 주가를 예측하고, 각 알고리즘의 정확도를 비교하여 가장 적합한 알고리즘을 채택함. - 예측된 주식 가격을 출력하고, 해당 종목의 추가적인 투자정보와 그래프를 제공하여 사용자의 의사결정을 도움. |
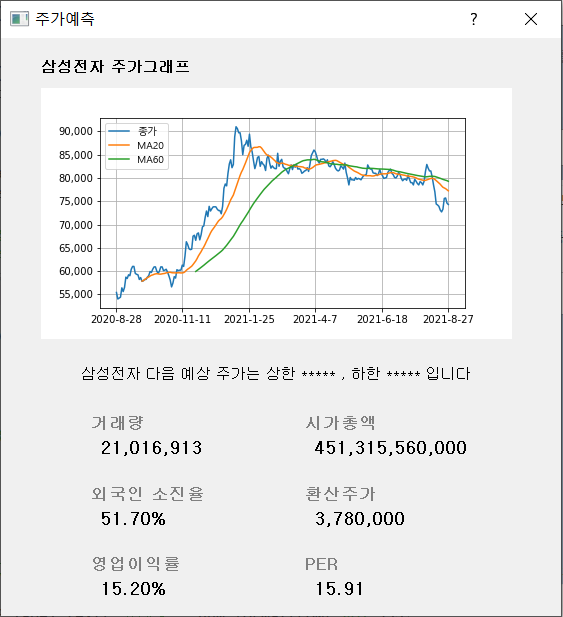 |
3. 주요 적용 기술
- 과거 내부 변수 데이터 수집 : 대신증권 Cybosplus API를 이용하여 모든 종목의 과거 10년 데이터 수집(시가, 고가, 저가, 종가, 거래량, 시가총액, 외국인보유비율, 기관거래량)
- 과거 외적 변수 데이터 수집 : Investing.com과 대신증권 API를 이용하여 모든 종목의 과거 외적 변수 10년 데이터 수집(코스피지수, 코스닥지수, MSCI, 다우존스지수, 나스닥, 항셍지수, 금리)
- 상관계수 (Correlation coefficient) 분석 : 수집한 주가 데이터와 외적변수 데이터를 바탕으로 ‘종가’에 대한 각 변수 데이터의 상관관계 분석 (pearson 상관계수 분석, kendall 상관계수 분석, spearman 상관계수 분석을 모두 진행하여 비교 분석)
- 군집(Clustering) 분석 : KMeans clustering을 이용하여 영향을 끼치는 상관계수 별 군집화 (해당 종목에 영향을 끼치는 상관계수 분류), KMeans clustering 및 시계열 군집 분석을 이용하여 상관계수 수치 동향 군집화 (군집 결과에 따라 각기 다른 주가 예측모델 도입) scikit learn과 tslearn을 사용하여 KMeans clustering을 진행한다.
- 주가 예측 모델 {
∘데이터 노이즈 제거 : 전처리된 데이터를 Christian-Fitzgerald Band Pass Filter (이하 cf 필터를 이용하여 노이즈를 제거한 후, 주가 데이터를 3차원 shape으로 변환하여 CNN 모델에 입력하여 노이즈를 재차 제거
∘주가 예측 모델 : 양방향 LSTM 모델, GRU 모델을 이용하여 앞서 노이즈를 제거한 과거 주가데이터와 상관관계가 높은 외적변수 데이터를 함께 학습시킨다. (학습 과정에서의 과적합을 피하기 위해 dropout과 dense를 이용한다.)이때 파라미터는 앞서 분류한 각 군집에 대해 최적화된 파라미터를 사용한다.
∘모든 예측 모델은 tensorflow와 scikit-learn의 모듈을 이용한다. }
4. 작품 개발 환경
| 구분 | 상세내용 | ||
| S/W 개발환경 |
OS | Windows | |
| 개발환경(IDE) | Anaconda Sypder5 및 Pycharm | ||
| 개발도구 | python 3.9.6, QT designer | ||
| 개발언어 | Python | ||
| 기타사항 | open API를 통한 데이터 수집 (python 3.7 32bits), 데이터 전처리 및 예측모델 개발 (python 3.8 64bits) | ||
| 프로젝트 관리환경 |
형상관리 | GitLab | |
| 의사소통관리 | GitLab, 카카오톡, Google meeting, 오프라인 미팅 | ||
| 기타사항 | 코로나 19에 따라 오프라인 미팅이 불가할때는 Google meet로 온라인 미팅 진행 | ||
5. 기타 사항 [본문에서 표현되지 못한 작품의 가치(Value)] 및 제작 노력
- 상관계수분석을 통해 각 종목에 과거 주가 데이터의 동향과 상관관계가 짙은 내적, 외적 변수를 파악하여 학습시킬 데이터셋을 각 종목마다 다르게 설정하고, 상관관계 동향에 따른 군집분석을 통해 다른 예측 알고리즘 모델로 해당 데이터를 학습시킴으로써 각 종목에 최적화된 예측을 하도록 한다.
- 상관계수 분석과 군집 분석은 최적화된 예측을 할 수 있도록 할 뿐만 아니라, 주가 동향이 비슷한 종목을 구분하고 그 상관관계를 알아볼 수 있다는 점에서 가치를 지니고 있다.
- 사용자의 매매전략에 도움을 주기 위해 주가 예측값을 비롯하여 대박주, 환산주가, 시가총액 등 여러 항목에 대한 상위 기업을 제공하고 검색한 기업에 대한 추가 투자정보를 제공한다. 이를 통해 사용자는 편리하게 다양한 정보를 접하여 매매전략을 세울 수 있게 된다.
III. 프로젝트 수행 내용
1. 프로젝트 추진 과정에서의 문제점 및 해결방안
1) 프로젝트 관리 측면
- 데이터베이스 관리 : 주식 데이터 용량의 문제로 데이터베이스 공유 및 공동 관리에 문제가 있었다. 이를 해결하기 위해 gitlab을 통해 코드를 공유하고 온라인 피드백을 통해 각자의 테스트 데이터베이스를 다듬을 수 있었다.
- 오프라인 미팅 제한 : 코로나19 상황으로 오프라인 미팅에 제약이 있었다. 카카오톡 채팅방을 통한 활발한 소통과 매주 온라인 화상 회의를 진행하여 진행상황을 공유하여 오프라인 미팅의 한계점을 극복하였다.
2) 작품 개발 측면
- 분석 모델의 한계 : 약 3000개의 종목에 대해 같은 분석 및 주가 예측 모델을 사용하니 training set과 test set의 설정에 따라 예측결과가 상이하게 도출되었다. 이를 해결하기 위해 training attribute 간의 상관계수를 분석하고 이를 토대로 군집화하여 군집에 따라 각기 다른 분석 모델을 사용하여 예측의 정확성을 높혔다.
- 다차원 데이터의 군집화 : 일반적인 군집분석의 방법인 KMeans clustering을 사용하여 데이터를 군집화하니 다차원 데이터의 군집화가 잘 이루어지지 않았다. 이를 해결하기 위해 시계열 군집화를 사용하여 다차원 데이터를 그래프화 시켜 군집화를 진행하였다.
- 과거 데이터 노이즈 문제 : 과거 10년의 종가 데이터를 학습시키는 과정에서 노이즈로 인한 후행성 문제가 발생하여 예측의 정확도가 떨어지는 결과를 가져오게 되었다. 이를 해결하기 위해 데이터 전처리 과정에서 CF filter를 사용하여 노이즈를 제거하였다.
- 수집 데이터 한계 : Dashin Cybosplus Open API를 이용하여 과거 주가데이터의 방대한 양을 수집하는 것에는 request의 한계가 있었다. 일반적인 종목의 주식 변동 주기를 기준으로 과거 10년의 데이터를 가져오도록 하였다.
2. 프로젝트를 통해 배우거나 느낀 점
- 방대한 양의 데이터를 수집 및 관리하고 전처리하는 과정에서 빅데이터를 효율적으로 다루는 방법을 터득할 수 있었다.
- 데이터간의 상관계수를 분석하고 군집화시켜 분석하는 과정에서 다양한 데이터 분석기법을 배울 수 있었으며 코드를 정리하는 과정에서 효율적인 알고리즘을 생각해볼 수 있었다.
- 편리한 프로그램 개발을 위해 사용자의 니즈를 생각해보고 사용자의 입장에서 서비스 시나리오를 기획해보며 좋은 소프트웨어 서비스에 대해 생각하는 계기가 되었다.
- 효율적인 분석모델을 설정하고 수립하는 과정에서 머신러닝 하이퍼파라미터 튜닝 과정을 비롯한 머신러닝의 여러 알고리즘에 대해 배울 수 있었으며 예측 정확도를 높힐 수 있는 방법을 고심해볼 수 있었다.
IV. 작품의 기대효과 및 활용분야
1. 작품의 기대효과
- 각 종목의 투자정보와 관련 뉴스 그리고 여러 지표를 기준으로 하여 상위 종목 정보를 제공하여 사용자가 매매전략을 세울 수 있도록 하는 기존 서비스와는 달리 사용자가 가장 집중적으로 보는 상위 기업 지표, 각 종목의 투자정보와 더불어 주가예측 서비스를 도입하여 매매전략 수립에 여러 시각의 도움을 줄 수 있다.
종목에 따라 해당 종목에 보다 효율적인 예측모델을 사용하여 타 주가 예측 프로그램보다 더 높은 예측 정확성을 기대할 수 있다.
2. 작품의 활용분야
- 주식 매매 서비스 : 객관적 지표 외에 사용자가 선택적으로 열람할 수 있는 추가적인 정보로 주가 예측 결과를 보여줄 수 있다. 이를 통해 주식 매매에 어려움을 느끼는 사람들의 매매전략 수립에 도움을 줄 수 있으며 해당 주식 매매 서비스 이용률을 증대시킬 수 있다.
'프로젝트·연구 > 프로젝트·연구' 카테고리의 다른 글
| [데캡디] 뇌파 신호 데이터(EEG) 감성분석을 통한 감성 맞춤형 음악 작곡 시스템 개발(0. 자료조사) (0) | 2021.09.22 |
|---|---|
| 빅데이터를 이용한 주식가격 예측 시스템 만들기 (4. 모델구상추가) (0) | 2021.09.13 |
| 빅데이터를 이용한 댓글 분석 및 시각화, 댓글대시 서비스(2. 수행계획+1차보고서) (0) | 2021.08.30 |
| 빅데이터를 이용한 댓글 분석 및 시각화, 댓글대시 서비스(1. 개발설계) (0) | 2021.07.29 |
| 빅데이터를 이용한 댓글 분석 및 시각화, 댓글대시 서비스(0. 글을 올리기 전에) (0) | 2021.07.29 |